一种基于树状结构的新型解码器
摘要:介绍了一种新型解码器,能够在数据包中解码出期望KPI的值。在机站测试等过程中,需要查看一些KPI值,而所有KPI是服务器端以数据包的形式发送到客户端的。解码器首先把各个目标KPI按位与,得到总的目标值m,然后m与树状结构中的非叶子结点以及叶子结点按位与,如果结果值不等于非叶子结点,则跳过其子结点,继续和其兄弟结点按位与,直到找到期望KPI。这种方法不用解码出数据包中的全部数据,即可得到期望的KPI值,简便而又高效,大大提高了工作效率。
关键词:解码器;数据包;树状结构;C++;JAVA
0 引言
计算机网络数据通常是以数据包进行传输的,数据包由报头、负载、报尾等部分组成。在机站测试等过程中需要经常得到大量KPI(Key parameterindicator)的值,而这些KPI是由服务器以数据包的形式发送到客户端的,那么如何在以二进制表示的数据包里面快速而准确地得到期望的KPI的值呢?在此设计了一个高效而实用的解码器,用以快速得到某一字段的KPI值。
1 解码器简介
解码器源代码是一些C++代码,用来解码出数据包对应的KPI的值。在基站、网络等测试过程中经常需要统计各种KPI的值,而相关KPI的值有时多达几十甚至几百个,如果想要在这庞大的数据里面,快速有效地得到一个或者几个KPI的值,普通的方法是把这段码流进行解码得到全部对应的值之后再查找期望的值。这种方法不仅费时费力而且容易出错,在此利用一种树状结构的数据结构设计出了解码特定值的解码器,用以获取期望KPI的值。这种解码器不仅能够帮助工作人员快速得到期望的KPI值,而且减少出错的几率,提高了工作效率。
下面介绍一些名词的含义,消息是指由基本数据类型表示各种KPI及其组成形式的集合。消息定义文件是指用来定义诸如XSD、C头文件、文本文件等消息格式的文件格式。逻辑表是XML格式文件,用来定义一些无法用C头文件描述的逻辑条件。XSD即XML Schema Deftnition,用以规范和验证XML格式的文档。
每条信息对应一个解码函数,用以解码数据包里面对应的二进制流数据,各种解码函数构成了解码器。它不是解码整条消息,而是有选择地解码部分比特流以得到期望的KPI的值,因此它是非常高效的。
端模式(Endian)是指在计算机体系结构中存储信息的不同顺序,分为大端(Big-endian)和小端(Little-endian)。大端指数据的高位存储在内存的低地址中,而数据的低位存储在内存的高地址中,小端则相反。
由于需要解码不同的消息,而不同的消息具有不同的格式,因此和消息对应的解码函数也是不同的,那么就需要根据不同的消息格式生成相应的解码函数。在此每条消息用相应C头文件表示,然后根据C头文件配置对应的逻辑表。以C头文件和逻辑表作为输入,编写Java代码利用Eclipse生成相应的解码函数(解码器)。
软件最终产品为解码器,其为具有解码功能的C++源代码,能够有选择地解码出想要查看的KPI的值。解码器的输入为配置参数、C头文件、逻辑表。配置参数指出了消息的格式、C头文件的路径、逻辑表的路径、生成的解码器的输出路径以及是大端或小端解码等。程序根据C头文件所定义的消息生成XSD文件,其是与C头文件中的结构体一一对应的,然后根据产生的XSD文件、逻辑表以及配置参数生成解码器。其数据流程图如图1所示。
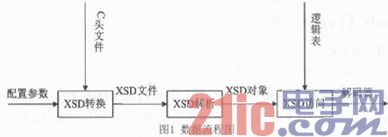
2 编码方法
每条消息都可由相应的结构体表示,这些结构体位于C头文件中,可以写成树状结构的形式。假设某条消息如图2所示,由以下结构体表示:其中A p、B p和C p处于同一层,root为根结构体,包含了A p、B p和C p结构体。基本数据类型包括整形、字符型、位域等,为叶子结点,非基本类型数据包括结构体数组、联合等,为非叶子结点。在此,这条消息可由树状结构来表示,如图3所示,root根结点表示为0000 0000,A结点表示为0000 0001,a1表示为0001 0001;B结点表示为0000 0010,b1表示为0001 0010,b2表示为0010 0010;C[0]表示为00000 100,c1表示为0001 0100,c2表示为0010 0100,c3表示为0100 0100;C表示为0000 1000,c4表示为0001 1000,c5表示为0010 1000,c6表示为01001000。可见root、A、B、C[0]、C[1]为非叶子结点,是非基本数据类型,其余是叶子结点,是基本数据类型。我们称root为A、B、C[0]和C[1]的父结点,A是a1的父结点,B是b1和b2的父结点,以此类推。注意到,每个父结点和其子结点位与()的结果值都为父结点,例如:root(0000 0000)A(0000 0001)=root(0000 0000),A(0000 0001)a1(0001 0001)=A(0000 0001),B(0000 0010)b2(0010 0010)=B(00 00 0010)。由此,若要取KPI b2和c4的值,那么传入的目标值为m=b2 |(位或)c4=0011 1010,让目标值依次与某结点位与(&),如果结果值等于某结点,那么说明某结点的子结点包含或者是目标值,例如m(0011 1010)&B(0000 0010)=B(0000 0010),又已知B是非叶子结点,故B的子结点中必定包含目标结点,然后m依次与b1和b2按位与,mb1 b1,又知b1是叶子结点,故b1不是要解的目标值,则跳过b1,继续解b1的兄弟b2,显然,mb2=b2,又知b2是叶子结点,故b2是要解的目标值,以此可得到c4也为目标值。又mA A,又知A是非叶子结点,故可把A结点以下的子结点跳过不解,以此类推,C[1]及其子结点也可以跳过不解,那么这就大大提高了解码的效率。
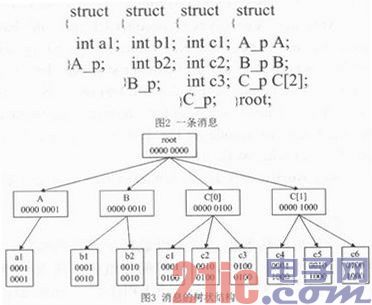
有时候存储信息不需要一个完整的字节,只需要占一个或几个二进制位,这种存储信息的方式称为位域。当消息里面包含位域的时候,由于不同的机器可能是大端或者小端。那么就需要定义是按照大端解码还是按照小端解码。
3 模块设计
系统分为初始化、XSD转换、XSD解析、XSD访问等四个模块。
初始化模块主要进行参数配置,然后开始运行Eclipse生成解码器。需要配置的参数有:消息名称、C头文件路径、逻辑表路径、解码器输出路径、端类型等。
XSD转换模块主要进行C头文件定义的结构体的解析,并生成XSD文件。
XSD解析模块将XSD文件解析成XSD素对象。这里采用DOM方式进行解析XSD文件,DOM(文档对象模型)定义了层次化模型来表示XSD文档,对应XSD中的每一个元素定义一个相应的类与其一一映射。解析时读入整个XSD文件,然后在内存构建一个树状结构,每遇到一个元素就实例化一个元素对象。XSD元素对象分为根元素、结构体元素和叶子元素。根元素为整个XSD文件,如图3中的root,结构体元素为XSD文件的非叶子结点,如图3中的A、C[0]等,叶子元素为XSD文件的叶子结点,其存储了具体的KPI的值,如图3中的a1等。
XSD访问模块的功能是在XSD对象中查询逻辑表中的数据,并生成解码器。
逻辑表主要是用来表示在C头文件中不能表示的逻辑情况,在此有三类常见的逻辑。通常在一个union里面有多个元素,在解码原始数据流时要选择正确的元素,那么,就必须有一个指引元素,其指明了哪一个元素是被选择的。如果这个指引元素是在union外,那么就称其为key out union,相反则称其为key in union。如果我们要解码的KPI是一个变长数组,那么显然在C头文件中是没有办法描述的,在此我们定义一个变量专门用来定义变长数组的长度,称其为variable length array。在某种条件下在数据流中有的数据是没有意义的,那么就需要我们定义一个变量来决定其是否有意义,我们称这样的变量为optional。
4 结束语
针对数据包中的大量数据,解码器利用树状结构的编码规则可以快速找到期望的KPI的值,这种对信息提取的高效性,可以大大提高工作效率,增加效益。此解码器不仅可以单独用来对数据包里面的数据进行提取,也可以和其它软件一起构成一个小型测试系统等。




评论