DeepSeek引爆 AI,国产 GPU 集体撑腰

近日,想必诸多用户都怀揣着这样的疑惑:我的手机为何频频推送关于 DeepSeek 的资讯?这 DeepSeek 究竟是什么?它又为何能在问世之际,就引发如此热烈的关注与轰动?
本文引用地址:https://www.eepw.com.cn/article/202502/466733.htmDeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,其起源于一家中国的对冲基金公司 High-Flyer。2023 年 5 月 High-Flyer 剥离出一个独立实体,也就是 DeepSeek。这是一家致力于打造高性能、低成本的 AI 模型。它的目标是让 AI 技术更加普惠,让更多人能够用上强大的 AI 工具。
DeepSeek-V3 与 DeepSeek-R1 的核心差异
去年 12 月 26 日,DeepSeek AI 正式发布了其最新的大型语言模型 DeepSeek-V3。这款开源模型采用了高达 6710 亿参数的 MoE 架构,每秒能够处理 60 个 token,比 V2 快了 3 倍。一经发布,就在 AI 领域引起了轩然大波。
时隔不足一个月,在今年 1 月 20 日,深度求索又正式发布推理大模型 DeepSeek-R1。DeepSeek-R1 的发布,再次震撼业界!
1 月 27 日,DeepSeek 应用登顶苹果中国区和美国区应用商店免费 App 下载排行榜。1 月 31 日,英伟达、亚马逊和微软这三家美国科技巨头,在同一天宣布接入 DeepSeek-R1。
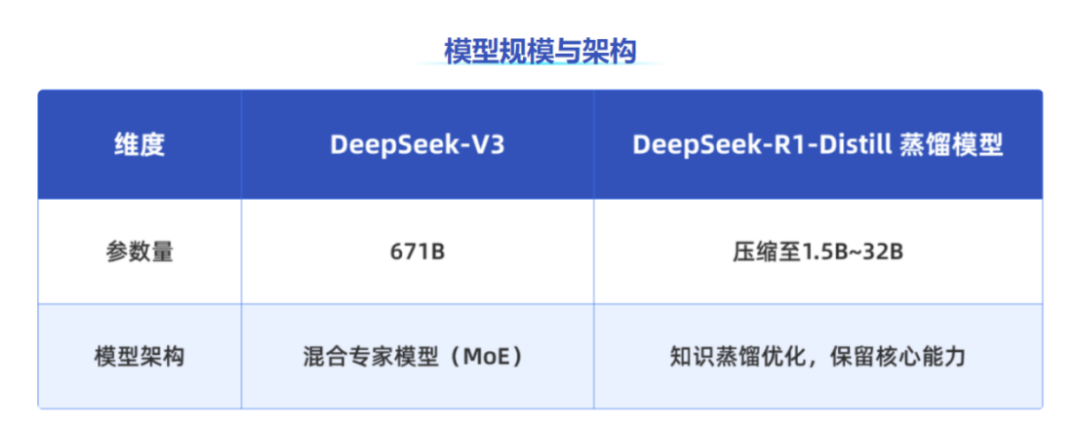
关于 DeepSeek-V3 与 DeepSeek-R1-Distill 蒸馏模型的区别:
DeepSeek-V3
适合复杂任务处理和高精度场景,如长文档分析、多模态推理、科研计算等。
支持千卡级训练,满足超大规模集群分布式训练需求。
DeepSeek-R1-Distill 蒸馏模型
适合轻量级部署和资源受限场景,如边缘设备推理、中小企业快速验证 AI 应用。
在显存和算力要求上更为灵活,适配入门级硬件。
来源:Gitee AI
近日,硅谷顶尖风险投资家、a16Z 联合创始人 Marc Andreessen 发文引用 SensorTower 数据:目前 DeepSeek 日活用户数已经达到了 ChatGPT 的 23%,并且应用每日下载量接近 500 万。
2 月 5 日,京东云宣布正式上线 DeepSeek-R1 和 DeepSeek-V3 模型,支持公有云在线部署、专混私有化实例部署两种模式。前几日,阿里云、百度智能云、华为云、腾讯云、火山引擎、天翼云已接入了 DeepSeek 模型。海外的亚马逊 AWS、微软 Azure 等云巨头同样官宣支持。
那么,DeepSeek 究竟是以何种独特魅力,赢得了广大用户的青睐与喜爱呢?
DeepSeek 的两大优势
市场热捧的产品,往往有个显著共性:能帮用户降本增效。这,同样是 DeepSeek 的优势所在。
首先在低成本与高效能方面,DeepSeek-V3 的训练成本仅为 557.6 万美元(约为 GPT-4 的二十分之一),却能在逻辑推理、代码生成等任务中达到与 GPT-4o、Claude-3.5-Sonnet 相近的性能,甚至超越部分开源模型(如 Llama-3.1-405B)。其技术核心在于算法优化(如 MoE 架构、动态学习率调度器)和数据效率提升,而非依赖算力堆叠。
作为对比,GPT-5 一次为期 6 个月的训练仅计算成本就高达约 5 亿美元。
其次,开源与灵活部署也是 DeepSeek 的突出优势之一。DeepSeek 选择将模型权重开源,并公开训练细节,这为全球的 AI 研究者打开了一扇通往模型内部的大门,让他们能够深入了解模型的训练过程、所采用的算法以及遇到的问题和解决方案。
360 集团创始人周鸿祎指出,DeepSeek 真正践行了开放的精神。与 OpenAI 等关闭模式平台相比,DeepSeek 允许开发者利用其开源模型进行技术挖掘和创新,这是对技术共享理念的有力支持。OpenAI 虽然以「开源」自居,但随着商业化的推进,越来越多地选择封闭式策略,这与其创立初衷背道而驰。
此外,周鸿祎特别提到 DeepSeek 的模型蒸馏技术,他认为这是一种极具前瞻性的实践。在他看来,DeepSeek 对模型蒸馏的开放态度,展示了其自信与无私。相较之下,OpenAI 对用户蒸馏其模型的限制,显示出其对竞争对手的排斥和对自身优势的维护。
DeepSeek 所需的 GPU,主要来源于英伟达
早期对 AI 技术和硬件基础设施的战略投资,为 DeepSeek 的成功奠定了基础。
据 SemiAnalysis 评估,DeepSeek 拥有大约 50,000 个 Hopper 架构的 GPU,其中包括 10,000 个 H800 和 10,000 个 H100 型号。此外,他们还订购了大量的 H20 型号 GPU,这些 GPU 专为中国市场设计。尽管 H800 与 H100 具有相同的计算能力,但其网络带宽较低。H20 是当前唯一对中国模型提供商可用的型号。这些 GPU 不仅用于 DeepSeek,也服务于 High-Flyer,地理上分散部署,支持交易、推理、训练和研究等多种任务。
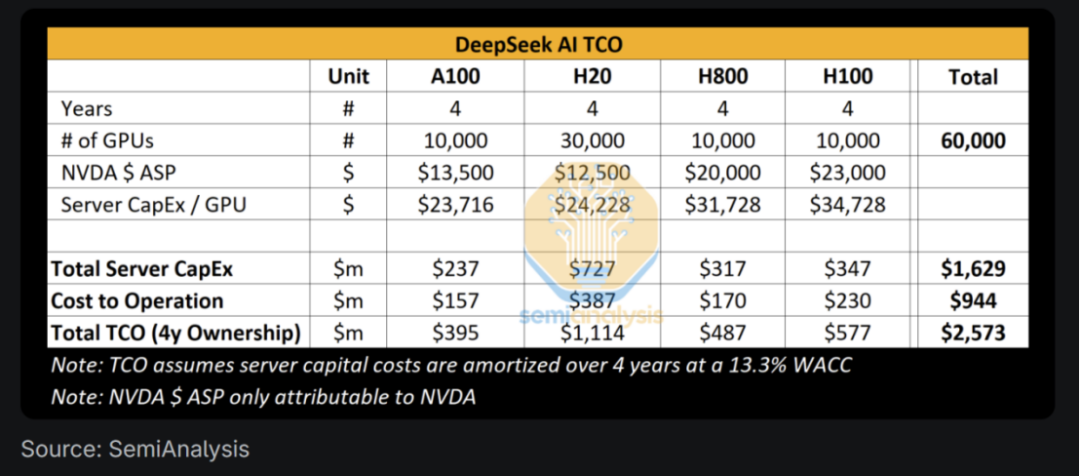
至于 DeepSeek 如何获得如此多数量的 Hopper GPU。
早在 2021 年 High-Flyer 就看好 AI 的发展潜力并果断投资购买了 10,000 个 A100 GPU,用于大规模模型训练实验。这项战略决策后来被证明是非常成功的,为公司带来了显著的竞争优势。
在 1 月 25 日新年前,AMD 就官宣将 DeepSeek-V3 模型集成到了 Instinct MI300X GPU 上。
随后在 1 月 31 日,AI 芯片龙头英伟达也官宣其 NVIDIA NIM 微服务预览版对于 DeepSeek-R1 模型的支持。NIM 微服务基于 HGX H200 系统,每秒能够处理 3872 个 tokens。开发者们可以调用 API 进行测试和试验,该 API 后续会作为英伟达 AI 企业软件平台的一部分提供。
同日,英特尔宣布 DeepSeek 能够在搭载酷睿处理器的 AI PC 上离线使用。在酷睿 Ultra 200H(Arrow Lake H)平台上,DeepSeek-R1-1.5B 模型能够本地离线运行,做翻译、做会议纪要、进行文档撰写等任务。
要知道 DeepSeek 在算力芯片受限的不利因素下,达到 OpenAI 等顶级模型的水平,是国内 AI 生态级的突破。如今,随着 DeepSeek 这类模型的发展,对 GPU 需求持续攀升。国产 GPU 厂商也敏锐捕捉到这一机遇,正在积极进行适配工作。他们深知,适配成功不仅能助力 DeepSeek 等模型更好地发展,也能为自身打开更广阔的市场空间,提升国产 GPU 在 AI 领域的影响力。
11 大国产 AI 芯片公司,宣布适配 DeepSeek
仅在 2 月 1 日至 2 月 7 日这短短 7 天内,就有 11 家国产 AI 芯片公司宣布完成对 DeepSeek 的适配。
DeepSeek 系列新模型正式上线昇腾社区
2 月 1 日,华为云宣布与硅基流动联合首发并上线基于华为云昇腾云服务的 DeepSeek R1/V3 推理服务。得益于自研推理加速引擎加持,该服务支持部署的 DeepSeek 模型可获得持平全球高端 GPU 部署模型的效果。
2 月 5 日,华为宣布,DeepSeek-R1、DeepSeek-V3、DeepSeek-V2、Janus-Pro 于 2 月 4 日正式上线昇腾社区,支持一键获取 DeepSeek 系列模型,支持昇腾硬件平台上开箱即用,推理快速部署,带来更快、更高效、更便捷的 AI 开发和应用体验。
摩尔线程实现对 DeepSeek 蒸馏模型推理服务的高效部署
2 月 4 日,摩尔线程发文称已快速实现对 DeepSeek 蒸馏模型推理服务的高效部署,旨在赋能更多开发者基于摩尔线程全功能 GPU 进行 AI 应用创新。

此外,用户也可以基于 MTT S80 和 MTT S4000 进行 DeepSeek-R1 蒸馏模型的推理部署。
通过 DeepSeek 提供的蒸馏模型,能够将大规模模型的能力迁移至更小、更高效的版本,在国产 GPU 上实现高性能推理。摩尔线程基于自研全功能 GPU,通过开源与自研双引擎方案,快速实现了对 DeepSeek 蒸馏模型的推理服务部署,为用户和社区提供高质量服务。
DeepSeek V3 和 R1 模型完成海光 DCU 适配并正式上线
2 月 4 日晚间,海光信息宣布公司技术团队成功完成 DeepSeek V3 和 R1 模型与海光 DCU(深度计算单元)的适配,并正式上线。
DeepSeek V3 和 R1 模型采用了 Multi-Head Latent Attention(MLA)、DeepSeekMoE、多令牌预测、FP8 混合精度训练等创新技术,显著提升了模型的训练效率和推理性能。
DCU 是海光信息推出的高性能 GPGPU 架构 AI 加速卡,致力于为行业客户提供自主可控的全精度通用 AI 加速计算解决方案。凭借卓越的算力性能和完备的软件生态,DCU 已在科教、金融、医疗、政务、智算中心等多个领域实现规模化应用。
随着海光等专注于 GPU 研发的公司纷纷表示已完成对 DeepSeek V3 的适配。从这一现象来看,DeepSeek 模型在业界或许正逐渐获得较高的认可度与通用性。
那么,海光 DCU 的哪些硬件特性和架构设计使得它能够很好地支持 DeepSeek V3 和 R1 模型的高效运行?
有业内人士表示,海光 DCU 采用了 GPGPU 架构,从而保证在面对新型应用的时候具备极好的兼容性与适配性;同时 DCU 配套的软件栈也经过了多年的积累,相应软件生态成熟丰富,在与新模型、应用适配的时候具备完备的软件支撑能力。以上共同保障了对于 DeepSeek V3/R1 为代表的新模型能够提供高效的兼容与支撑能力。
值得注意的是,海光本次适配并没有用到额外的中间层工具,依托现有 DCU 软件栈就可以实现快速的支撑。这主要得益于 DCU 的 GPGPU 架构通用性和自身对主流生态的良好兼容,从而大幅提升了大模型等人工智能应用的部署效率。
天数智芯联合 Gitee AI 正式上线 DeepSeek R1 模型服务
2 月 4 日,天数智芯与 Gitee AI 联合发布消息,在双方的高效协作下,仅用时一天,便成功完成了与 DeepSeek R1 的适配工作,并且已正式上线多款大模型服务,其中包括 DeepSeek R1-Distill-Qwen-1.5B、DeepSeek R1-Distill-Qwen-7B、DeepSeek R1-Distill-Qwen-14B 等。
Gitee AI 与沐曦携手首发 DeepSeek R1 系列千问蒸馏模型
2 月 2 日,Gitee AI 正式推出了四个轻量级版本的 DeepSeek 模型,分别为 DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B 和 DeepSeek-R1-Distill-Qwen-32B。尤为引人注目的是,这些模型均部署在国产沐曦曦云 GPU 上。
上文曾提到,与全尺寸 DeepSeek 模型相比,较小尺寸的 DeepSeek 蒸馏版本模型更适合企业内部实施部署,可以降低落地成本。
同时,这次 Deepseek R1 模型 + 沐曦曦云 GPU + Gitee AI 平台,更是实现了从芯片到平台,从算力到模型全国产研发。

随后在 2 月 5 日 Gitee AI 宣布再次将 DeepSeek-V3 满血版(671B)上线到平台上(满血版目前仅供大家体验用途)。这也是 Gitee AI 继全套千问蒸馏模型上线沐曦 GPU 卡之后的又一大的更新。
壁仞 AI 算力平台上线 DeepSeek R1 蒸馏模型推理服务,支持云端体验
2 月 5 日,壁仞科技宣布,凭借自主研发的壁砺系列 GPU 产品出色的兼容性能,只用数个小时,就完成对 DeepSeek R1 全系列蒸馏模型的支持,涵盖从 1.5B 到 70B 各等级参数版本,包括 LLaMA 蒸馏模型和千问蒸馏模型。
目前,壁仞科技已构建起从底层硬件到模型服务的完整 AI 技术栈,可为中小企业和研究机构提供「芯片+模型」的端到端解决方案。
云天励飞 DeepEdge10 已完成 DeepSeek R1 系列模型适配
2 月 5 日,云天励飞宣布,其芯片团队完成 DeepEdge10「算力积木」芯片平台与 DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B 大模型的适配,可以交付客户使用。DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B 大模型、DeepSeek V3/R1 671B MoE 大模型也在有序适配中。适配完成后,DeepEdge10 芯片平台将在端、边、云全面支持 DeepSeek 全系列模型。

DeepEdge10 系列芯片是专门针对大模型时代打造的芯片,支持包括 Transformer 模型、BEV 模型、CV 大模型、LLM 大模型等各类不同架构的主流模型;基于自主可控的先进国产工艺打造,采用独特的「算力积木」架构,可灵活满足不同场景对算力的需求,为大模型推理提供强大动力。
基于太初 T100 加速卡 2 小时适配 DeepSeek-R1 系列模型
2 月 5 日,太初元碁 Tecorigin 表示,基于通用的异构众核芯片架构和深厚的软件生态积累,在太初 T100 加速卡上仅用 2 小时便完成 DeepSeek-R1 系列模型的适配工作,快速上线包括 DeepSeek-R1-Distill-Qwen-7B 在内的多款大模型服务,为人工智能应用的创新发展提供了强有力的技术支撑和自动可控的算力设施保障。
目前,太初元碁正积极携手京算、是石科技、神威数智、龙芯中科等合作伙伴,全力打造 DeepSeek 系列模型的云端推理平台。企业用户只需通过简单的操作,即可在云端快速获取太初 T100 加速卡的强大推理能力,轻松实现智能化转型,提升生产效率和创新能力,以在激烈的市场竞争中脱颖而出。同时,太初元碁也联合龙芯中科提供面向政务信创的国密云端推理平台,以满足信创刚需。
燧原科技实现全国各地智算中心 DeepSeek 的全量推理服务部署
2 月 6 日,燧原科技宣布完成对 DeepSeek 全量模型的高效适配,包括 DeepSeek-R1/V3 671B 原生模型、DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek R1-Distill-Llama-8B/70B 等蒸馏模型。整个适配进程中,燧原 AI 加速卡的计算能力得到充分利用,能够快速处理海量数据,同时其稳定性为模型的持续优化和大规模部署提供了坚实的基础。
目前,DeepSeek 的全量模型已在庆阳、无锡、成都等智算中心完成了数万卡的快速部署,将为客户及合作伙伴提供高性能计算资源,提升模型推理效率,同时降低使用门槛,大幅节省硬件成本。
昆仑芯全面适配 DeepSeek
2 月 6 日,昆仑芯科技宣布,在 DeepSeek-V3/R1 上线不久,昆仑芯便率先完成全版本模型适配,这其中包括 DeepSeek MoE 模型及其蒸馏的 Llama/Qwen 等小规模 dense 模型。
昆仑芯 P800 可以较好的支撑 DeepSeek 系列 MoE 模型大规模训练任务,全面支持 MLA、多专家并行等特性,仅需 32 台即可支持模型全参训练,高效完成模型持续训练和微调。
P800 显存规格优于同类主流 GPU20%-50%,对 MoE 架构更加友好,且率先支持 8bit 推理,单机 8 卡即可运行 671B 模型。正因如此,昆仑芯相较同类产品更加易于部署,同时可显著降低运行成本,轻松完成 DeepSeek-V3/R1 全版本推理任务。
龙芯处理器成功运行 DeepSeek 大模型
2 月 7 日,龙芯中科宣布,日前,龙芯联合太初元碁等产业伙伴,仅用 2 小时即在太初 T100 加速卡上完成 DeepSeek-R1 系列模型的适配工作,快速上线包含 DeepSeek-R1-Distill-Qwen-7B 在内的多款大模型服务。
此外,采用龙芯 3A6000 处理器的诚迈信创电脑和望龙电脑已实现本地部署 DeepSeek,部署后无需依赖云端服务器,避免了因网络波动或服务器过载导致的服务中断,可高效完成文档处理、数据分析、内容创作等多项工作,显著提升工作效率。
DeepSeek 给国产芯片公司,带来新契机
DeepSeek 的横空出世宛如一颗投入平静湖面的石子,在行业中激起层层涟漪,为国产芯片公司带来新的发展契机。
首先,随着大模型应用的遍地开花,对芯片的需求也水涨船高。无论是模型训练时所需的强大算力,还是推理过程中对低延迟、高效率的追求,都为国产芯片公司打开了新的市场空间。以往,由于高昂的大模型使用成本,许多潜在的应用场景被抑制,如今 DeepSeek 打破了这一僵局,国产芯片公司得以凭借自身产品在新兴的细分市场中崭露头角,满足不同行业对于大模型运算的芯片需求。
其次,DeepSeek 大模型与国产 AI 芯片适配的逐步成熟,是另一个关键契机。此前,国产 AI 芯片在发展过程中,常面临与主流大模型适配度不佳的问题,这限制了其市场推广与应用拓展。而 DeepSeek 的出现改变了这一局面,它为国产 AI 芯片提供了一个更为契合的适配平台。
当国产 AI 芯片能够与 DeepSeek 大模型良好适配后,可以加快国产 AI 芯片在国内大模型训练端和推理端的应用,使得国产芯片在本土市场中获得更多实践机会,通过不断优化和改进,提升产品性能。
最后,随着 DeepSeek 与国产芯片的适配,将与其他国产软硬件厂商形成协同效应,构建起完整的生态闭环,这将推动国产芯片在人工智能领域的应用,加速国产芯片生态体系的建设。

评论