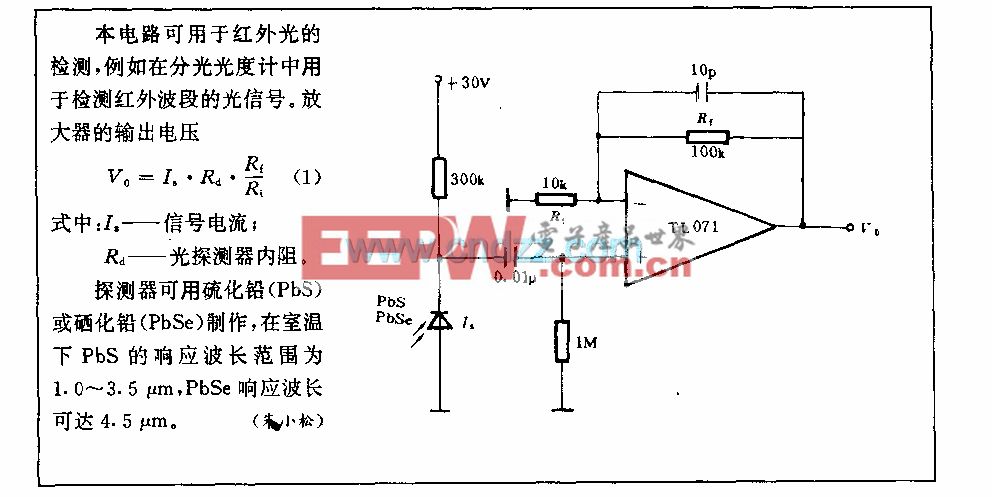
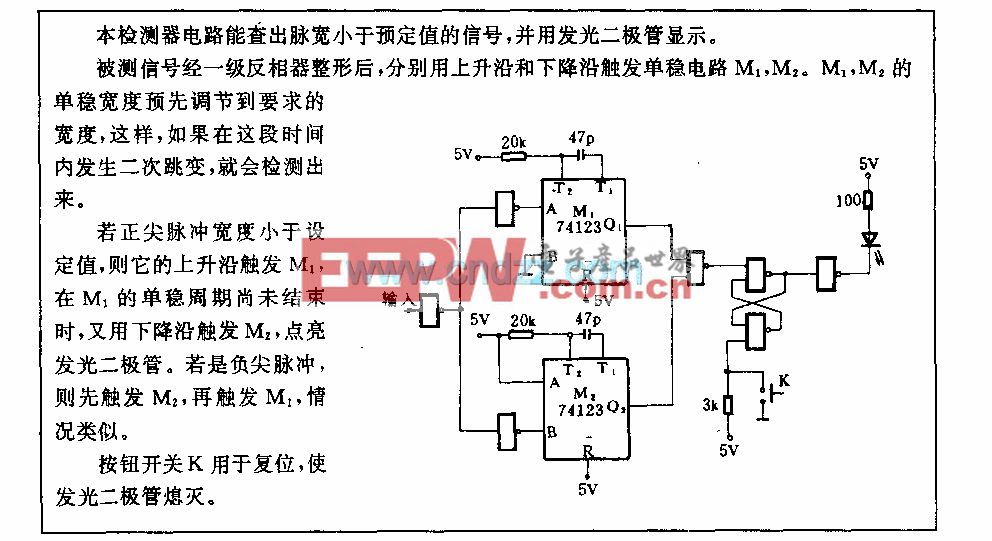
赛灵思姚颂:数字AI芯片进步趋缓,颠覆式创新难 | GTIC2020

在峰会下午场,赛灵思人工智能业务资深总监、前深鉴科技CEO姚颂发表了题为《AI芯片:新格局与新出路》的演讲。
从两年前登台GTIC 2018峰会至今,姚颂经历了全球FPGA龙头赛灵思并购深鉴科技、AMD收购赛灵思两个大事件,此次以全新身份出席GTIC峰会的姚颂,不再作为一家创业公司的代表,因而从相对更为中立的角度输出对AI芯片行业的看法。在姚颂看来,目前数字AI芯片进步趋缓,颠覆式创新难,AI芯片最重要解决的是宽带不足的问题,软件生态才是AI芯片的核心壁垒,他认为未来AI芯片行业最终将会形成“云端相对统一,终端相对垂直”的竞争格局。以下为姚颂演讲实录整理:
AI和芯片互相需要,算力仍有很大提升空间
姚颂认为,AI和芯片紧密相连,AI需要芯片,芯片需要AI。从背景上来讲,例如反向传播等算法在上世纪80年代就已经出现了,现在的一些神经网络与上世纪90年代Yann LeCun教授做的手写数字识别几乎没有本质上的区别,由此可见很多算法在上世纪已经全部具备了。直到最近几年,行业内才感觉到AI的爆发,才感觉到芯片有这么强的需求。2012年以后,业内在算法方面看到突破,看到深度学习能够发挥很大的作用。其中有一个原因在于,英伟达当时在2017年、2018年着力推进生态系统,搭了很多芯片,但芯片的性能并没有太多实质性的增长,这令英伟达有一段时间陷入低谷中。在这个过程中,英伟达更换了一位首席科学家,最终等到了春天。有一个很明显的例子,2012年谷歌的吴恩达和Jeff Dean做猫脸识别项目,用了1000台服务器、16核CPU,同期ImageNet用更少的服务器完成了相同的事情。至此,人们开始充分把深度学习随着数据增长性能越来越好的特点发挥出来。人工智能是将算法、数据和算力结合起来才有今天,而不是单独一点就可以推进的,因此如今人工智能的发展要感谢各种基础设施、网络、存储、计算等的进步。另一方面,整个半导体行业的进展由新的应用驱动和引领。比如最开始的雷达,后来的大型机、小型机、Mobile,现在的AI、IoT,这些行业都有很大的新的应用需求,也因此需要做新的芯片满足这些行业的需求,这也引领了AI芯片的出现。2012年Learning出现一些突破,2014年旷视、商汤等公司成立,最近AI在很多领域都有突破,在人脸识别、自动驾驶等领域也有了非常多的应用,行业对芯片有了更大更新的需求,因此目前也有不少AI芯片出现。
从2012年到2020年,从AlexNet到最新的ImageNet,过去8年里,AI芯片算法效率提升了44倍,同样实现90%的精确度,计算量只有原来的1/40,而计算性能需求却翻了几十万倍甚至数百万倍。以AlphaGo Zero举例,该算法用了1750亿个参数,有非常庞杂的神经网络,对算力的需求还需要非常多倍数的提升。因此当前业界对AI芯片的算力需求还有很大的提升空间,绝不仅仅是现在看到很多公司出来做AI芯片,这个事情就结束了。
AI芯片最需解决的是宽带问题
紧接着,姚颂谈及对行业现状的看法。他说,AI芯片这个词用得特别泛,AI领域本身就特别宽泛,有一小部分才是机器学习,机器学习中的一小部分才是深度学习,深度学习天然切分为训练和推理两个阶段,其中有数不过来的各种神经网络。一个AI芯片可以指代的东西有很多,因此这是一个很宽泛的概念,按稍严格的分类,它可以分成训练、推理两个阶段,以及云端、终端两个应用场景。大家目前基本不在终端做训练,因此终端的场景象限基本是空的。
AI芯片核心解决的是什么问题?去堆并行算力?实际并不是。谷歌TPU第一代的论文中写道,其芯片最开始是为了自己设计的GoogLeNet做的优化,CNN0的部分就是谷歌自己设计的Inception network,谷歌设计的峰值性能是每秒92TeraOps,而这个神经网络能跑到86,数值非常高;但是对于谷歌不太擅长的LSTM0,其性能只有3.7,LSTM1的性能只有2.8,原因在于它整个的存储系统的带宽其实不足以支撑跑这样的应用,因而造成了极大的算力浪费。
AI芯片最重要解决的问题核心是带宽不足的问题,其中一种最粗暴且奢侈的方式就是用大量的片上SRAM(静态随机存取存储器),比如原来寒武纪用36MB DRAM做DianNao,深鉴科技曾用10.13MB SRAM做EIE,TPU采用过28MB SRAM。而将这种工程美学发挥到中最“残暴”的公司,叫做Cerebras,它把一整个Wafer只切一片芯片,有18GB的SRAM,所有的数据、模型都存在片上,因此其性能爆棚。当然这种方式是非常奢侈的,Cerebras要为它单独设计解决制冷、应力等问题,单片芯片的成本就在1百万美元左右,对外一片芯片卖500美元,这一价格非常高昂。因此业内就需要用微架构等其他方式解决这一问题。业内常用的有两种解决方式:一是在操作时加一些buffer,因为神经网络是一个虽然并行,但层间又是串行的结构。把前一层的输出buffer住,或把它直接用到下一层作为输入。二是在操作时做一些切块,因为神经网络规模比较大,每次将它切一小部分,比如16X16,把切出来这一块的计算一次性做完,在做这部分计算的时候同步开始读取下一块的数据,让这件事像流水线一样串起来,就可以掩盖掉很多存储、读取的延迟。现在在数字电路层面,业内更多在做一些架构的更新,根据不同的应用需求做架构的设计。
数字AI芯片颠覆式创新难
在谈到AI芯片产业特点时,姚颂说,首先AI芯片的概念非常宽泛,所以它并不一定是特别难的事。
设计一颗特别通用的芯片很难,设计CPU和GPU同样很难,但是如果只做某一颗芯片,只支持某一个算法和某几个算法,其实并不太难,尤其是对算力的需求很低的时候,技术难度就没有那么大了。以至于现在对于一些简单的神经网络的加速,直接付钱给芯原微电子、GUC等机构,都可以帮助做前端定制。因此对于AI芯片还是要辩证看待,不同的东西难度也不同。第二,高集成度对于终端市场来说非常重要,这是所有做AI起家的公司都会认识到的一点。举例来说,如果厂商想要将AI芯片做到摄像头里面,ISP怎么做、SoC谁来做?将AI芯片做到耳机里面,是语音唤醒的AI部分最终集成蓝牙做成SoC,还是蓝牙的部分集成AI做成SoC?这些都是要考虑的问题。对于终端市场来说,一定是高集成度的方式比分立器件的方式占优势,所以对于终端市场一定要考虑全面,而不能仅仅考虑AI这一个IP。第三,软件生态才是AI芯片的核心壁垒。英伟达创始人兼CEO黄仁勋最近开发布会时说,英伟达已经有180万的开发者、30万个开源项目,99.99%的初学者在学AI时一定会买一块GPU,下载一些Github上的开源项目做试验。这是英伟达最终的一个护城河,它会有源源不断的开发者加入,开发者又会为生态贡献新的项目,如果开发者没有达到一定数量,则很难突破AI芯片的生态壁垒。姚颂说,这与滴滴、淘宝以及其他互联网平台是一个逻辑,一边是商家一边是用户,一边是开发者一边是使用者,这是一个闭环软件生态的逻辑,是最核心的壁垒。在单纯的数字芯片领域、单纯的学术研究做微架构迭代的领域,数字集成电路领域从2016年开始至今没有见到特别大的创新。
上图中显示的是从2016年至2019年的AI芯片能效指标变化,“方形”是实际量产的产品。这个图越往上代表性能越好,越往右是功耗越高,因此在这张图中,越偏向左上角意味着性能越好。而实际上大量的“方形”都落在了图的右上角,处于1~10TOPs/W的两条线之间,现在性能比较好的产品基本上在1~2TOPs/W的区间内,这几年在量产级别上没有见到特别大的变化。行业内有很多工程在往产品方向走,但是通用的微架构迭代的进步已经趋缓。此外,姚颂一直在关注的一个重点在于,芯片越来越贵,导致了一个较大的问题:业内原来很期待在行业中出现一个“破坏性创新”的事,也就意味着想要用很低廉、便捷的方式实现原来高端产品的能力。比如业内希望AI芯片以低价、便捷的方式实现GPU的功能,而现在看起来,实现这一愿景很困难。在如今所处的时间点,摩尔定律还没有死掉但是越来越贵。一颗7nm芯片的流片需要3000万美元左右,再加上IP、人力的成本,甚至需要大几千万甚至是上亿美元,需要卖出很大的量才能收回成本。对于初创公司来说,这是一个难点。
有些芯片公司,比如壁仞科技,融了很多资金,能够做两颗、三颗甚至更多芯片;而有的公司如果没有资金,则无法参与到行业正面战场的竞争中来。这个市场已经发生变化,随着摩尔定律的变化,在正面战场上,我们得想一些其他的办法,可能不能单纯依靠架构的优势取得几倍的性能提升,业界也需要找到一些新的底层技术迭代。比如做存内计算的知存科技就属于这一类,它将计算和存储放在一起,将计算放在Flash中,就可以减少存储的搬运,突破卡在存储的瓶颈;再比如法国有一家叫UpMem的企业把计算放到DRAM中,还有比如普林斯顿大学教授的小组把计算放到SRAM中。另一种技术路线,光计算,也是业内非常看好的方向。用两束光的光强表示两个数值,通过一个干涉仪发生干涉行为,它出射的强度就是两个光强相乘,再乘以他们相位差的cos(余弦),这样就相当于用光的干涉直接完成了乘法,这种操作速度很快、功耗也很低,但也有很大的问题。因为所有的物理器件都不是理想的器件,光每经过一个干涉仪可能要损耗千分之一的强度,如果想要做一个64X64的阵列或是128X128的阵列,每做一个计算的过程中,每束光要通过几百个干涉器,数值就变了。目前国际最好的水平也只能在64X64阵列上保证8bit信息量是不变的,因此这种方式无法在高精度、大阵列的要求下施行,也从而没办法实现特别大的性能,因此这也是一种还在开发中的路线。
云端统一、终端垂直的新格局
放眼AI芯片未来的新路线和新格局,姚颂认为,一方面,行业短期内不用太为新的技术路线担忧,在3~5年内数字集成电路依旧是主流,光计算完全完善还需要时间。另一方面,如今被多次提及的量子计算,距离商用的阶段还很远。现在全球最好的做量子计算的水平能达到50~60 qubit,如果想用它来形成分子模拟等简单的应用,大概需要300~400 qubit,还有五年左右的时间要走。如果想用新技术实现通用的做法,比如量子计算的解密AES,按照现在的算法,大概需要300万个qubit才能完成。因此姚颂不认为量子计算在20年内能在大范围应用中占据较大优势,短期内,产业还是以数字集成电路为主。这其中也有不同的路线,其中一个在于,有很多紧密结合应用的芯片出现了,换句话说,很多芯片公司的客户开始做芯片了。比如百度和三星合作研发了14nm工艺“昆仑”芯片,阿里开发了“含光800”深度学习NPU,还有很多计算类芯片的开发计划,包括字节跳动、腾讯、快手等都投资或孵化了相关的芯片公司。这其实是对第三方芯片公司的冲击,也确实是未来行业发展的重要路径,当应用更明确的时候,芯片的设计难度就会相应降低。云端市场现在看起来可能是最大的单一市场,但竞争确实相对激烈。第一,很多互联网公司自己在做云端市场;第二,英伟达这样的巨头占了云端市场绝大部分的市场份额;第三,英特尔收购了Habana,AMD与赛灵思走到一起,还有很多巨头公司想挤入这一市场;第四,有很多创业公司正准备进入这一市场。云端市场的接口相对统一,需求相对统一,需要的通用性非常高,最后可能会是一个竞争激烈但最终走向相对统一的市场。在终端市场,有很多可以做的事情。举例来说,小蚁科技创始人达声蔚创立了芯片公司齐感科技,面向终端小摄像头做加AI识别的芯片,售价仅几元钱一个,他们在收入上已经做得不错。在不同的市场,如果厂商能够做到高集成度,并能够完整满足这个市场方向的需求,实际上每个方向都是足够能支撑1~2家上市公司的。其中不同的场景有不同的需求,差异很大。比如在无线耳机市场,厂商要做的是一个简单的语音唤醒,要集成蓝牙;如果厂商要做智能摄像机,则要做的是CNN,这就与简单的语音唤醒所需要的加速完全不同。因此必须把场景、SoC都定义清楚,集成度做高,满足一整个行业方案的需求,这就做得非常垂直。
在姚颂看来,最终行业的格局上,云端还是需要相对统一,如果创业公司要进入这一领域,需要拿到非常多的资源,才能参与到“正面战场”的竞争。
在终端上,不同的垂直领域都非常有机会,比如车、智能视频、智能语音等领域,这要求厂商做得非常深,从算法、软件、芯片、硬件上使整个方案全部打通,只有这样才能在这个市场上形成比较强的竞争力。最终,AI芯片领域会形成云端相对统一,终端相对垂直的格局。以上是姚颂演讲内容的完整整理。除姚颂外,在本届GTIC 2020 AI芯片创新峰会期间,清华大学微纳电子系尹首一教授,比特大陆、地平线、燧原科技、黑芝麻智能、壁仞科技、光子算数、知存科技、亿智电子、豪微科技等芯片创企,Imagination、安谋中国等知名IP供应商,全球EDA巨头Cadence,以及北极光创投、中芯聚源等知名投资机构,分别分享了对AI芯片产业的观察与思考。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。