Stay foolish:初学者轻松了解“大数据”

网络上流传着这么的一句流行语:“万事不懂问度娘”。自从有了各种搜索引擎,新名词新技术对大众而言,已不再神秘。然而,当你搜索“大数据”或者“big data solution”等关键字时,搜索出的海量相关知识铺天盖地,对初学者而言,仍然很难在短时间内入门。本文目的,是以傻瓜式提问的方式让初学者轻松的了解“大数据”。
本文引用地址:https://www.eepw.com.cn/article/201710/368585.htm大数据的概念
“大数据”,是不是----数据很大就叫大数据?
实际上简单的这样理解也没有错,在明确定义时,会比较强调大数据的4个V的特性: Volume,Variety,Value,Velocity。也就是:
一、数据存储空间占用大(至PB及以上级别);
二、数据类型繁多;
三、价值密度低;
四、处理速度快。
搜索的信息中,你会发现有某些名词出现的频率非常高,心里也随之会产生一些疑问。“PB是多大?”“Map-Reduce是啥?”“Hadoop是啥?”“大数据跟云计算啥关系?跟传统意义的数据库啥关系?”等等。
这么多的信息量,我们还是按照大数据的基本定义,四个V来逐一梳理吧。
从第一个V开始,Volume。
数据量很大,到底能达到什么程度呢?先来学习一下数量级的知识吧。
1KB(Kilobyte 千字节) = 2^10 B = 1024 B;
1MB(Megabyte 兆字节) = 2^10 KB = 1024 KB = 2^20 B;
1GB(Gigabyte 吉字节) = 2^10 MB = 1024 MB = 2^30 B;
1TB(Trillionbyte 太字节) = 2^10 GB = 1024 GB = 2^40 B;
1PB(Petabyte 拍字节) = 2^10 TB = 1024 TB = 2^50 B;
1EB(Exabyte 艾字节) = 2^10 PB = 1024 PB = 2^60 B;
1ZB(Zettabyte 泽字节) = 2^10 EB = 1024 EB = 2^70 B;
1YB(YottaByte 尧字节) = 2^10 ZB = 1024 ZB = 2^80 B;
1BB(Brontobyte ) = 2^10 YB = 1024 YB = 2^90 B;
1NB(NonaByte ) = 2^10 BB = 1024 BB = 2^100 B;
1DB(DoggaByte) = 2^10 NB = 1024 NB = 2^110 B;
……
“哇!坑爹啊,整出这么多名词,跟大数据都有关系吗?需要我们掌握吗?”别激动!其实,KB,MB,GB我们在日常电脑操作中已经经常碰到了。甚至TB级的大硬盘,也已经应用于家用电脑中了。我们所说的“大数据”,目前大多产品还处在了立足PB展望EB的级别。后面的那些什么ZB、YB、BB、NB、 DB……等,就暂时先当他们是浮云吧~
第二个V, Variety。
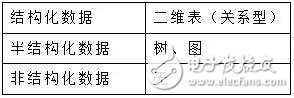
关于这一点,百度百科里是这么说的“网络日志、视频、图片、地理位置信息等等”。从专业一点的角度,我们可以说“大数据”中,可以有结构化数据,但更多的是大量的非结构化和半结构化数据。
结构化和非结构化数据是什么意思?
结构化数据是指,可以存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
非结构化数据,是指不方便用数据库二维逻辑表来表现的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
而半结构化数据,就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
上述的描述,其实还是有点不明确。用数据模型的列表来看,区别就更清晰一点了:
第三个V,Value。
价值密度低。以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒。
第四个V,Velocity。
处理速度快。如此庞大的数据量,需要在短时间内迅速响应。所使用的技术,当然是有别于传统的数据挖掘技术的。
释疑解惑
“梳理完了四个V,咋还是云山雾罩的呢?”
下面来回答几个初学者可能思考到的问题吧!
针对大数据的四个V,有没有什么对应的技术来应对呢?
目前,查询“大数据”,你会发现度娘给出的各种信息中,Hadoop这个词出现的很频繁。而且,很多厂商提供的产品,也都会打上一个标签:“**产品已经并入Hadoop分布式计算平台,以及将Hadoop引入**产品。”
什么是Hadoop?
Hadoop是由Apache基金会开发的一个分布式系统基础架构。它是一个能够对大量数据进行分布式处理的软件框架。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。
Hadoop包含了如下子项目:
1. Hadoop Common: 在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
2. HDFS: Hadoop 分布式文件系统 (Distributed File System) - HDFS (Hadoop Distributed File System)
3. MapReduce:并行计算框架,0.20前使用 org.apache.hadoop.mapred 旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API
4. HBase: 类似Google BigTable的分布式NoSQL列数据库。
5. Hive:数据仓库工具,由Facebook贡献。
6. Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
7. Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
8. Pig: 大数据分析平台,为用户提供多种接口。
作为初学者,我们先拨开一些浮云,看看这里面到底有些什么。有三个主体部分,是我们需要重点关注的:HDFS、MapReduce、HBase。
实际上,Apache Hadoop的HDFS是Google File System(GFS)的开源实现。MapReduce是Google MapReduce的开源实现。HBase是Google BigTable的开源实现。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。它主要有以下几个优点:1高可靠性2高扩展性3高效性4高容错性。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。而实际上,很多公司提供的大数据产品也是基于Hadoop进行开发的。
数据存储空间占用大
针对数据存储空间占用大,我们需要用到的是“分布式存储”。分布式存储系统,就是将数据分散存储在多台独立的设备上。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
前面我们介绍到的Hadoop,其中的HDFS就是现今最流行的分布式存储平台之一。
HDFS原理简要描述
HDFS(Hadoop Distributed File System),是一个分布式文件系统。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
HDFS是一个主从结构的体系,一个HDFS集群是由一个名字节点,它是一个管理文件的命名空间和调节客户端访问文件的主服务器,当然还有的数据节点,一个节点一个,它来管理存储。HDFS暴露文件命名空间和允许用户数据存储成文件。
对外部客户机而言,HDFS 就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。
内部机制,是将一个文件分割成一个或多个的块,这些块存储在一组数据节点中。名字节点(NameNode)操作文件命名空间的文件或目录操作,如打开,关闭,重命名,等等。它同时确定块与数据节点的映射。数据节点(DataNode)来负责来自文件系统客户的读写请求。数据节点同时还要执行块的创建,删除,和来自名字节点的块复制指示。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。
HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
数据类型繁多
大数据处理,有如下需求:对数据库高并发读写的需求、对海量数据的高效率存储和访问的需求、对数据库的高可扩展性和高可用性的需求。传统的关系型数据库在此类需求面前束手无策。此时,一个新的概念被引入了----NoSQL。
什么是NoSQL?
NoSQL=Not Only SQL,指的是非关系型的数据库。
非关系型数据库以键值对存储,它的结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。
应该说明的是,NoSQL在处理超大量数据时性能卓越,而且可以在PC服务器集群上运行,成本低廉,具有高扩展性和实用性。但是,目前大多数NoSQL是开源项目,没有供应商正是支持,而且在数据完整性等方面远不如关系型数据库,企业级应用不多。
HBASE 的原理简要介绍,如何存储非结构化数据
HBase是一个分布式的、面向列的开源数据库,HBase在Hadoop平台内的结构化数据的分布式存储系统。HBase与传统关系型数据库的区别在于,它是一个适合非结构化数据存储的数据库,而且HBase是基于列而不是基于行的模式。
HBase利用Hadoop HDFS作为其文件存储系统,HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持;用Hadoop MapReduce来处理海量数据,MapReduce为HBase提供了高性能的计算能力;用Hadoop Zookeeper作为协同服务,Zookeeper为HBase提供了稳定服务和failover机制。
HBase数据模型如下:

Ø Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
Ø Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
Ø Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理。
HBase中有两张特殊的Table,-ROOT-和.META。
.META.:记录了用户表的Region信息,.META.可以有多个regoin
-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作, client端会做cache缓存。
价值密度低
Mapreduce是在大数据中挖掘价值的有效方法
把MapReduce单独列出来,是有必要的,因为它太重要了。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(化简)”,和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
MapReduce 本身就是用于并行处理大数据集的软件框架。MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。
具体分步骤描述为:
1) 在正式执行map函数前,需要对输入进行“分片”(就是将海量数据分成大概相等的“块”,hadoop的一个分片默认是64M),以便于多个map同时工作,每一个map任务处理一个“分片”。
2) 分片完毕后,多台机器就可以同时进行map工作了。map函数要做的事情,相当于对数据进行“预处理”,输出所要的“键值”。map对每条记录的输出以《key,value》对的形式输出。
3) 在进入reduce阶段之前,还要将各个map中相关的数据(key相同的数据)归结到一起,发往一个reducer。这里面就涉及到多个map的输出“混合地”对应多个reducer的情况,这个过程叫做“洗牌”。
4) 接下来进入reduce阶段。相同的key的map输出会到达同一个reducer。reducer对key相同的多个value进行reduce操作,最后一个key的一串value经过reduce函数的作用后,变成了一个value。
处理速度快
MapReduce除了能挖掘大数据价值,同时也是一种分布式/并行计算模型。虽然它是一个很好的抽象,但不能有效地解决计算领域的任何问题。为了满足大数据及时响应的特性,数据流计算的研究被提上了日程。实时计算方向重要的一个模块就是实时数据流计算。
在数据流模型中,需要处理的输入数据(全部或部分)并不存储在可随机访问的磁盘或内存中,但它们却以一个或多个“连续数据流”的形式到达。数据流不同于传统的存储关系模型,主要区别有如下几个方面:
流中的数据元素在线到达;
系统无法控制将要处理的新到达的数据元素的顺序,无论这些数据元素是在一个数据流中还是跨多个数据流;也即重放的数据流可能和上次数据流的元素顺序不一致;
数据流的潜在大小也许是无穷无尽的;
一旦数据流中的某个元素经过处理,要么被丢弃,要么被归档存储。因此,除非该数据被直接存储在内存中,否则将不容易被检索。相对于数据流的大小,这是一种典型的极小相关。
数据流模型中的操作并不排除传统关系型数据的存在。通常,数据流操作将建立数据流和关系型数据的联系。在数据流处理过程中,更新存储关系的同时可能会产生传输处理问题。
近年来,业界出现了不少实时数据流计算系统,虽然没有一个类似于Hadoop的集大成者,但是也都各具特色。由于网络数据的不断膨胀和用户需求的不断涌现,近年来互联网企业开始广泛研究和使用数据流处理,诞生了Yahoo! S4、Twitter Storm、IBM StreamBase、Facebook的Puma/Puma2 及学术界开源的Borealis等系统。
大数据是云计算吗?
如果有人问你这句话,你看完本文,可以很自信的回答他“Absolutely!”
为了回答这个问题,我们有需要引入一个概念----云计算是什么。
维基百科给云计算下的定义:云计算将IT相关的能力以服务的方式提供给用户,允许用户在不了解提供服务的技术、没有相关知识以及设备操作能力的情况下,通过Internet获取需要服务。
中国云计算网将云定义为:云计算是分布式计算(Distributed Computing)、并行计算(Parallel Computing)和网格计算(Grid Computing)的发展,或者说是这些科学概念的商业实现。
云计算分为三个层次:基础设施即服务(IaaS),平台即服务(PaaS)和软件即服务(SaaS)。
“在说什么,云啊云啊,好多的云啊,好大的棉花糖啊~~”
云计算的核心技术是海量数据分布式存储和海量数据分布式计算,现在云计算系统主要采用Map-Reduce模型。
“Map-Reduce?哪里看到过?”没错,在前面对大数据的解读的时候,我们就已经明确描述过这一段。终于看到熟悉的内容了,无比兴奋啊。
实际上,云计算的数据存储技术主要有谷歌的非开源的GFS(Google File System)和 Hadoop 开发团队开发的GFS的开源实现HDFS(Hadoop Distributed File System)。大部分IT厂商,包括yahoo、Intel的“云”计划采用的都是HDFS的数据存储技术。
通过对简单的云计算的定义及技术分析,加上前面我们对大数据的了解,不难得出结论,大数据当然是可以归为云计算的范畴。
应用领域有哪些?
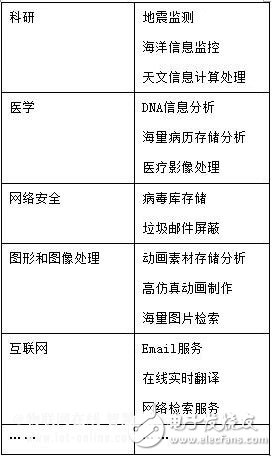
说些我们熟知的地方吧,哪些我们接触到的地方用到了Hadoop?
要回答这个问题,举几个例子,很容易。在国内,包括中国移动、百度、网易、淘宝、腾讯、金山和华为等众多公司都在研究和使用它。
行业动态及展望
“大数据”的影响,增加了对信息管理专家的需求,甲骨文,IBM,微软和SAP花了超过15亿美元的在软件智能数据管理和分析的专业公司。这个行业自身价值超过1000亿美元,增长近10%,大数据已经出现,因为我们生活在一个社会中有更多的东西。有46亿全球移动电话用户有1亿美元和20亿人访问互联网。基本上,人们比以往任何时候都与数据或信息交互。1990年至2005年,全球超过1亿人进入中产阶级,这意味着越来越多的人,谁收益的这笔钱将成为反过来导致更多的识字信息的增长。思科公司预计,到2013年,在互联网上流动的交通量将达到每年667艾字节。
最早提出“大数据”时代已经到来的机构是全球知名咨询公司麦肯锡。麦肯锡在研究报告中指出,数据已经渗透到每一个行业和业务职能领域,逐渐成为重要的生产因素;而人们对于海量数据的运用将预示着新一波生产率增长和消费者盈余浪潮的到来。
麦肯锡的报告发布后,大数据迅速成为了计算机行业争相传诵的热门概念,也引起了金融界的高度关注。随着大数据时代的全面开启,你是否做好了充分的准备迎接这个时代的到来呢?






评论