基于龙芯3B的H.264解码器的向量化
3 ffmpeg的向量化
3.1 ffmpeg的oprofile测试
使用oprofile对ffmpeg解码视频“问道武当002.mkv”的过程进行测试,测试结果如表2所示。表2列出了各个函数的调用过程以及运行时间所占的比重。而针对ffmpeg解码器进行的向量化工作,则主要是针对oprofile测试结果中执行时间较长、运行比重较大的几个函数的向量化。
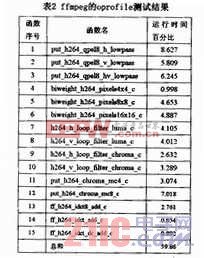
上述函数的执行时间几乎占据了ffmpeg解码器执行时间的60%,因而针对上述几个函数进行向量化,就完全可以达到提升ffmpeg整体解码速度的目的。
3.2 针对龙芯3B的ffmpeg向量化
3.2.1 向量化方法
实现ffmpeg解码器在龙芯3B上的向量化主要是使用龙芯3B扩展的向量指令来改进3.1节中oprofile测试结果中执行时间比重较大的几个函数。而且在向量化的同时,同样可以使用一些优化策略,来提高向量化后的函数的性能。主要使用到的优化方法包括:
(1)循环展开。循环展开是一种循环变换技术,将循环体中的指令复制多份,增加循环体中的代码量,减少循环的重复次数。需要说明的是,循环展开本身并不能直接提升程序的性能。
使用循环展开的主要目的是充分挖掘指令或者数据间的并行性。其中向量扩展指令的使用就是利用了展开后的循环体内数据的并行性;而在展开后的循环内使用指令调度和软件流水技术则是为了充分利用指令间的并行性。
(2)指令调度。循环展开后的循环体内的指令数目增多,因而可以进行指令调度,将不存在操作数相关性和不存在运算部件相关性的指令调度到一起,这样可以充分发挥龙芯3B的流水线性能,从而提高代码在龙芯3B上的执行速度。
除了使用龙芯3B的向量扩展指令和使用上述两种优化方法以外,同样还可以根据具体函数的特点,使用其他一些优化方法进行优化,比如使用逻辑运算和移位运算来代替乘法运算等。针对每个函数的向量化优化在3.2.2小节中介绍。
3.2.2 针对具体函数的向量化
3.2.1小节概述了向量化时用到的一些优化方法,本节则针对oprofile测试中比重较大的几个函数进行有针对性的优化。
对于表2中的函数,我们可以根据函数名将其分类,函数命名类似的函数基本上都可以使用类似的优化方法。
(1)简单向量化。对于1号和2号函数的优化,本文都采用了使用移位运算来代替乘法运算的策略,并且针对循环内部运算的有界特性,使用饱和向量运算来改进。不过对于2号函数的访存操作,由于存在着数据非对齐的情况,因而使用额外的向量指令对数据进行打包和回写。而3号函数则是1号和2号函数的混合,因而对1号和2号函数的优化间接提升了3号函数的性能。
而对于4号、5号和6号函数,本文仅对其内层循环使用了循环展开和指令调度策略,就能够取得不错的运算效果。
同样,对于11和12号函数也可以比较直观的进行向量化,在此就不做详述了。
(2)间接向量化。而对于比较难于向量化的7号和8号函数,本文分别采用了使用掩码和使用矩阵转置运算的策略来间接实现向量化。
其中针对函数h264 v loop filter luma的C语言实现中有很多判断语句的问题,本文使用构建掩码的方式来消除这些判断语句。

以图1(a)中的循环为例介绍掩码的构建。而图1(b)所示为代替该循环的向量指令。具体的运算结果如图1(c)所示:将p向量(数组)和q向量做饱和减法(结果为负的都置为0),得到的结果向量如Vsub所示。使用Vsub与零向量进行比较来设置掩码:结果为真,掩码值为0xFF;反之,结果为假,掩码为0。最后将掩码值与p向量进行与操作,就可以得到该循环的运算结果。
使用构建掩码的方法来消除判断语句,不但减少了由判断引起的时间开销,而且重要的是间接将循环进行了向量化,提高了函数性能。而对于9号和10号函数,可以使用同样的方法来改进。
而对于8号函数,由于运算处理的是连续的数据,因而无法进行向量化。使用矩阵转置的方式,将数据重新打包后,就可以进行相应的向量运算。

对于图2(a)中的运算,原始计算是P向量内部的运算,因而无法向量化,我们用向量指令将p向量转置为q,其中q0存放p中标号为1的数据,q1存放P中标号为2的数据,依此类推。转置得到的q向量就可以用图2(b)中的向量指令运算,得到的运算结果与原来的运算相同。
对于13~15号函数的优化,同样使用到了上面的转置方法。而4.1节的测试结果则说明了各个函数的优化效果。




评论