国内AI芯片百家争鸣,何以抗衡全球技术寡头
对标谷歌 TPU——比特大陆算丰
本文引用地址:http://www.eepw.com.cn/article/201804/377915.htm作为比特币独角兽的比特大陆,在 2015 年开始涉足人工智能领域,其在 2017 年发布的面向 AI 应用的张量处理器算丰 Sophon BM1680,是继谷歌 TPU 之后,全球又一款专门用于张量计算加速的专用芯片(ASIC),适用于 CNN / RNN / DNN 的训练和推理。

BM1680 单芯片能够提供 2TFlops 单精度加速计算能力,芯片由 64 NPU 构成,特殊设计的 NPU 调度引擎(Scheduling Engine)可以提供强大的数据吞吐能力,将数据输入到神经元核心(Neuron Processor Cores)。BM1680 采用改进型脉动阵列结构。2018 年比特大陆将发布第 2 代算丰 AI 芯片 BM1682,计算力将有大幅提升。
百家争鸣——百度、地平线及其他
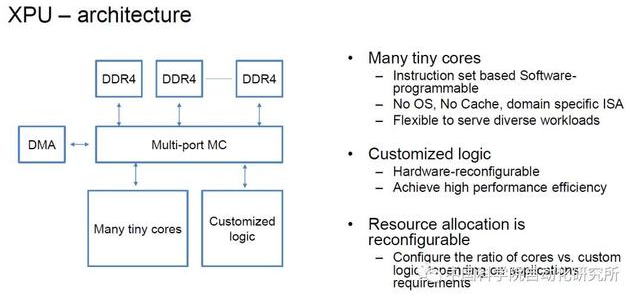
在 2017 年的 HotChips 大会上,百度发布了XPU,这是一款 256 核、基于 FPGA 的云计算加速芯片,用于百度的人工智能、数据分析、云计算以及无人驾驶业务。在会上,百度研究员欧阳剑表示,百度设计的芯片架构突出多样性,着重于计算密集型、基于规则的任务,同时确保效率、性能和灵活性的最大化。
欧阳剑表示:“FPGA 是高效的,可以专注于特定计算任务,但缺乏可编程能力。传统 CPU 擅长通用计算任务,尤其是基于规则的计算任务,同时非常灵活。GPU 瞄准了并行计算,因此有很强大的性能。XPU 则关注计算密集型、基于规则的多样化计算任务,希望提高效率和性能,并带来类似 CPU 的灵活性。
在 2018 年百度披露更多关于 XPU 的相关信息。
2017 年 12 月底,人工智能初创企业地平线发布了中国首款全球领先的嵌入式人工智能芯片——面向智能驾驶的征程(Journey)1.0 处理器和面向智能摄像头的旭日(Sunrise)1.0 处理器,还有针对智能驾驶、智能城市和智能商业三大应用场景的人工智能解决方案。“旭日 1.0”和 “征程 1.0” 是完全由地平线自主研发的人工智能芯片,具有全球领先的性能。
为了解决应用场景中的问题,地平线将算法与芯片做了强耦合,用算法来定义芯片,提升芯片的效率,在高性能的情况下可以保证它的低功耗、低成本。具体芯片参数尚无公开数据。

除了百度和地平线,国内研究机构如中国科学院、北京大学和清华大学也有人工智能处理器相关的成果发布。
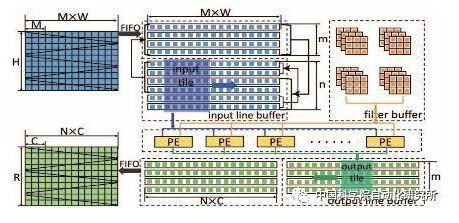
北京大学联合商汤科技等提出一种基于 FPGA 的快速 Winograd 算法,可以大幅降低算法复杂度,改善 FPGA 上的 CNN 性能。论文中的实验使用当前最优的多种 CNN 架构(如 AlexNet 和 VGG16),从而实现了 FPGA 加速之下的最优性能和能耗。在 Xilinx ZCU102 平台上达到了卷积层平均处理速度 1006.4 GOP/s,整体 AlexNet 处理速度 854.6 GOP/s,卷积层平均处理速度 3044.7 GOP/s,整体 VGG16 的处理速度 2940.7 GOP/s。
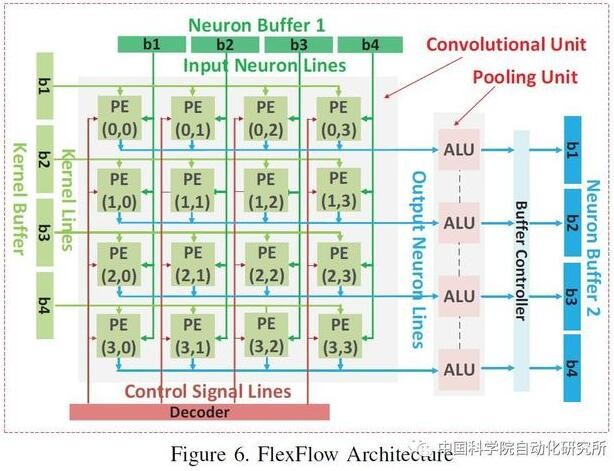
中国科学院计算机体系结构国家重点实验室在顶级会议 HPCA2017 上提出了一种基于数据流的神经网络处理器架构,以便适应特征图、神经元和突触等不同层级的并行计算,为了实现这一目标,该团队对单个处理单元 PE 进行重新设计,使得操作数可以直接通过横向或纵向的总线从片上存储器获取,而非传统 PE 只能从上至下或从左至右由相邻单元获取。该芯片采用了 TMSC 65nm 工艺,峰值性能为 490.7 GOPs/W。








评论