网络虚拟化和网络包处理

网络虚拟化基于网络包处理流水线实现,常见的网络包处理流水线有三种:定制的流水线、可软件编程的流水线以及通过FPGA实现的硬件可编程流水线。
本文引用地址:https://www.eepw.com.cn/article/202402/455371.htm1 包处理用于网络虚拟化
网络包处理机制可以用来处理各种不同的网络协议,特别是一些可软件编程的处理引擎的出现,使得增加新的网络协议处理更加的灵活简单。通用的网络包处理机制,也适用于网络虚拟化VLAN/VxLAN的处理。
1.1 虚拟网络,狭义的网络虚拟化
网络虚拟化通常指通过VLAN、VxLAN、NVGRE等虚拟网络相关的协议,在一个大的物理网络的基础上,灵活构建不同的虚拟网络域,也可以通过一定的机制,实现在不同虚拟网络域间的跨域访问。虚拟网络不是在初始构建的那一刻配置完成就结束,而是在网络运行过程中,每条流、每个包都需要经过虚拟网络协议的处理。随着网络带宽的持续增加,为了优化虚拟网络的性能以及CPU资源消耗,势必需要通过硬件加速的方式来实现更高性能的虚拟网络处理。
虚拟网络基于物理网络实现,如图1,以VxLAN为例,最核心的处理是通过VNID和内部目标地址作为关键字,在查找表中查询到对应的外部目标地址。而内部目标地址和外部目标地址的映射关系处理则交给软件去完成,可以实现跟现有的软件虚拟网络系统兼容,支持更加动态且灵活的虚拟网络设计,实现硬件的高效和软件的灵活兼顾。

图1 VxLAN Tx项虚拟化映射
1.2 广义的网络虚拟化
除了虚拟网络场景,还有一些网络场景具有虚拟化的特征:比如负载均衡,通过把数量众多的后端服务器虚拟成一台强大的服务器来提供服务;再比如NAT,内网服务器可以通过一个公网IP访问互联网,站在内网服务器的角度,可以看作是把一个公网访问IP虚拟化成多个公网访问IP。
更广泛的,网络是分层的体系,每一层从下一层的接口获取服务、然后实现本层的功能,再把本层的功能封装成新的接口,通过接口提供服务给上一层。站在整个网络系统的角度,网络的每一层都可以看作是一层虚拟化封装,为上一层提供新的服务接口。
硬件实现的网络包处理架构,可以支持很多不同类型的网络协议。特别是数据面可编程的网络包处理架构,不需要预先把可能要支持的协议都实现,只需要根据自己的场景需要,编程实现特定的若干个协议就好。数据面可编程的网络包处理可以非常方便的支持特定场景应用,实现高效的网络虚拟化硬件加速处理。
2 定制的网络包处理
传统的ASIC实现的定制网络协议处理流水线,在设计的开始,需要确定场景以及支持的协议,理论上可以实现最高的网络包处理性能。
如图2,是一个定制的网络包处理流水线,每个阶段都是固定的功能,支持的是特定协议的处理,想更新新的协议需要重新设计新的芯片,因此对新协议的支持非常困难。
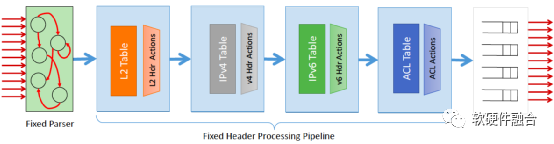
图2 定制协议网络包处理流水线示例
如图3,IETF(Internet Engineering Task Force,互联网工程任务组)的RFC(Request for Comments,请求意见稿,即网络协议)数量一直在爆炸式的增长,应用于各种新型网络场景的新协议层出不穷。但是,传统的网络处理芯片都是封闭的、特定的设计,用于特定协议处理。想要增加新的协议非常困难,并且对新协议的支持受到不同供应商的约束。定制的网络处理芯片,对新协议的支持不足以及缺乏有效的灵活性,这使得要想在网络系统增加新的功能非常困难,限制了客户的网络创新能力。
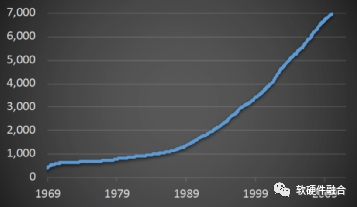
图3 IETF RFC的数量增长
3 ASIC软件可编程包处理
本节通过数据面编程的背景知识、RMT模型以及流水线映射三个方面介绍可软件编程的ASIC包处理流水线。
3.1 数据面编程的网络包处理流水线
Nick McKeown 在 ONF Connect 2019演讲中定义了SDN发展的三个阶段:
第一阶段(2010–2020年):通过Openflow将控制面和数据面分离,用户可以通过集中的控制端去控制每个交换机的行为;
第二阶段(2015–2025年):通过P4编程语言以及可编程FPGA或ASIC实现数据面可编程,这样,在包处理流水线加入一个新协议的支持,开发周期从数年降低到数周;
第三阶段(2020–2030年):展望未来,网卡、交换机以及协议栈均可编程,整个网络成为一个可编程平台。
这预示着,未来不管是交换机侧还是网卡侧,均需要实现类似CPU于通用程序设计的完全可编程的网络处理引擎,并且要基于此平台实现一整套的软件堆栈。把一个完全可编程的网络交给用户,支撑用户更快速的网络创新。
图4中介绍的PISA(Protocol Independent Switch Architecture,协议无关的交换架构),是一种支持P4数据面可编程包处理的流水线引擎架构,通过可编程的解析器、多阶段的可编程的匹配动作以及可编程的逆解析器组成的流水线,来实现数据面的编程。这样可以通过编写P4程序,下载到处理器流水线,可以非常方便的支持新协议的处理。
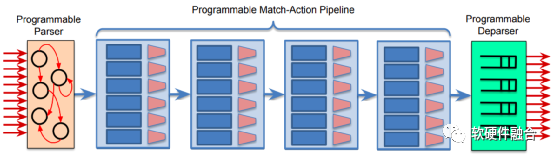
图4 PISA的数据面可编程网络包处理流水线
3.2 可重配置的匹配表模型
RMT(Re-Configurable Match-Action Tables,可重配置匹配表)模型,是一种基于RISC的用于网络包处理的流水线架构。RMT允许自定义数量的包头和包头序列,通过自定义大小的匹配表对字段进行任意匹配,对数据包包头字段进行自定义的写入,以及数据包的状态更新。RMT允许在不更改硬件的情况下在现场更改网络数据面, PISA架构从RMT模型中获得了很多的设计灵感。
如图5所示,是包处理流水线核心处理“匹配动作”阶段的内部架构。每个匹配阶段都允许配置匹配表的大小,例如,对于IP转发,可能需要一个256K 32位前缀的匹配表;输入选择器选择要匹配的字段;数据包修改使用VLIW(Very Long Instruction Word,超长指令字,一种比较特殊的CPU架构实现)架构的ALU动作单元,该指令字可以同时对包头向量中的所有字段进行操作。
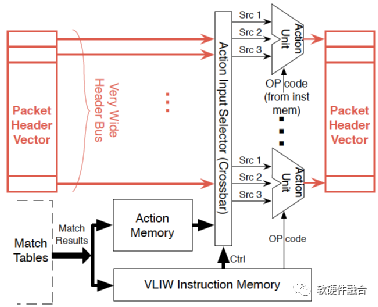
图5 匹配动作的架构
如图6,RMT定义了一个可编程的解析器。解析器输入的是数据包数据,输出4K位的数据包头向量。输入的包头数据和解析状态信息不断的送到TCAM去查询,TCAM查询会触发动作,这个动作会更新状态机,并把结果送到字段提取处理,提取出的字段组成数据包字段向量输出。
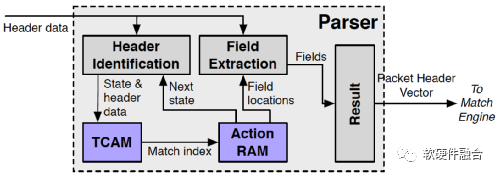
图6 可编程的解析器模型
3.3 映射处理程序到包处理流水线
当实现了完全可编程的流水线之后,在P4工具链的支持下,就可以通过P4编程的方式来实现自定义的流水线,来达到对自定义协议的支持。
如图7所示,P4定义的Parser程序会被映射到可编程的解析器,数据、包头定义、表以及控制流会被映射到多个匹配动作阶段。图7中把L2处理、IPv4处理、IPv6处理以及访问控制处理分别映射到不同的匹配动作处理单元进行串行或并行的处理,来实现完整的支持各种协议的网络包处理。
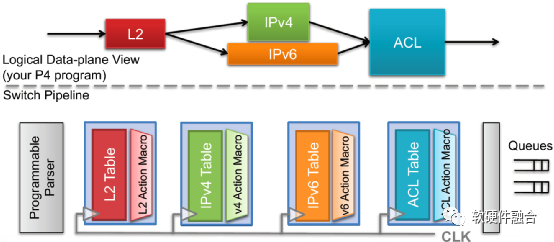
图7 基于PISA流水线的数据包处理示例
4 FPGA硬件可编程包处理
Xilinx在2014年推出SDNet(Software Defined Specification Environment for Networking,软件定义网络规范环境)解决方案,将可编程能力和智能化功能从控制面扩展至数据面。SDNet支持可编程数据层功能设计,其功能规范可自动编译到赛灵思的FPGA和SoC中。
如图8, Xilinx的SDNet可以通过编程实现数据面代码的自动生成,可以支持从简单的数据包分类到复杂的数据包编辑的各种数据包处理功能。SDNet支持P4编程,可以通过编写标准的P4程序来实现SDNet的包处理。
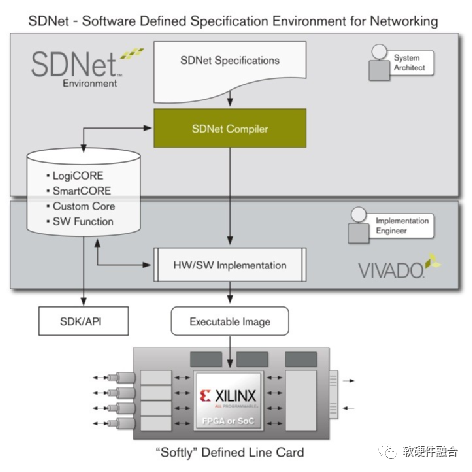
图8 Xilinx SDNet解决方案及开发环境
SDNet是充分利用FPGA器件的硬件可编程性来实现包处理的灵活性的,通过P4实现功能灵活且特定的包处理规则,通过SDNet的编译器,把P4程序生成特定的RTL代码,再经过自动化的FPGA流程处理,把生成的镜像更新到FPGA中。而从设计架构的角度,SDNet的实现机制仍属于定制的网络包处理流水线,其解析器、编辑器以及查找动作等处理都是针对特定的包的处理,支持的是特定的(标准的或用户自定义的)网络协议。
SDNet基于模块化设计,包括各种不同类型引擎以及引擎之间的连接接口。这些引擎通过与数据包和元组通信,以实现更大的系统行为。执行模型是被动的,基于同步数据流模型,当所有输入到达时触发引擎工作。输入可以是数据包以及相应的作为元组通信的元数据。
SDNet数据流模型的端口有:
数据包。数据包端口是SDNet主要的接口,负责在引擎之间以及外部环境传递数据包。
元组。元组端口是辅助的SDNet接口,负责引擎之间以及与外部环境传递与数据包相关的元数据。
访问。SDNet中的访问端口由编译器在后台连接,并在在数据流模型中进行了说明。SDNet规范并未明确实例化或连接这些端口,它们由编译器自动连接。
自定义格式。SDNet中的自定义格式端口用于,上述三种类型无法涵盖的,与用户引擎之间的通信接口。
SDNet通过分层的系统构建,包含各种不同类型引擎:
解析引擎。用于读取和解码数据包头,并提取所需的信息用于分类或之后的数据包修改。解析引擎只能读取数据包,而不能修改它们。可以对从数据包提取的数据执行计算,并将数据作为输出元组传输。
编辑引擎。用于处理数据包。编辑引擎无法直接从总线读取数据包,但可以写入数据包路径,用于插入、替换或移除数据包。以从分组中插入,替换或删除数据。
元组引擎。主要用于处理元组并基于元组数据计算新的元组信息,这些元组数据可能由外部或其他引擎输出的数据包或数据确定。
查找引擎。实现对各种不同类型表的搜索。SDNet包含一个具有不同查找引擎类型的小型库,包含四种类型:EM(Exact Match,完全匹配)、LPM(Longest Prefix Match最长前缀匹配)、TCAM(Ternary Content Addressable Memory,三态按内容寻址内存)或直接地址查找(RAM)。
用户引擎。允许用户将自定义IP内核导入SDNet规范,以利用SDNet框架进行数据平面构建和系统仿真。在SDNet中,用户引擎只定义引擎的接口,但不定义引擎的行为。用户引擎必须符合SDNet数据流模型的同步数据流行为。
系统。在SDNet模型中,系统被视为一种引擎。根据引擎的匹配端口类型,系统将引擎连接在一起。系统只能包含一个数据包输入端口和一个数据包输出端口。系统只允许元组输出,不允许元组输入。系统还可以具有用于连接子系统或用户引擎的自定义端口。子系统是在父SDNet系统中例化的另一个SDNet系统。
5 案例:Mellanox FlexFlow
高性能的以太网交换机是现代数据中心的网络核心,不断变化的虚拟化和能自我修复的网络架构,都要求交换机具有动态的编程功能。Mellanox FlexFlow使得交换机支持用户自定义功能,FlexFlow具有非常好的可编程能力以及灵活性,支持大规模并行数据包处理以及完全共享的有状态的转发数据库。
如图9,Mellanox FlexFlow的包处理流水线跟传统交换机的包处理流水线相比:
传统的包处理流水线具有严格的流水线功能约束;而FlexFlow具有可编程的解析器、编辑器以及可编程的流水线。
传统包处理流水线所有的流量是串行的处理;而FlexFlow支持大量的并行以确保最大吞吐。
因为串行,传统的包处理流水线具有很高的延迟;而FlexFlow针对每个流进行优化,确保更低的延迟。
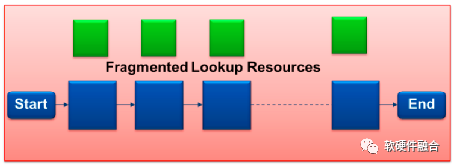
传统的包处理流水线采用分散的查找表资源,更低的扩展性但更高的功耗;而FlexFlow共享查找表资源,因此具有更高的扩展性以及更低的功耗。
(a) 传统交换机流水线
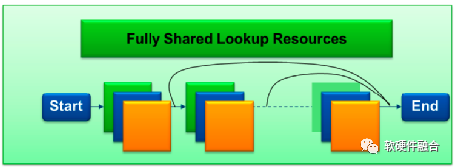
(b) Mellanox FlexFlow流水线
图9 传统的交换机流水线和FlexFlow比较
FlexFlow具有如下典型特征:
深度的包解析。解析器是数据包处理流水线的第一个阶段。该阶段负责将输入的数据翻译成有意义的数据包头字段,这些字段会被用于转发、策略实施和QoS。FlexFlow支持可编程的数据包处理,可以解析多达512B的数据包。更大的解析深度和自定义支持的数据包格式,数据包处理流水线可以支持更丰富的隧道传输、更先进的遥测,同时还可以支持新的网络协议。
灵活的特定于流的查找表。FlexFlow可编程流水线可以定义查找表数量,可以以流为单位配置查找关键字。查找动作包括标准的转发、策略行为以及指向下一个查找表的指针。可以在每一条流的粒度,定制表的数量、查找的序列、匹配关键字和动作。基于流粒度的查找序列,数据包处理可以多次访问同一张表。基于流粒度的查找序列,FlexFlow可以在固定的物理网络拓扑中实现灵活多变的网络抽象。
功能强大的隧道。灵活的数据包编辑引擎通过编程添加、修改和删除多层数据包头。FlexFlow支持可编程的封装和解封装、IPv4选项、IPv6扩展以及多种Overlay协议。FlexFlow为未来的隧道和Overlay技术提供了很好的支持,这些技术是未来几年网络虚拟化的根本。
完全共享的查找表。传统的交换机使用碎片化的转发表,这些转发表硬连线到特定的流水线阶段。用于流水线阶段的表的资源和查找表大小都是预先定义好的。在某个特定的流水线阶段中的表资源可能存在浪费。FlexFlow可以实现高效的表共享,可以提供几乎无限的查找表大小的设定,这使得基于FlexFlow的交换机可以支持当前的以及未来的网络协议所需的所有数据包转换。
综合遥测。FlexFlow流水线使用灵活的有状态的流水线阶段,以编程的方式提取元数据并提供实时遥测。随着数据中心网络复杂性日益提升,FlexFlow提供了完全集成的遥测功能,减少了故障时间,增加正常运行时间,更好的优化了网络架构的利用率。
6 网络包处理总结
网络包处理是一个特定的领域,具有非常明显的特征,通过ASIC实现效率最高。有利必有弊,ASIC实现极大的约束了网络的灵活性。上层的网络用户只是一个使用者,只能使用ASIC提供的功能;而不是作为一个开发者,开发创新自己想要的功能。随着这些年来互联网的迅猛发展,新协议层出不穷,甚至有些网络服务商会采用一些私有协议。用户需要极大的网络创新来支撑自己的业务发展,对网络的可管理性、可编程性要求变得越来越高。硬件实现的网络处理加速,势必需要从专用向通用方向适当的回调。
跟通常的硬件加速从通用到专用的趋势不同,网络包处理流水线的实现是反其道而行,走的是从定制到部分可编程的道路。PISA等具有数据面可编程能力的网络包处理流水线很好的实现了通用和专用之间的平衡:
部分可编程性(而不是完全可编程),可以保证单个包处理引擎的性能和效率(跟完全定制的ASIC比较)不受太多影响。
通用的处理引擎降低了硬件的耦合性和复杂度,可以实现更大规模的并行度,反而可以更好的提升性能。
ASIC因为设计门槛的原因,希望尽可能覆盖较多的应用场景,在具体的某个场景中,必然存在无关协议所占用硬件资源所导致的资源浪费的情况;而数据面可编程的设计具有的灵活性,可以更大限度的保证物尽其用,把所有硬件资源都用于场景相关的协议处理,在硬件资源利用率方面,反而高于ASIC。打个比方,某ASIC网络芯片支持100种不同的网络协议处理,但实际应用场景只需要其中的10种协议;在同等晶体管资源占用下,假设数据面可编程的架构只能支持50种网络协议的处理,这样当我们处理10种协议的时候,可以编程实现并行的5路处理,性能反而高于纯ASIC定制的流水线。
提供的软件可编程性,用户可以灵活快速的实现特定场景协议,而不需要关心场景无关的协议,反而降低了软件编程的复杂度。
从整个流水线实现架构来看,基于部分可编程能力的PISA等架构实现的网络包处理芯片是一种DSA架构处理器。




评论