一种面向多核DSP的小容量紧耦合快速共享数据池

除了这种对程序员透明的硬件同步机制之外,FSDP还支持基于软件查询的同步机制。即在每次改变信号灯状态前,插入一段查询“信号灯”状态的例程,然后根据查询的结果决定程序的流向。
4.4 消除读访问冲突
在FSDP的共享模式下存在多DSP核同时读一个存储体的冲突。虽然利用仲裁逻辑配合队列机制可以缓解冲突,但是,这种方式降低了FSDP的并行性。另外,可以采用存储体复制或者采用多端口存储体的方式。为此,本文进行了对比实验,结果表明,4个1KB大小的单端口SRAM在工作频率和面积上都优于4端口1KB的全定制SRAM模块,而且单端口SRAM可以由EDA工具快速编译生成,便于设计实现。因此,对于FSDP这类小容量的便笺存储器,本文采用存储体复制的方式解决访问冲突:将原来的每个存储体换成4个同样大小的单端口存储体,构成具有4个虚拟端口的存储体,如图5所示。
在处理读写访问时,存控逻辑自动进行数据写复制和读端口的分配工作,读写过程中对用户都是透明的。这种方式完全消除了多核的读访问冲突,实现了最大的共享访问带宽,提高了FSDP的并行性和实时性。
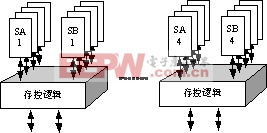
图5 存储体复制构成虚拟多端口存储体
5. 性能分析
5.1 分析模型与设计实现
本文构建了整个SDSP的C语言模拟器SDSP-Sim。SDSP-Sim是一个时钟精确的模拟器,能够运行经过编译和手工分配的多核DSP应用程序,报告程序运行的各种统计信息和计算结果。每个处理器核占用一个模拟进程,RISC与DSP核之间采用进程通信的方式传输控制信息。本文以MediaBench基准程序集为基础,选择了6组典型的多媒体类与通信类应用程序,用于评测FSDP的性能,如表1所示。为了满足多核DSP的并行计算需求,对于原来复杂度较低的一些测试程序,例如PEGWIT和JPEG_c,本文扩大了它们的数据集。对于MP3解码程序MP3_d则将其扩展为两路并行解码器2MP3_d。由于SDSP的并行编译器开发工作还没有完成,本文仍采用手工的方式对测试程序进行并行化映射。
表1 用于性能评测的测试程序说明
本文采用SMIC 0.13μm CMOS工艺库对FSDP进行了设计实现。其中各存储体采用EDA工具生成的单端口SRAM。下表2给出了FSDP的各项设计指标。其中,“无阻塞读延迟”是指在同步成功且没有冲突的情况下,从DSP核发出读请求到获得返回数据之间的时间间隔。
表20.13μm CMOS工艺下四通道FSDP的各项性能指标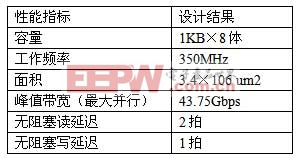
5.2 性能对比
对于多核处理器共享SPM的研究,前人的工作主要是针对SPM的编译优化和数据划分算法的研究。文献0介绍的VS-SPM(虚拟共享便笺存储器)原型结构与本文的FSDP有类似之处,它根据SPM与处理器核的关系,将SPM分成本地SPM和远程SPM,各个处理器核通过共享总线访问各SPM模块。下表3对比了本文的FSDP与VS-SPM在结构上的差异。VS-SPM主要是针对编译优化和数据划分算法优化而设计的,其硬件优化程度和访问速度都不及FSDP,而且没有解决多个处理器核并行访问冲突的问题,不支持核间数据的流水传输。
表3 FSDP与VS-SPM的结构对比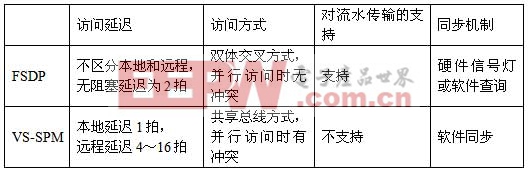
本文建立了VS-SPM的结构模型,将DSP核间同样一批共享数据先后映射到VS-SPM和FSDP的存储空间上,分别得到两种结构下程序的执行时间TVS-SPM和TF-SDP,然后按照(1)式计算出FSDP相对VS-SPM的性能加速比。
图6给出了6组测试程序的实验结果。结果表明,通过FSDP在DSP核之间传输共享数据相比通过VS-SPM传输具有明显的性能优势,6组程序的平均性能加速比达到了1.37。
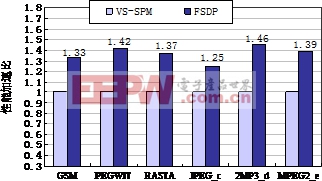
图6FSDP相对VS-SPM的性能加速比
在引入FSDP之前,异构多核DSP主要通过共享L2 Cache传输DSP核间的共享数据。为了评测FSDP对系统性能的加速作用,本文比较了下列三种数据映射方式下异构多核DSP的计算性能:
仅用L2 Cache:DSP核间的共享数据全部通过L2传输;
仅用FSDP:DSP核间的共享数据全部通过FSDP传输;
FSDP + L2:将DSP核间的不规则共享数据映射到FSDP的地址空间,其余的共享数据流仍通过L2传输。
利用SDSP-Sim软件模拟器分别得到上述三种映射方式下程序的执行时间,然后以第一种映射方式下的执行时间为基准,计算出另外两种方式的性能加速比,结果如图7所示:
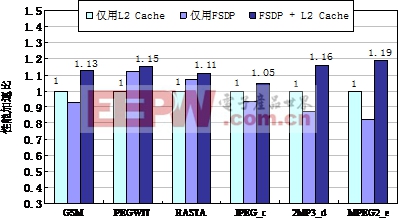
图7三种数据映射方式下系统的计算性能对比
实验结果表明,在FSDP + L2 Cache方式下,程序的性能是最高的。6组程序的平均性能加速比为1.13。本文分析认为:
对于核间共享数据包含大量细粒度数据和不规则数据流的应用程序(例如PEGWIT和RASTA),仅用FSDP相比仅通过L2 Cache传输共享数据具有更高的计算性能;
对于核间共享数据量较大和数据流分布比较密集的应用程序(例如2MP3_d和MPEG2_e),仅用FSDP传输共享数据的计算性能较低,这是因为FSDP对共享数据的分块处理使得同步开销在执行时间中的比例增大,影响了总执行时间;
FSDP与共享数据Cache结合使用进一步提高了共享存储多核DSP的片内数据重用性,减少了对片外数据的长延迟访问,因而能够获得最佳的计算性能。其中,对于需要紧耦合共享的小容量数据或者非常不规则的短数据流,优先选择通过FSDP传输,减少通过共享Cache的长延迟访问开销;反之,对于大块数据的共享或者规则数据流的传输,则宜采用共享Cache的方式,降低数据频繁分块的同步开销。
5.3 扩展性分析
在消除了FSDP的访问冲突之后,所有DSP核可以同时访问不同的存储体。理论上来看,FSDP的访问带宽可以随着DSP核数量的增长而线性增长,具有良好的可扩展性。为此,我们进行了分析与实验。定义B为FSDP的有效访问带宽,即在考虑访存延迟和工作频率的情况下所有DSP核访问FSDP的实际存储带宽;N表示DSP核的数量。本文在N=1~8的情况下分别对FSDP进行了单独的设计实现,得到了B与N的关系,如图8所示。
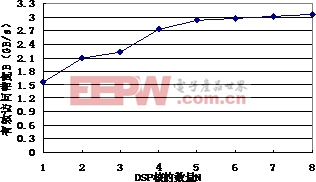
图8FSDP有效访问带宽与DSP核数量的关系
由实验结果可见,当N小于5时, B快速增长,与N呈近似的线性关系。随着N的进一步增大,DSP核与存储体之间的控制逻辑开销、互连总线和交叉开关端口数量以O(N2)量级增长,FSDP的工作频率开始下降,访问延迟越来越大,FSDP的有效访问带宽增长十分缓慢。因此,FSDP更适合于5核以内的多核DSP。当DSP核数量超过8核以上时,我们将以4核为一个超节点进行结构扩展。超节点内部采用FSDP实现紧耦合的数据传输,超节点之间通过片上网络(NoC)或者其他共享存储结构进行数据传输。
7结束语
相比传统的Cache结构,便笺式存储器具有更灵活的结构、简洁的控制逻辑、更低的访问延迟和方便的数据管理等诸多优势。本文针对多核DSP架构设计的快速共享数据缓冲池FSDP结合了便笺式存储器的结构特点和共享存储结构的编程需要,采用软/硬件联合的设计方法,为多核DSP之间传输细粒度共享数据提供了一个紧耦合的快速通路,相比共享二级Cache和DMA传输方式具有更好的传输效率,是一种新型而实用的、可扩展多核共享存储结构。今后,我们将深入研究面向多核处理器的高性能共享存储结构,增强片上存储的可扩展性和可重构能力,进一步提高多核SoC的存储带宽。

评论