基于FPGA的M2M异构虚拟化系统(二)

Table 1 寄存器映射
8086 | MIPS |
AX | s0(R16) |
CX | s1(R17) |
DX | s2(R18) |
BX | s3(R19) |
SP | s4(R20) |
BP | s5(R21) |
SI | s6(R22) |
DI | s7(R23) |
CS | t4(R12) |
DS | t5(R13) |
ES | t6(R14) |
SS | t7(R15) |
IP | t8(R24) |
除了这些寄存器外,还给8086提供了3个辅助寄存器,t0、t1和t2。t0一般作为参数寄存器或返回值寄存器,t1和t2一般作为临时寄存器。这几个寄存器的存在有很大的必要性。
4.2.6.上下文切换
从翻译流程可以看出,整个过程有两个运行环境。翻译过程是在MIPS环境中,执行则是在MIPS的8086虚拟环境中。但硬件只有MIPS的一套寄存器,8086的寄存器是映射到MIPS的寄存器。在切换运行环境时,要先保存当前寄存器组,再载入新的寄存器组。方式可以有两种。一种是将寄存器组保存至堆栈,另一种是将寄存器组保存至内存。这里将其保存至内存,因为这更利于调试,可将寄存器值调出来查看。
上下文切换实现:
/**
* context switch
* @param type - 0:从x86切换到mips,other:从mips切换到x86
*/
void _contextSwitch(int type) {
if (type == _MIPS_TYPE) {
_saveRegisters(_X86_TYPE);
_loadRegisters(_MIPS_TYPE);
} else {
_saveRegisters(_MIPS_TYPE);
_loadRegisters(_X86_TYPE);
}
}
上下文切换的流程及实现如下。
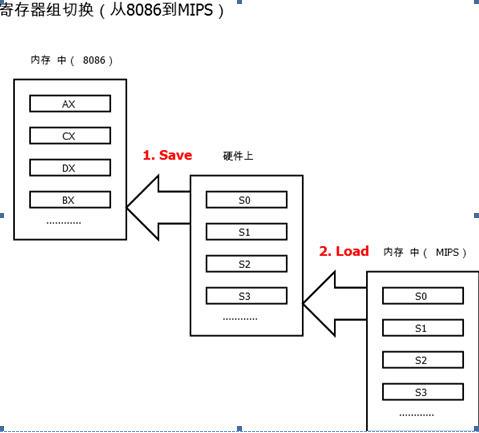
图 34 寄存器组切换
4.2.7.字节顺序与边界对齐问题
字节序(Byte Order)一般有两种:大端序(big-endian)和小端序(little-endian)。大端序是将最高有效字节(MSB,Most Significant Byte)存放至低地址,小端序则是将最低有效字节(LSB,Least Significant Byte)存放至低地址。MIPS采用的是大端序,而8086使用的是小端序。因此,在二进制翻译中,必须要处理这种差异。
8086在访问内存时,如果是字节操作,那么翻译时,可以使用对应的MIPS字节操作指令,如lb,sb等。字节的操作不会有字节序问题,处理多字节时会有字节序问题。8086访问多字节时,不能使用相应的MIPS指令,而应拆分读取,最后再拼凑。过程如图 35所示。
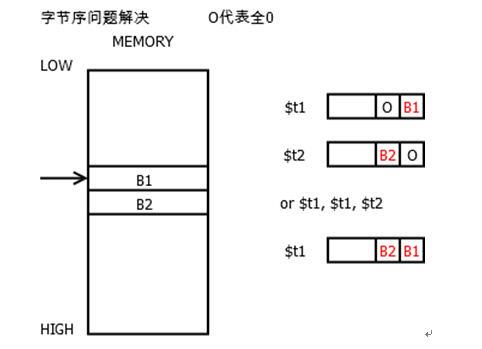
图 35 字节序问题解决
4.2.8.堆栈处理
MIPS有一个堆栈寄存器$sp,8086则是使用一个堆栈段寄存器SS与一个堆栈指针寄存器SP,实际地址为段基址加偏移地址。本设计MIPS和8086各自有自己的堆栈空间。8086堆栈操作对象有寄存器、立即数、内存等。这里以寄存器压栈为例,出栈情况类似。压栈时,首先要计算出绝对地址,然后将寄存器保存。计算地址方法:(SS 4) + IP,是一个20位地址,寻址1M。push AX时,是对一个16位寄存器压栈,由上面的字节序分析可知,要拆分成两个字节压栈。这里为了简便,直接对32位MIPS寄存器进行压栈,因为8086寄存器只占用MIPS寄存器的高16位。这里,绝对地址是放在辅助寄存器里的,因此要对该辅助寄存器进行保存,以防止要压栈的寄存器就是该辅助寄存器而造成压栈失败。我们是将该辅助寄存器保存在MIPS的堆栈中。
4.2.9.操作数分析
8086的操作数类型比较多样,有寄存器、立即数、内存等。每个类型的位宽还可以变化,有8位、16位之分。MIPS比较规则,寄存器为32位,立即数为16位。两者之间的转换是翻译的重要方面。
寄存器如果是16位,则可以直接映射到对应MIPS寄存器的高16位。如果是8位寄存器,不管是高8位还是低8位,一般都要移出至辅助寄存器的高8位。移到高8位的原因是为了运算时能产生正确的标志位。运算完后再将运算结果搬回8086寄存器。
立即数有3种情况:8位,16位及由8位符号扩展来的16位立即数。8位及8位符号扩展可直接以字节访问内存得到,16位立即数则要注意字节序问题,上面已分析过。
内存方面涉及到内存地址及所指向的内存内容。内存地址的拼接会在下文详细分析,8086有多种段寄存器与偏移的组合方式。取内存内容时也会遇到字节序的问题。
操作数类型示意图如下。
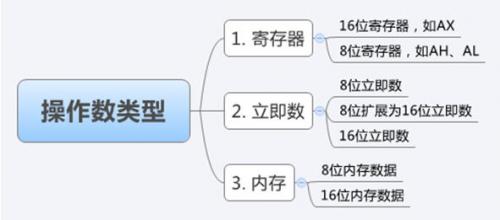
图 36 操作数类型
4.2.10.二进制翻译及代码生成
这部分主要解析8086指令,将其拆分,并生成相应的MIPS代码。在具体解析指令之前,先研究下8086二进制机器码的特点,抽出公共特征。以下几张表均来自于[6]。
Table 2 oo修饰位说明
oo | 功能 |
00 | 如果mmm=110,那么位移量在操作码后面,否则没有使用位移量 |
01 | 操作码后面是8位有符号的位移量 |
10 | 操作码后面是16位有符号的位移量 |
11 | mmm指定一个寄存器而不是一种寻址方式 |
Table 3 16位寄存器/存储器(mmm)字段描述
mmm | 16位寄存器 |
000 | DS:[BX+SI] |
001 | DS:[BX+DI] |
010 | SS:[BP+SI] |
011 | SS:[BP+DI] |
100 | DS:[SI] |
101 | DS:[DI] |
110 | SS:[BP] |
111 | DS:[BX] |
Table 4寄存器字段(rrr)的分配
rrr | w=0 | w=1 |
000 | AL | AX |
001 | CL | CX |
010 | DL | DX |
011 | BL | BX |
100 | AH | SP |
101 | CH | BP |
110 | DH | SI |
111 | BH | DI |
Table 5 对段寄存器的寄存器字段(rrr)的分配
rrr | 段寄存器 |
000 | ES |
001 | CS |
010 | SS |
011 | DS |
对oo字段的解析如下。当oo为00的时,mmm索引存储器有点变化。当mmm为110b时,并不是按照表3来索引SS:[BP],而是DS+16位偏移量,其余情况则是按照表3,偏移量为0。当oo为01时,偏移量为8位有符号数。当oo为10时,偏移量为16位有符号数。根据oo和mmm来计算内存地址的过程如下。
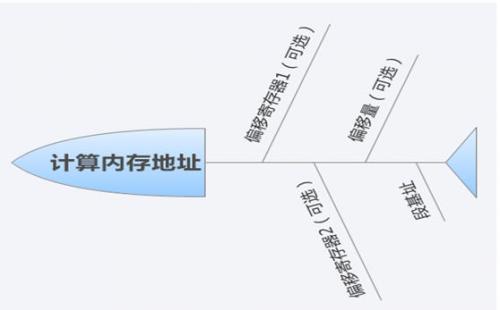
图 37 计算内存地址
rrr字段的实现。当w为1时,rrr对应的是16位寄存器,可直接映射到MIPS寄存器的索引值。当w为0时,rrr对应的是8位寄存器,需要对其重新标号,将AL作为0开始标号。代码实现中,寄存器对应的宏如下,其中包含了段寄存器。
#define _X86_AL 0
#define _X86_CL 1
#define _X86_DL 2
#define _X86_BL 3
#define _X86_AH 4
#define _X86_CH 5
#define _X86_DH 6
#define _X86_BH 7
#define _X86_AX _MIPS_S0 // 0 16
#define _X86_CX _MIPS_S1 // 1 17
#define _X86_DX _MIPS_S2 // 2 18
#define _X86_BX _MIPS_S3 // 3 19
#define _X86_SP _MIPS_S4 // 4 20
#define _X86_BP _MIPS_S5 // 5 21
#define _X86_SI _MIPS_S6 // 6 22
#define _X86_DI _MIPS_S7 // 7 23
#define _X86_CS _MIPS_T4 // 8 12
#define _X86_DS _MIPS_T5 // 9 13
#define _X86_ES _MIPS_T6 // 10 14
#define _X86_SS _MIPS_T7 // 11 15
#define _X86_IP _MIPS_T8 // 12 24
8086二进制机器码的主要字段已解析,还有个别字段。
Table 6 其他字段
字段 | 说明 |
d | 运算方向 |
w | 是否为字 |
s | 是否符号扩展 |
disp | 位移量 |
data | 数据,如立即数 |
翻译时将二进制机器码拆分成各个字段,然后根据其语义生成对应的MIPS指令。一条8086指令一般要翻译成多条MIPS指令,其中一条为核心指令,其余为辅助指令。如加法指令中,将内容移出至辅助寄存器都是辅助指令,最终的加法是核心指令。一般,核心指令对应MIPS的一条指令,因此,可将其抽象出来,实现函数如下。
/**
* x86运算与mips对应关系
*/
int _keyGenerate(int type, int rt, int rd, int **target) {
int instruction;
switch (type) {
case _X86_ADD0:
instruction = _gen_add(rd, rt, rd);
break;
case _X86_AND0:
instruction = _gen_and(rd, rt, rd);
break;
case _X86_OR0:
instruction = _gen_or(rd, rt, rd);
break;
case _X86_SUB0:
instruction = _gen_sub(rd, rt, rd);
break;
case _X86_XOR0:
instruction = _gen_xor(rd, rt, rd);
break;
case _X86_MOV3:
instruction = _gen_add(rt, _MIPS_ZERO, rd);
break;
case _X86_CMP0:
instruction = _gen_sub(rd, rt, _MIPS_ZERO);
break;
default:
break;
}
*(*target)++ = instruction;
return instruction;
}









评论