C语言的那些小秘密之链表(一)

链表,一个对于学习过C语言的人都是再熟悉不过的概念了,可能很多学习过链表的人都觉得链表没什么值得太在意的地方,可是如果你走进linux内核,去看看linux内核里面链表的实现方式,你不得不为之惊叹。可能有人会觉得linux内核链表实现方式仅此而已,但是你要知道,如果你没有见到这样的实现方式之前,能写出那样的链表嘛?所以在写链表的文章时,我深知自己不可能用一篇文章来讲解完链表的知识点,所以我特地分为三个部分(单链表、双链表、linux内核链表,而其中linux内核链表单独拿出来讲是因为它的特殊性,在后面的博客中我们再来细谈它)来进行讲解,尽可能用简短的文字描述加上简单易懂的代码来向读者讲解我所理解的链表,希望我所讲的链表能都对你有所帮助。接下来言归正传,开始我们的链表之旅。
本文引用地址:https://www.eepw.com.cn/article/272381.htm那么什么是链表呢?链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点组成,即链表中的每个元素,结点可以在运行时动态生成。每个结点均由两个部分所组成:一个是存储数据元素的数据域,另一个是存储相邻结点地址的指针域。相比于线性表顺序结构,链表比较方便插入和删除操作。
对于链表我们可以将其分为单链表、双向链表和循环链表等。首先我们先讲讲单链表。
所谓单链表,是指数据结点是单向排列的。一个单链表结点,其结构类型分为两部分:
1、数据域:用来存储本身数据
2、指针域:用来存储下一个结点地址或者说指向其直接后继的指针。
如下图所示:
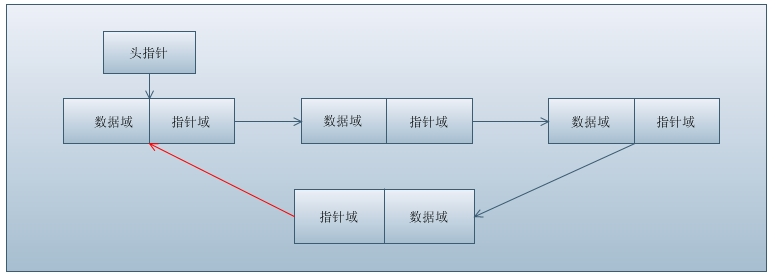
注意:如果有图中的红色箭头部分,则变为了单向循环链表。
那什么又是双链表呢?双向链表其实是单链表的改进。当我们对单链表进行操作时,有时你要对某个结点的直接前驱进行操作时,又必须从表头开始查找。这是由单链表结点的结构所限制的。因为单链表每个结点只有一个存储直接后继结点地址的链域,那么能不能定义一个既有存储直接后继结点地址的链域,又有存储直接前驱结点地址的链域的这样一个双链域结点结构呢?这就是双向链表。
在双向链表中,结点除含有数据域外,还有两个链域,一个存储直接后继结点地址,一般称之为右链域;一个存储直接前驱结点地址,一般称之为左链域。
如下图所示:
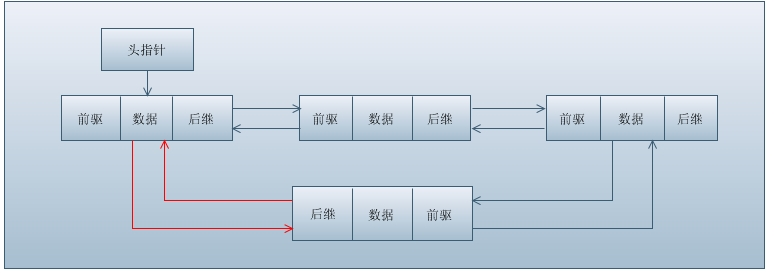
注意:如果有图中的红色箭头部分,则变为了双向循环链表。
看完了上面的介绍之后,我想读者对于链表算是有了一个大致的了解。那么接下来我们的任务就是学习如何使用链表,我们从最简单的代码开始,教会读者来学习使用链表,首先我们来看一个单链表的创建。为了便于讲解,我在此就把所有的代码放到一个源文件中来执行了,当然读者在实际编写代码的过程中不管是为了维护还是阅读都应该使用头文件,而不要在一个源文件中一条龙似地写到底。
#include
#include
#include
#include
#define N 3
#undef _EXAM_ASSERT_TEST_ //禁用
//#define _EXAM_ASSERT_TEST_ //启用
#ifdef _EXAM_ASSERT_TEST_ //启用断言测试
void assert_report( const char * file_name, const char * function_name, unsigned int line_no )
{
printf( "n[EXAM]Error Report file_name: %s, function_name: %s, line %un",
file_name, function_name, line_no );
abort();
}
#define ASSERT_REPORT( condition )
do{
if ( condition )
NULL;
else
assert_report( __FILE__, __func__, __LINE__ );
}while(0)
#else // 禁用断言测试
#define ASSERT_REPORT( condition ) NULL
#endif /* end of ASSERT */
typedef enum _SListReturn
{
SLIST_RETURN_OK
}SListReturn;
typedef struct node
{
char name[10];
int score;
struct node *link;
}stud;
stud * creat(int n)
{
stud *p,*h,*s;
int i;
if((h=(stud *)malloc(sizeof(stud)))==NULL)
{
printf("分配内存空间失败!");
exit(0);
}
h->name[0]='�';
h->score=0;
h->link=NULL;
p=h;
for(i=0;i
{
if((s= (stud *) malloc(sizeof(stud)))==NULL)
{
printf("分配内存空间失败!");
exit(0);
}
p->link=s;
printf("请输入第%d个人的姓名:",i+1);
scanf("%s",s->name);
printf("请输入第%d个人的成绩:",i+1);
scanf("%d",&s->score);
s->link=NULL;
p=s;
}
return h;
}
SListReturn destroy(stud* head)
{
stud* tmp,*next;
tmp=head;
while(tmp!=NULL)
{
next=tmp->link;
tmp->link=NULL;
free(tmp);
tmp=next;
}
return SLIST_RETURN_OK;
}
SListReturn print(stud* head)
{
stud* tmp=head->link;
while(tmp!=NULL)
{
printf("%s的成绩为%dt",tmp->name,tmp->score);
tmp=tmp->link;
}
return SLIST_RETURN_OK;
}
void main()
{
int number;
stud *head;
number=N;
head=creat(number);
ASSERT_REPORT(print(head)==SLIST_RETURN_OK);
ASSERT_REPORT(destroy(head)==SLIST_RETURN_OK);
}
运行结果为:
root@ubuntu:/home/paixu# ./tt
请输入第1个人的姓名:rewq
请输入第1个人的成绩:123
请输入第2个人的姓名:fdsa
请输入第2个人的成绩:456
请输入第3个人的姓名:vcxz
请输入第3个人的成绩:789
rewq成绩为123 fdsa成绩为456 vcxz成绩为789
看了上面的代码,如果读过我之前写的那篇《C语言的那些小秘密之断言》的读者就知道,在这段代码的红色部分我们使用了自己实现的断言,学以致用嘛,所有特此在这里拿出来使用下,如果还没有看那篇文章的读者,我建议你看看,毕竟断言还是很有用的。代码的蓝色部分也算是一个特色点,因为以前可能我们在自己的代码中都是返回一些int型值或者NULL之类的,使得代码的返回值不能够直观的体现出运行结果,也使得代码的可读性比较差,所有为了改善我们的代码,我们要学习自己定义返回类型,做到尽可能的从各个方面去改善我们编写的代码。在这里我们自己用枚举型的数据结构来定义了返回类型,因为代码的关系,我这里仅仅使用了一个返回类型SLIST_RETURN_OK,根据自己代码的需要读者可以自己添加编写更多的返回值,我仅仅是在这里举出一个例子。如:
typedef enum _SListReturn
{
SLIST_RETURN_OK,
SLIST_RETURN_STOP,
SLIST_RETURN_FAIL
}SListReturn;
现在我们从以上代码中选出部分代码来加注释进行讲解。
stud *p,*h,*s; /* *h保存表头结点的指针,*p指向当前结点的前一个结点,*s指向当前结点*/
h->link=NULL; /*把表头结点的链域置空*/
p=h; /*p指向表头结点*/
p->link=s; /*把s的地址赋给p所指向的结点的链域,这样就把p和s所指向的结点连接起来了*/
在代码中除了创建链表的函数外,我们还使用了两个函数,一个是SListReturn print(stud* head)函数,通过该函数我们打印输出链表中的数据。另一个函数是SListReturn destroy(stud* head),通过该函数我们对申请的链表空间进行释放。通过以上函数我想读者应该知道了如何创建一个链表和处理链表中的数据,在这里我仅仅是对数据做了打印操作,如果读者有兴趣可以进行其他的操作。
以上代码实现了单链表的创建,但是链表的常用操作还有查找、插入、删除等没有讲解,删除操作与插入操作类似,就不在这里一一讲解了,在此我们以查找和插入为例进行讲解,但是读者在编写删除操作的时候别忘了把删除的结点释放掉。接下来我们就来看看一段查找和插入的操作。
代码功能为在查找到的结点后面添加一个新的结点。
#include
#include
#include
#include
#define N 3 /*N为人数*/
//#undef _EXAM_ASSERT_TEST_ //禁用
#define _EXAM_ASSERT_TEST_ //启用
#ifdef _EXAM_ASSERT_TEST_ //启用断言测试
void assert_report( const char * file_name, const char * function_name, unsigned int line_no )
{
printf( "n[EXAM]Error Report file_name: %s, function_name: %s, line %un",
file_name, function_name, line_no );
abort();
}
#define ASSERT_REPORT( condition )
do{
if ( condition )
NULL;
else
assert_report( __FILE__, __func__, __LINE__ );
}while(0)
#else // 禁用断言测试
#define ASSERT_REPORT( condition ) NULL
#endif /* end of ASSERT */
typedef enum _SListReturn
{
SLIST_RETURN_OK,
}SListReturn;
typedef struct node
{
char name[20];
int score;
struct node *link;
}stud;
stud * creat(int n)
{
stud *p,*h,*s;
int i;
if((h=(stud *)malloc(sizeof(stud)))==NULL)
{
printf("分配内存空间失败!");
exit(0);
}
h->name[0]='�'; /*把表头结点的数据域置空*/
h->score=0;
h->link=NULL; /*把表头结点的链域置空*/
p=h; /*p指向表头结点*/
for(i=0;i
{
if((s= (stud *) malloc(sizeof(stud)))==NULL)
{
printf("分配内存空间失败!");
exit(0);
}
p->link=s; /*把s的地址赋给p所指向的结点的链域,这样就把p和s所指向的结点连接起来了*/
printf("请输入第%d个人的姓名:",i+1);
scanf("%s",s->name); /*姓名*/
printf("请输入第%d个人的成绩:",i+1);
scanf("%d",&s->score); /*分数*/
s->link=NULL;
p=s;
}
return(h);
}
stud * search(stud *h,char *x) /*查找函数*/
{
stud *p;
char *y;
p=h->link;
while(p!=NULL)
{
y=p->name;
if(strcmp(y,x)==0)
return(p);
else p=p->link;
}
if(p==NULL)
printf("没有查找到该数据!");
}
SListReturn insert(stud *p) /*插入函数,在指针p后插入*/
{
char stu_name[20];
int stu_score;
stud *s; /*指针s是保存新结点地址的*/
if((s= (stud *) malloc(sizeof(stud)))==NULL)
{
printf("分配内存空间失败!");
exit(0);
}
printf("请输入你要插入的人的姓名:");
scanf("%s",stu_name);
printf("请输入你要插入的人的成绩:");
scanf("%d",&stu_score);
strcpy(s->name,stu_name); /*把指针stuname所指向的数组元素拷贝给新结点的数据域*/
s->score=stu_score;
s->link=p->link; /*把新结点的链域指向原来p结点的后继结点*/
p->link=s; /*p结点的链域指向新结点*/
return SLIST_RETURN_OK;
}
SListReturn destroy(stud* head)
{
stud* tmp,*next;
tmp=head;
int i=0;
while(tmp!=NULL)
{
next=tmp->link;
tmp->link=NULL;
free(tmp);
tmp=next;
i++;
printf("第%d次释放n",i);
}
return SLIST_RETURN_OK;
}
SListReturn print(stud* head)
{
stud* tmp=head->link;
while(tmp!=NULL)
{
printf("%s成绩为%dn",tmp->name,tmp->score);
tmp=tmp->link;
}
return SLIST_RETURN_OK;
}
void main()
{
int number; /*保存人数的变量*/
char fname[10]; /*保存输入的要查找的人的姓名*/
stud *head,*searchpoint; /*head是保存单链表的表头结点地址的指针*/
number=N;
head=creat(number); /*把所新建的单链表表头地址赋给head*/
printf("请输入你要查找的人的姓名:");
scanf("%s",fname);
searchpoint=search(head,fname); /*查找并返回查找到的结点指针*/
insert(searchpoint); /*调用插入函数*/
print(head);
destroy(head);
//ASSERT_REPORT(print(head)==SLIST_RETURN_OK);
//ASSERT_REPORT(destroy(head)==SLIST_RETURN_OK);
}
运行结果为:
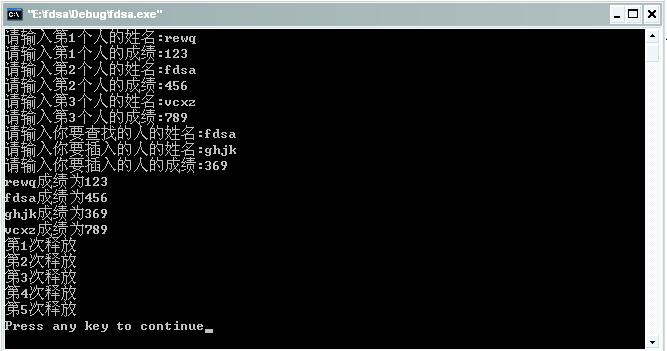
以防图片打开失败,在此特地加上文字描述。
请输入第1个人的姓名:rewq
请输入第1个人的成绩:123
请输入第2个人的姓名:fdsa
请输入第2个人的成绩:456
请输入第3个人的姓名:vcxz
请输入第3个人的成绩:789
请输入你要查找的人的姓名:fdsa
请输入你要插入的人的姓名:ghjk
请输入你要插入的人的成绩:369
rewq成绩为123
fdsa成绩为456
ghjk成绩为369
vcxz成绩为789
第1次释放
第2次释放
第3次释放
第4次释放
第5次释放
Press any key to continue
代码中的关键部分都加了注释来进行说明,所以在此就不做一一讲解了,只说几个值得注意的地方,那就是destroy()函数的实现,可能有很多人对这儿的操作不是很熟悉,因为对于释放成功与否都没有能够直观的显示出来,就算写对了也还是不太确信,这个时候我们就要自己来加点东西了。所以在此特地教读者一个方法,来进行简单的验证,通过i++;、 printf("第%d次释放n",i);语句来实现打印释放了多少个结点,和我们创建的结点数目进行比较即可,在本代码中我们一开始创建了4个结点(注意:包括头结点),之后又插入了一个结点,所以总需要释放5个结点,看看打印的结果就知道我们的函数实现正确了,当然还有很多验证的方法,在此仅是例举一个简单的方法。
总不能没玩没了的写下去吧,所以暂时到此为止,到下一篇博客我们接着讲。由于本人水平有限,博客中的不妥或错误之处在所难免,殷切希望读者批评指正。同时也欢迎读者共同探讨相关的内容,如果乐意交流的话请留下你宝贵的意见。
linux操作系统文章专题:linux操作系统详解(linux不再难懂)

c语言相关文章:c语言教程
linux相关文章:linux教程

评论