国内AI芯片百家争鸣,何以抗衡全球技术寡头
清华大学微纳电子系魏少军等 2017 年的 VLSI 国际研讨会上提出了基于可重构多模态混合的神经计算芯片 Thinker。Thinker 芯片基于该团队长期积累的可重构计算芯片技术,采用可重构架构和电路技术,突破了神经网络计算和访存的瓶颈,实现了高能效多模态混合神经网络计算。Thinker 芯片具有高能效的突出优点,其能量效率相比目前在深度学习中广泛使用的 GPU 提升了三个数量级。Thinker 芯片支持电路级编程和重构,是一个通用的神经网络计算平台,可广泛应用于机器人、无人机、智能汽车、智慧家居、安防监控和消费电子等领域。该芯片采用了 TSMC 65nm 工艺,片上存储为 348KB,峰值性能为 5.09TOPS/W。
本文引用地址:http://www.eepw.com.cn/article/201804/377915.htm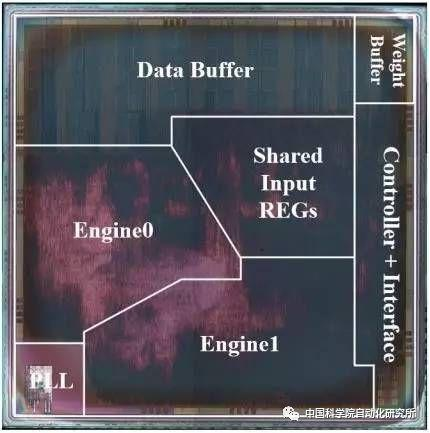
新架构新技术——忆阻器
2017 年清华大学微电子所钱鹤、吴华强课题组在《自然通讯》(Nature Communications)在线发表了题为 “运用电子突触进行人脸分类”(“Face Classification using Electronic Synapses”)的研究成果,将氧化物忆阻器的集成规模提高了一个数量级,首次实现了基于 1024 个氧化物忆阻器阵列的类脑计算。该成果在最基本的单个忆阻器上实现了存储和计算的融合,采用完全不同于传统 “冯 · 诺依曼架构” 的体系,可以使芯片功耗降低到原千分之一以下。忆阻器被认为是最具潜力的电子突触器件,通过在器件两端施加电压,可以灵活地改变其阻值状态,从而实现突触的可塑性。此外,忆阻器还具有尺寸小、操作功耗低、可大规模集成等优势。因此,基于忆阻器所搭建的类脑计算硬件系统具有功耗低和速度快的优势,成为国际研究热点。

在神经形态处理器方面,最为著名的就是 IBM 在 2014 年推出的 TrueNorth 芯片,该芯片包括 4096 个核心和 540 万个晶体管,功耗 70mW,模拟了一百万个神经元和 2.56 亿个突触。而在 2017 年,英特尔也推出一款能模拟大脑工作的自主学习芯片 Loihi,Loihi 由 128 个计算核心构成,每个核心集成了 1024 个人工神经元,整个芯片拥有超过个 13 万个神经元与 1.3 亿个突触连接,与人脑超过 800 亿个神经元相比,简直是小巫见大巫,Loihi 的运算规模仅比虾脑复杂一点点而已。英特尔认为该芯片适用于无人机与汽车自动驾驶,红绿灯自适应路面交通状况,用摄像头寻找失踪人口等任务。

而在神经形态芯片研究领域,清华大学类脑计算研究中心施路平等在 2015 年就推出了首款类脑芯片—“天机芯”,该芯片世界首次将人工神经网络(Artificial Neural Networks, ANNs)和脉冲神经网络(Spiking Neural Networks,SNNs)进行异构融合,同时兼顾技术成熟并被广泛应用的深度学习模型与未来具有巨大前景的计算神经科学模型,可用于诸如图像处理、语音识别、目标跟踪等多种应用开发。在类脑 “自行” 车演示平台上,集成 32 个天机一号芯片,实现了面向视觉目标探测、感知、目标追踪、自适应姿态控制等任务的跨模态类脑信息处理实验。据悉,基于 TSMC 28nm 工艺的第二代天机芯片也即将推出,性能将会得到极大提升。

从 ISSCC2018 看人工智能芯片发展趋势
在刚刚结束的计算机体系结构顶级会议 ISSCC2018,“Digital Systems: Digital Architectures and Systems” 分论坛主席 Byeong-Gyu Nam 对人工智能芯片,特别是深度学习芯片的发展趋势做了概括。深度学习依然今年大会最为热门的话题。相比较于去年大多数论文都在讨论卷积神经网络的实现问题,今年则更加关注两个问题:其一,如果更高效地实现卷积神经网络,特别是针对手持终端等设备;其二,则是关于全连接的非卷积神经网络,如 RNN 和 LSTM 等。
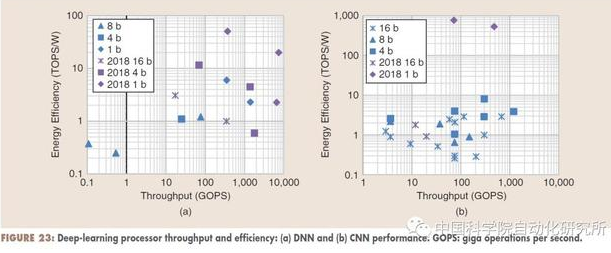
同时,为了获得更高的能效比,越来越多的研究者把精力放在了低精度神经网络的设计和实现,如 1bit 的神经网络。这些新型技术,使得深度学习加速器的能效比从去年的几十 TOPS/W 提升到了今年的上百 TOPS/W。有些研究者也对数字 + 模拟的混合信号处理实现方案进行了研究。对数据存取具有较高要求的全连接网络,有些研究者则借助 3-D 封装技术来获得更好的性能。
总结:对国产人工智能芯片的一点愚见
正如前文所述,在人工智能芯片领域,国外芯片巨头占据了绝大部分市场份额,不论是在人才聚集还是公司合并等方面,都具有绝对的领先优势。而国内人工智能初创公司则又呈现百家争鸣、各自为政的纷乱局面;特别是每个初创企业的人工智能芯片都具有自己独特的体系结构和软件开发套件,既无法融入英伟达和谷歌建立的生态圈,又不具备与之抗衡的实力。
国产人工智能芯片的发展,一如早年间国产通用处理器和操作系统的发展,过份地追求完全独立、自主可控的怪圈,势必会如众多国产芯片一样逐渐退出历史舞台。借助于 X86 的完整生态,短短一年之内,兆芯推出的国产自主可控 x86 处理器,以及联想基于兆芯 CPU 设计生产的国产计算机、服务器就获得全国各地党政办公人员的高度认可,并在党政军办公、信息化等国家重点系统和工程中已获批量应用。
当然,投身于 X86 的生态圈对于通用桌面处理器和高端服务器芯片来说无可厚非,毕竟创造一个如 Wintel 一样的生态链已绝非易事,我们也不可能遇见第二个乔布斯和苹果公司。而在全新的人工智能芯片领域,对众多国产芯片厂商来说,还有很大的发展空间,针对神经网络加速器最重要的就是找到一个具有广阔前景的应用领域,如华为海思麒麟处理器之于中科寒武纪的 NPU;否则还是需要融入一个合适的生态圈。另外,目前大多数国产人工智能处理器都针对于神经网络计算进行加速,而能够提供单芯片解决方案的很少;微控制器领域的发展,ARM 的 Cortex-A 系列和 Cortex-M 系列占据主角,但是新兴的开源指令集架构 RISC-V 也不容小觑,完全值得众多国产芯片厂商关注。








评论