基于SoPC的实时说话人识别控制器

1 算法简介
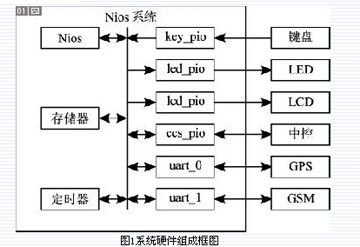
说话人识别系统主要实现建模及识别两方面功能。建模功能提取语音的特征参数并存储起来形成用户模板。识别功能提取语音的特征参数,与模板参数进行匹配,计算其距离。系统框图如图1所示。本文采用改进的DTW(Dynamic Time Warping)算法和LPCC(Linear prediction cepstrum coefficients)特征参数。
1.1 LPCC算法
(1)分帧:语音信号具有短时平稳性[1],因此先将其分帧,再逐帧处理。
(2)有效音检测:有效音检测基于短时能量和短时过门限率两个参数。判决时采取两级判断法:若短时能量高于高门限则判为有声;若低于低门限则判为静音;若介于两者之间,则再判断其过门限率是否高于过门限率门限,若满足则判为有声,否则为静音。
(3)加窗:加窗可滤去不需要的频率分量,同时有利于减少LPCC算法在帧头及帧尾处的误差。本设计采用汉明窗,其表达式如下:

1.2 改进的DTW算法
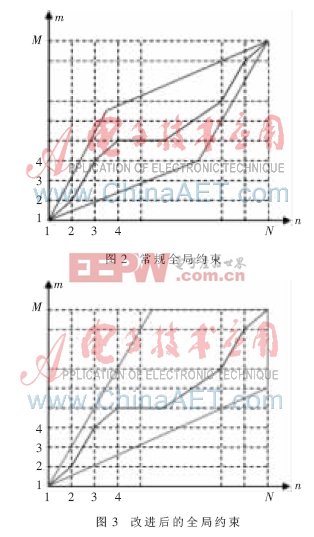
1.2.1 全局约束
图2和图3中,横轴为测试语音参数,纵轴为模板参数,单位为帧。算法以测试语音为基准逐帧进行。如图2,传统的DTW算法中,测试参数长度无法预知时全局约束便无法确定。图3为改进后的DTW,可在未知测试参数长度的情况下进行全局约束,配合帧同步算法,便于算法的实时处理。
1.2.2 局部约束
得到当前距离后便要进行前向路径搜索。n=1指定与m=1匹配。从n=2开始,每个交叉点(n,m)可能的前向路径为(n-1,m)、(n-1,m-1)、(n-1,m-2),选出其中最小者作为当前点(n,m)的前向路径,并将该点的累加距离和加上其当前距离作为当前点的累加距离。最终在n=N处可得到若干个累加距离,选其最小者为最终匹配结果。
1.3 Matlab仿真
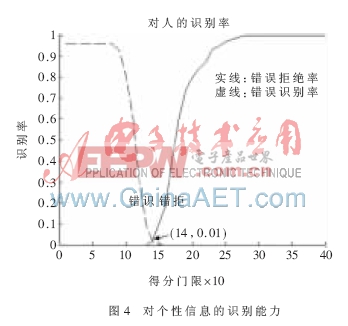
1.3.1 实验1:对个性信息的识别能力
实验1的目的在于观察算法对于话者个性信息的识别能力,实验用的语音均为各话者对正确词“开门”的发音,以避免不同单词带来的影响。实验结果如图4所示,系统的等错误率(EER)为0.01,即当错识率为0.01时错拒率也为0.01。
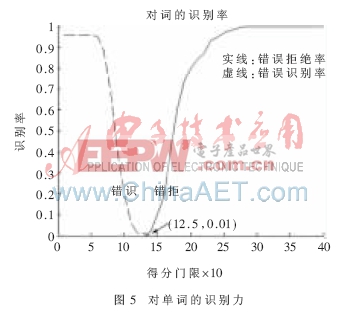
1.3.2 实验2:对语意信息的识别能力
实验2的目的在于观察识别算法对于语意的识别能力,实验用的语音均为同一话者对正确词及错误词的发音,以避免因不同话者带来的影响。如图5所示,在门限为1.25时得到系统的等错误率(EER)为0.01。比较实验1、实验2的结果可知,算法对语义的识别能力和对话者个性信息的识别能力相近。
1.3.3 实验3:综合测试
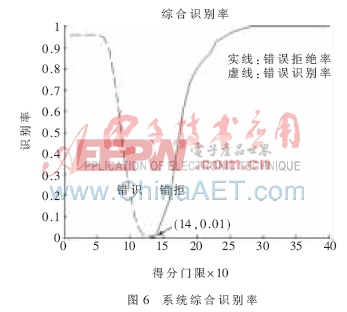
实验3综合考虑了话者的个性信息及语意信息。如图6所示,在门限为1.4时,得到系统的等错误率为0.01,也即此时系统的正确识别率为99%,同时存在1%的错误识别率。
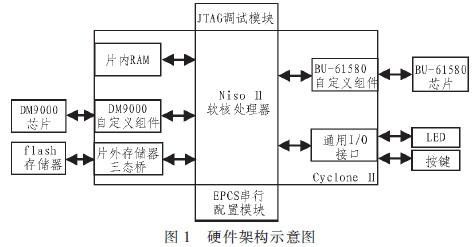
2 SoPC系统构建
(1)CPU设置。NiosII core选定为NiosII/f。使能嵌入式硬件乘法器。复位地址设为cfi_flash,异常向量地址设定为ssram_2M,在custom instructions中添加用户自定义指令floating Point Hardware。
(2)定时器设置。本设计使用了两个定时器。Timer用于产生内部中断采集语音样点,设其计时周期为125 μs(对应采样率8 kHz)。Timer_stamp用于插入时间标签,定时周期采用默认值。
(3)其他外设。NiosII核中还包含以下外设:片上RAM/ROM、FLASH、SDRAM、SSRAM、按键、开关、LED、音频模块、七段数码管、LCD。
3 软件流程
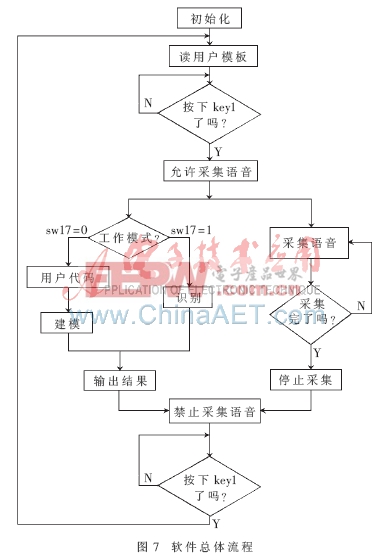
总体工作流程如图7所示。系统首先初始化,然后读出模板数据,等待用户按下按键。在此期间,用户应设置好系统工作模式(建模或识别)及话者代码。然后按下按键开始以中断方式采集语音,并运行函数主体。
识别部分流程如图8所示。函数首先判断语音是否已经采集完毕及LPCC算法是否已经进行到最后一帧,若同时满足则结束运算,否则继续运行。若当前帧为有效音,则计算出其LPCC,并调用DTW子函数,针对各模板分别计算距离得分。运算完所有语音帧后,便可得到测试语音对各模板的最终得分,取其最大者记为当次得分。若该得分大于得分门限,则识别通过;否则予以拒绝。
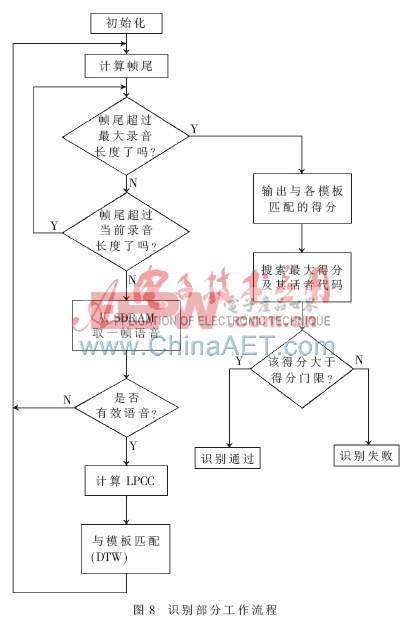
建模部分流程的前半部分与识别过程类似,不同之处在于建模过程只调用了LPCC算法。算法完成后,系统将LPCC矩阵写入对应的Flash地址空间存储。
4 软硬件协同设计与优化
4.1 软件设计与优化
(1)将数据缓存至SDRAM。最初的程序设计中使用数组存储大型变量,后来改为将这些数据缓存于SDRAM中。改进后,在板运行速度无明显改变,但NiosII软件的运行速度及稳定性得到了提高。
(2)用float数据类型代替double。最初的程序大量使用了双精度数据类型,但后来发现单精度浮点型已经可以满足要求,因此将数据类型改为单精度浮点型(float),使得程序运行速度提升了一倍。
(3)用指针方式访问数组。改用指针的方式访问数组改善了程序的执行效率,运行速度有一定提升。
(4)用读表法获取汉明窗函数。最初的程序是通过运算公式的方式得到窗函数的各个样点值的,后改用读表法,使得加汉明窗这一步骤耗时减少了98.7%,整个LPCC运算耗时因此减少了59.3%。
(5)语音数据存储为float类型。最初的设计中,系统采集到原始语音数据后直接将其存储起来,后来改为将数据解码后再存储,使得LPCC中取语音部分的时间由888 μs降至98μs。
4.2 硬件设计与优化
(1)用定时器中断方式采集语音。最初的设计中,系统必须在采集完所有语音数据之后才能对其进行处理。后改用中断方式采集语音,则可实现每采集满一帧语音数据便进行处理,极大地提升了处理速度。
(2)添加用户自定义浮点指令。语音信号处理过程涉及大量单精度浮点型数据的运算,因此在CPU中添加浮点指令。加入浮点指令后,系统耗时降低了90%以上。
本设计在算法上充分利用了DTW算法的特点,既能识别语音内容又能区分说话人,很好地完成了文本有关的说话人识别功能。同时对识别算法进行帧同步处理,为算法的实时实现打下基础。本设计在实现时采用软硬件协同设计方法,在软件和硬件上进行设计和优化,使得设计有很好的实时性。
作品的实际测试情况是:选取门限为1.5时,系统的错识率可降至0%,此时正确识别率为90%,还有10%的拒识。识别时系统的响应时间是8.5 ms。


评论