对比Ruby和Python的垃圾回收


上面三个”M”标记的对象为活跃对象,依然被我们的程序使用。在Ruby解释器内部,通常使用”free bitmap”的数据结构来保存一个对象是否被标记:
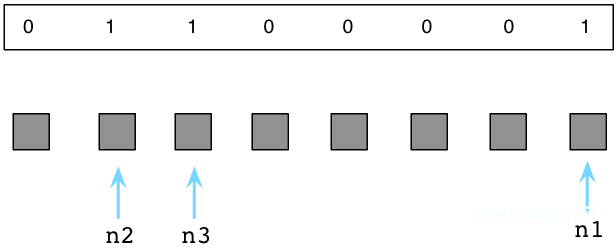
Ruby将”free bitmap”保存在一个独立的内存区域,以便可以更好的利用Unix的”copy-on-write”特性。更详细的信息,请参考我的另一篇文章《为什么Ruby2.0的垃圾回收器让我们如此兴奋》。
如果活跃对象被标记了,那么其余的便是垃圾对象,意味着它们不再会被代码使用。在下图中,我使用白色的方块表示垃圾对象:
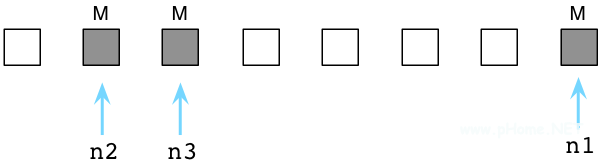
接下来,Ruby将清理没有使用的,垃圾对象,将它们链入空闲对象链表(free list):
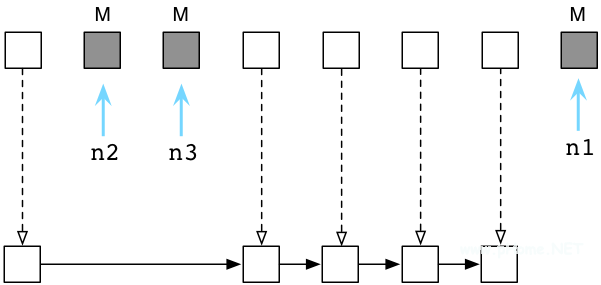
在解释器内部,这个过程非常迅速,Ruby并不会真正的将对象从一个地方拷贝到另一个地方。相反的,Ruby会将垃圾对象组成一个新的链表,并且链入空闲对象链表(free list)。
现在,当我们要创建一个新的Ruby对象的时候,Ruby将为我们返回收集的垃圾对象。在Ruby中,对象是可以重生的,享受着多次的生命!
标记回收算法 vs. 引用计数算法
咋一看,Python的垃圾回收算法对于Ruby来说是相当让人感到惊讶的:既然可以生活在一个整洁干净的房间,为什么要生活在一个脏乱的房间呢?为什么Ruby周期性的强制停止程序的运行去清理垃圾,而不使用Python的算法呢?
然而,引用计数实现起来不会像它看起来那样简单。这里有一些许多语言不愿像Python一样使用引用计数算法的原因:
首先,实现起来很困难。Python必须为每一个对象留有一定的空间来保存引用计数。这会导致一些细微的内存开销。但更遭的是,一个简答的操作例如改变一个变量或引用将导致复杂的操作,由于Python需要增加一个对象的计数,减少另一个对象的计数,有可能释放一个对象。
其次,它会减慢速度。尽管Python在程序运行过程中垃圾回收的过程非常顺畅(当你把脏盘子放到水槽后,它立马清洗干净),但是运行的并不十分迅速。Python总是在更新引用计数。并且当你停止使用一个巨大的数据结构时,例如一个包含了大量元素的序列,Python必须一次释放许多对象。减少引用计数可能是一个复杂的,递归的过程。
最后,它并不总是工作的很好。在我演讲的下一部分,也就是下一篇帖子中能看到,引用计数不能处理循环引用数据结构,它包含循环引用。
下一次…
下周我将发布演讲的其他部分。我将讨论Python怎样处理循环引用数据结构,以及在即将到来的Ruby2.1中,垃圾回收器是怎样工作的。


评论