基于内容的音频检索系统的前端抗噪技术

3.2 系统抗噪算法的确定
在基于内容的音频检索系统中,用户通过哼唱等方式输入检索信息,基于单麦克风输入的单通道语音增强算法是一种简便、实用的形式。变换域语音增强算法可充分利用变换域中语音与背景噪声较其在时域中更为显著的特征区别,且能有效消除语音信号在时域中存在的相关特性,因此其对带噪语音的增强效果要优于时域语音增强算法。因此系统适合采用谱减法、听觉掩蔽算法、维纳滤波方法、信号子空间算法。
维纳滤波法能改善平稳段的谱估计,残留噪声类似于白噪声,降低音乐噪声的干扰,但算法复杂度较大,适用于对实时性要求不高的场合。听觉掩蔽算法可减少不必要的语音失真,实际应用中常只能用带噪语音估计掩蔽阈值,则估计结果误差较大,对噪声估计要求较高。信号子空间算法能有效去除带噪语音中的背景噪声,使语音的质量和可懂度都有较大提高,但计算量较大。谱减法算法简单,算法复杂度低,实现较容易,能够最大程度上满足实时性要求,但会引入较大音乐噪声,适合在平稳噪声环境和对实时性要求较高的场合使用。由于本系统为实时检索系统,对实时性和快速性的要求较高,因此这里采用谱减法。
4.1 谱减法的基本原理
谱减法就是在频域将噪声的频谱分量从带噪语音信号的频谱中减去。其基本思想是:在假定加性高斯噪声与短时平稳的语音信号独立的条件下,从带噪语音信号的功率谱中减去噪声的功率谱,从而得到增强后较为纯净的语音频谱。其基本原理框图如图2所示,图1中,s(n)表示纯净语音,d(n)表示加性噪声,r(n)=s(n)+d(n)表示带噪语音信号,Yk和Sk(k=0,1,2…)分别表示带噪语音信号和纯净语音的频谱系数,λn(k)表示噪声的功率谱系数。
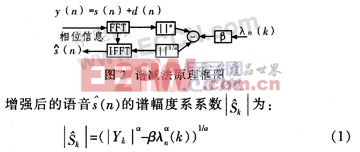
式中,α和β为参数。当α=1,β=1时,为幅度谱减法形式。当α=2,β=1时,为功率谱减法形式。
该谱减法称为传统谱相减法。它基于人耳对声音相位不敏感特性,从含噪语音中减去估计噪声而达到语音增强的目的,直观简单,但容易产生“音乐噪声”,因此实际应用中常采用谱减法的改进算法。
4.2 谱减法的改进算法
用功率谱减法处理语音信号后,在频域中仍残留有噪声,要滤除或减少这些噪声,可适当的多减去噪声分量,使残留噪声在幅值上减少,从而降低噪声的影响,即过减法。此时式(1)取β>1,这样语音失真可能会增大。因此,通过噪声估计来调整和确定β的取值。β值的取值原则:对信噪比低的带噪语音,噪声的方差大,β可适当大些;对信噪比高的带噪语音,β取值则可小些。因为噪声谱的估计是平均值,所以当前帧的噪声谱实际上与估计值有偏差,因此,经谱减法计算的语音谱值可能是负值,一般则设结果设为零,即采用半波整流法,还可采用残余噪声衰减法,噪声残留的幅值介于零和整个非语音活动期最大噪声残留幅值之间,由于残留噪声的随机性,在每个频点上其振幅值随不同分析帧而随机波动,因此在给定频点上通过用相邻帧的频点振幅最小值代替当前帧的振幅而压缩残留噪声。这样就形成改进型谱减法的系统,能有效实现前端减噪。
5 结束语
基于内容的音频检索技术适应性更强,具有广泛的应用价值,具有噪声鲁棒性的检索系统在实际应用中不可或缺。本文给出一个将音频增强和音频检索系统级联的抗噪声音频检索系统,从不同角度分析语音增强算法,并通过比较选取谱减法作为基于内容的音频检索系统的前端抗噪技术,同时给出谱减法的改进算法。




评论