开源深度学习框架对比

本节对5个开源深度学习框架进行对比研究,主要侧重于3个维度研究:硬件支持率、速度和准确率、社区活跃性。他们分别是:TensorFlow、Caffe、Keras、Torch、DL4j 。
本文引用地址:https://www.eepw.com.cn/article/201807/383883.htm2.3.1 硬件支持率
本节研究的硬件利用率指不同开源深度学习框架对于不同CPU/GPU配置下对硬件的支持效率与通用性能表现。
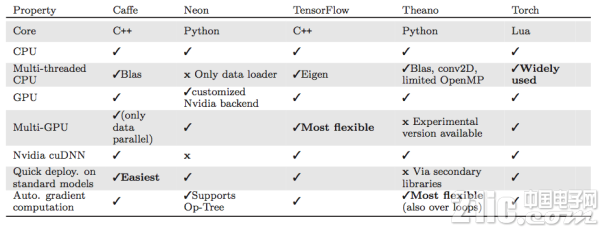
表2.1展示了各框架对于不同硬件的通用支持性能。
2.3.2 速度和准确率
本节将梯度计算时间、前馈传播和反馈传播时间总和度量,不对各项进行细分。且所有试验数据基于CPU。
模型
本节选取全链接神经网络(Fully Connected Neural Network, FCNN)作为深度学习框架速度测试模型。FCNN被视为前馈多层感知网络,意味着网络神经元之间的连接是单向的,不包含环状连接,因此容易获得时间数据。FCNN最主要的用途在于进行数据分类工作,因此适合对不同框架下的准确率进行对比。
数据集
本节选取MNIST手写数字图片集作为FCNN的数据集对不同框架进行测试。MNIST数据集由6000张训练图像集和1000张测试图像集组成,均为28X28像素的手写数字图片。
测试方法
本节目标在于对比测试FCNN类型的神经网络在不同框架上的收敛所耗时间以及预训练网络在不同框架上对于分类结果预测的准确性。主要考察以下方面:1.收敛速度;2.预测耗时;3.分类准确性;4.源代码规模;
为了评估模型的可扩展性,采用不同的扩展性因子来度量上述1-3点。神经网络结构采用两种尺度进行测试:1.使用相同的神经元数来改变网络的“深度”(见图2.10);2.使用相同的层数来改变网络的“宽度”(见图2.11);
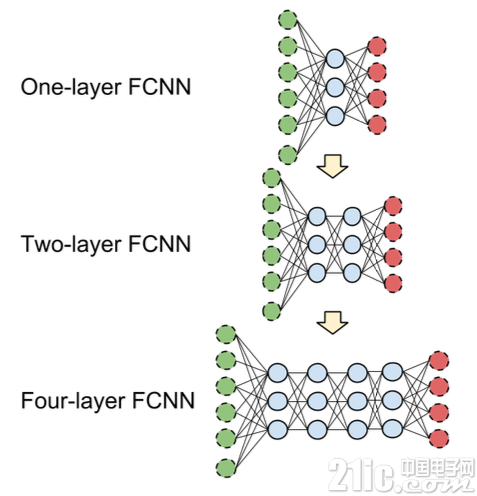
图2.9 “深度”改变了的神经网络

图2.10 “宽度”改变了的神经网络
测试结果
图2.11-图2.14展示了FCNN基于各框架使 用Tanh非线性激活函数的情况下的训练时间、预测时间和分类准确度。所有试验的Epoch设定为10。
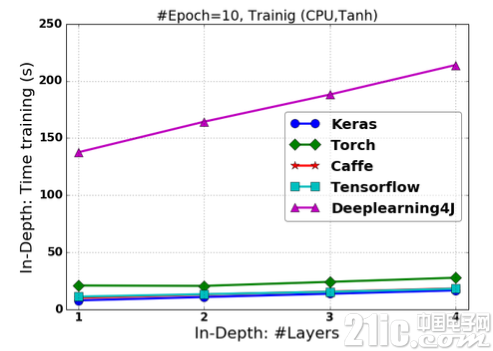
图2.11 基于Tanh激活的FCNN在改变“深度”情况下的训练时间
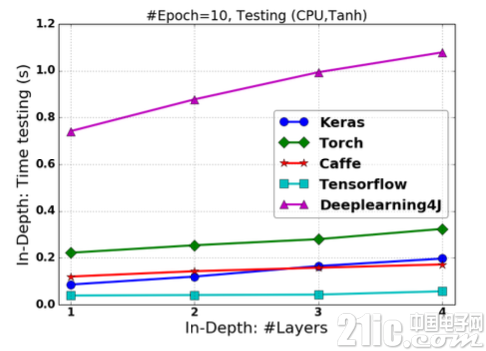
图2.12 基于Tanh激活的FCNN在改变“深度”情况下的预测时间
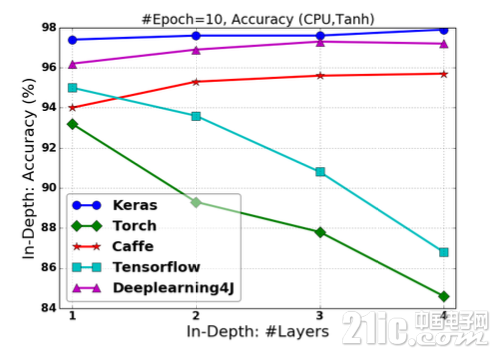
图2.13 基于Tanh激活的FCNN在改变“深度”情况下的分类准确率
类似的,图2.14-图2.16展示了FCNN基于各框架使用ReLU非线形激活函数的情况下的训练时间。
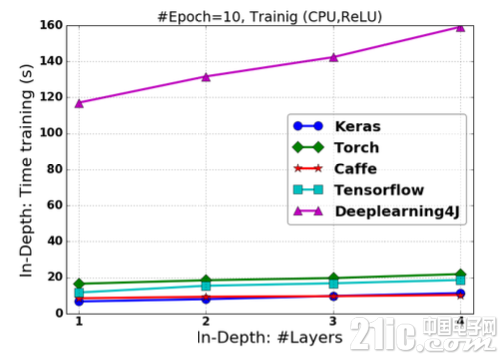
图2.14 基于ReLU激活的FCNN在改变“深度”情况下的训练时间
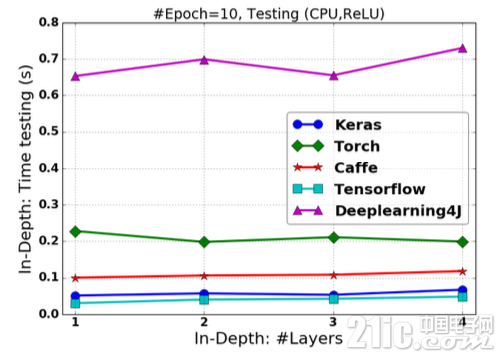
图2.15 基于ReLU激活的FCNN在改变“深度”情况下的预测时间
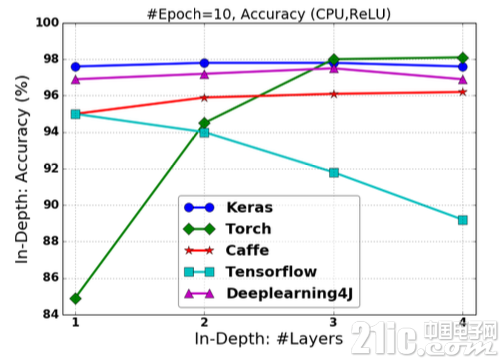
图2.16 基于ReLU激活的FCNN在改变“深度”情况下的分类准确率
下面的试验考察当网络隐含层的尺寸(如神经元个数)如图2.10的方式改变时,FCNN在不同框架上的速度、准确率的变化情况。试验结果分别于图2.17-图2.19种一同样的方式被展示。
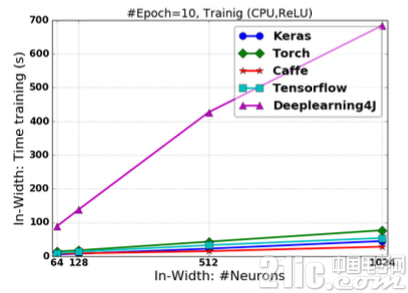
图2.17 基于ReLU激活的FCNN在改变“宽度”情况下的训练时间

图2.18 基于ReLU激活的FCNN在改变“宽度”情况下的预测时间
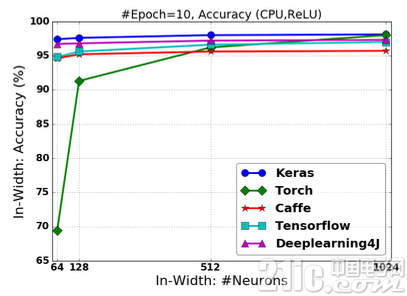
图2.19 基于ReLU激活的FCNN在改变“宽度”情况下的分类准确率
我们结合相关算法实现的代码量与接口语言来衡量深度学习框架的复杂度。各框架的复杂度对比见表2.1和图2.20所示。
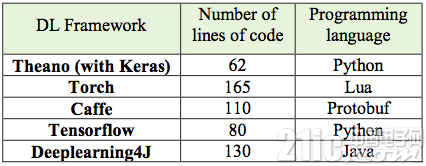
表2.1 各框架的复杂性
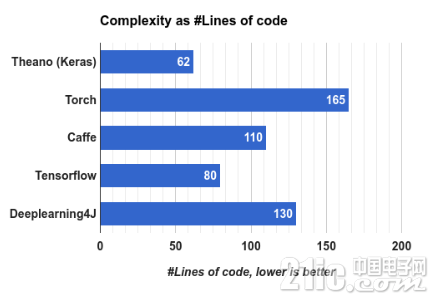
图2.20 复杂性的代码行表现
2.3.3 社区活跃度
速度是衡量源深度学习框架性能的一个重要指标,同时,对各开源深度学习框架的贡献者数量和开源社区的活跃度也同等重要。无论对于学术研究或是工业项目开发与部署,社区活跃度与知识获取与开发成本关系十分密切。
GitHub社区项目的Watch、Star、Fork数量可反映出各深度学习框架的活跃度(如图2.21-2.23所示)。其中Watch反应了各框架的浏览量,Star数量代表社区使用者对框架的点赞数,Fork则指框架被拷贝的数量。
图2.21 GitHub社区各开源深度学习框架的Watch数
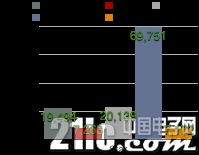
图2.22 GitHub社区各开源深度学习框架的Star数
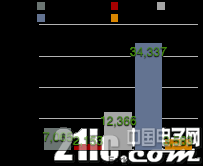
图2.23 GitHub社区各开源深度学习框架的Fork数
当跳出深度学习框架本身,在GitHub检索基于各框架的项目、笔记、讨论时,图2.24-图2.26展示出了基于各框架的项目的活跃情况。
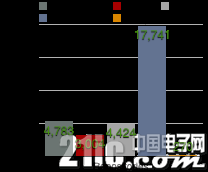
图2.24 GitHub社区基于各开源深度学习框架的repositories
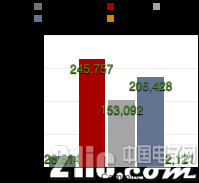
图2.25 GitHub社区基于各开源深度学习框架的Commits
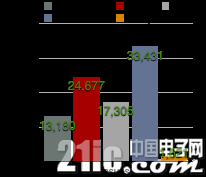
图2.26 GitHub社区基于各开源深度学习框架的Commits
2.3.3 工业表现能力
开源深度学习框架不仅对学术研究提供了有力的支持,同时也为工业界解决任务提供了众多解决方案。本节将从模型表达能力、接口、部署、性能和架构等方面度量各开源框架在工业生产领域的表现。
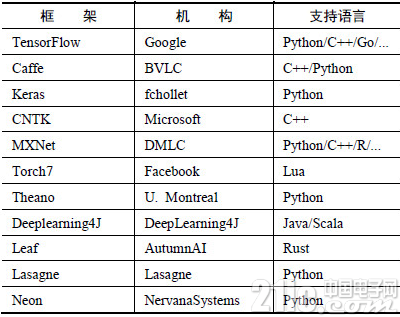
图2.27 各框架支持语言
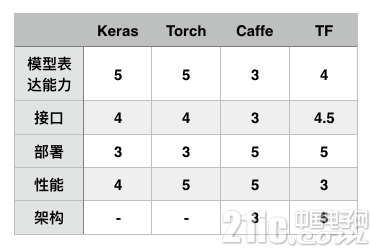
表2.2 各框架工业能力评分(GitHub)
网络和模型能力
Caffe在计算机视觉领域是最流行的工具包,有很多扩展,但对递归网络和语言建模的支持很差。此外,在Caffe中图层需要使用C++定义,而网络则使用Protobuf定义。
TensorFlow是一个理想的RNN API和实现,向量运算的图方法使得新网络的指定变得相当容易,但其并不支持双向RNN和3D卷积,同时公共版本的图定义也不支持循环和条件控制,这使得RNN的实现并不理想,因为必须要使用Python循环且无法进行图编译优化。
Theano支持大部分先进的网络,很多研究想法都来源于Theano,它引领了符号图在编程网络中使用的趋势。Theano的符号API支持循环控制,让RNN的实现更加容易且高效。
Torch对卷积网络的支持非常好,通过时域卷积的本地接口使得它的使用非常直观。Torch通过很多非官方的扩展支持大量的RNN,同时网络的定义方法也有很多种。但Torch本质上是以图层的方式定义网络的,这种粗粒度的方式使得它对新图层类型的扩展缺乏足够的支持。与Caffe相比,在Torch中定义新图层非常容易,不需要使用C++编程,图层和网络定义方式之间的区别最小。
接口
Caffe支持pycaffe接口,但这仅仅是用来辅助命令行接口的,而即便是使用pycaffe也必须使用protobuf定义模型。
TensorFlow支持Python和C++两种类型的接口。用户可以在一个相对丰富的高层环境中做实验并在需要本地代码或低延迟的环境中部署模型。
Theano支持Python接口。
Torch运行在LuaJIT上,与C++、C#以及Java等工业语言相比速度非常快,用户可编写任意类型的计算而不需要担心性能,但Lua并非主流语言。
模型部署
Caffe基于C++,可在多种设备上编译,具有跨平台性,是部署项目的最佳选择。
TensorFlow支持C++接口,同时能够基于ARM架构编译和优化。用户可将成熟模型部署在多种设备上而不需实现单独的模型解码器或者加载Python/LuaJIT解释器。
Theano缺少底层的接口,并且其Python解释器也很低效。
Torch的模型运行需要LuaJIT的支持,对集成造成了很大的障碍。
性能
Caffe 简单快速。
TensorFlow仅使用了cuDNN v2,但即使如此它的性能依然要比同样使用cuDNN v2的Torch要慢1.5倍,并且在批大小为128时训练GoogleNet还出现了内存溢出的问题。
Theano在大型网络上的性能与Torch7不相上下。但其因需要将C/CUDA代码编译成二进制而启动时间过长。此外,Theano的导入也会消耗时间,并且在导入之后无法摆脱预配置的设备。
Torch非常好,没有TensorFlow和Theano的问题。
架构
Caffe的主要劣势是图层需要使用C++定义,而模型需要使用protobuf定义。此外,如果想要支持CPU和GPU,用户还必须实现额外的函数;对于自定义的层类型,还须为其分配id,并将其添加到proto文件中。
TensorFlow的架构清晰,采用了模块化设计,支持多种前端和执行平台。
Theano 的整个代码库都使用Python,连C/CUDA代码也要被打包为Python字符串,这使其难以导航、调试、重构和维护。
Torch7和nn类库拥有清晰的设计和模块化的接口。
2.2.4 结论
1. 各深度学习框架对于硬件的利用情况:
多线程CPU的情况下Torch使用的最广泛;
TensorFlow在多GPU的条件下最为灵活可用;
2. 各深度学习框架对于速度:
在网络“深度”改变的情况下,Keras具有最快的训练速度,TensorFlow具有最快的预测响应速度;
在网络“宽度”改变的情况下,Caffe具有最快的训练速度,TensorFlow在“宽度”改变较小的情况下具有最快的预测响应速度,“宽度”改变较大时Keras具有最快的响应速度,TensorFlow紧随其后;
3. 各深度学习框架对于准确率:
在网络“深度”改变的情况下,TensorFlow和Torch的分类准确率随网络“深度”的增加而下降;
在网络“宽度”改变的情况下,TensorFlow的分类预测准确率相对稳定,超越CaffeTorch;
无论在网络“深度”或是“宽度”改变的情况下,Keras对分类预测的准确率十分稳定,且超越其他框架,具有最佳的预测准确率;
4. 各深度学习框架的社区活跃度:
TensorFlow可以定义为“最流行”、“最被认可”的开源深度学习框架。其在GitHub上无论是Star数、Fork数,或是检索基于TensorFlow的项目数,都大大超过其他框架,甚至超越其他框架资源的总和。
5. 各深度学习框架的工业表达能力:
Caffe具有优秀的模型表达能力和工业部署能力,尤其是计算机视觉方面,但对RNN和语言建模的支持很差。Caffe适用于视觉任务处理,尤其是基于深度学习的工业项目,其具有无可争议的生产稳定性;但其缺乏灵活性,这使得对网络结构的改变比其他框架麻烦,且Caffe的文档十分匮乏,代码阅读困难高于其他框架。
Tensorflow具有很好的模型表达能力、优秀的接口和清晰的内部框架,适用于工业项目部署,但其速度性能不具备优势;TensorFlow支持分布式计算,使得硬件设备的性能得到最充分发挥;其代码的可读性和社区活跃度使得无论是学术研究或工业生产变得容易;
Keras具有良好的速度性能、模型表达能力,使用简洁、方便—只需几行代码就能构建一个神经网络。Keras具有完整的文档,使得学习和使用十分容易—即便不熟悉Python。其更适用于学术研究、实验或轻量级工业任务(如获取特征值);
Torch具有十分优秀的速度性能,但其使用Lua语言;
DL4j兼容JVM,也适用 Java、Clojure和 Scala;






评论