神经网络加速器大战一触即发

随着许多嵌入式系开始变得「智能」且「自主」,以人工智能(AI)神经网络为导向的嵌入式系统市场即将起飞,神经网络加速器大战一触发。..
本文引用地址:https://www.eepw.com.cn/article/201707/362302.htm嵌入式神经网络加速器市场持续升温,从智能音箱、无人机到智能灯泡等越来越多的系统准备在本地执行神经网络,以取代传送至云端进行运算的途径。
Movidius副总裁兼总经理Remi El-Ouazzane日前在接受《EE Times》访问时,将这个成长中的趋势定义为「让事情变得更智能与自主的一场竞赛」。

Remi El-Ouzaane,Movidius副总裁兼总经理Remi El-Ouazzane
英特尔旗下子公司Movidius在上周推出了一款采用USB外形的独立式人工智能(AI)加速器。 El-Ouazzane说,这款名为Movidius神经运算棒(Neural Compute Stick)的AI加速器设计,可轻松简单地插入Raspberry Pi或X86 PC,让大学研究人员、独立软件开发人员与程序增补人员易于为嵌入式系统进行编译、调整以及加速深度学习应用。
Movidius在去年秋天被英特尔收购后,如今已成为英特尔新技术部门的一部份。 Movidius之前曾经开发出业界首款视觉处理器——Myriad 2 VPU。 如今,El-Ouazzane表示,推出这款运算棒的最终目标在于让Movidius VPU成为可在边缘执行神经网络的「参考架构」。
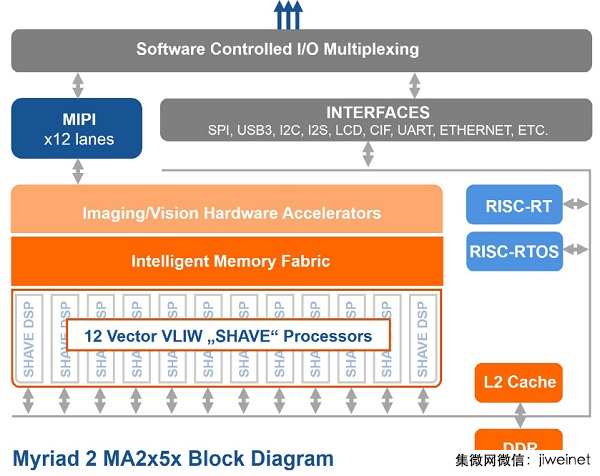
Movidius Myria 2 VPU方块图 (来源:Intel/Movidius)
尽管目标远大,但业界分析师随即指出,Movidius Myriad 2 VPU当然不是嵌入式系统中可在边缘执行神经网络的唯一选择。
催生新产品类别:神经加速器
Tirias Research首席分析师Jim McGregor表示:「从技术上来看,您可以使用任何具有处理组件的开发板,并用于执行一种模型。 例如机器学习(Machine learning)/AI模型已经执行于各种广泛的处理器和SoC了,特别是针对行动领域。 」
高通(Qualcomm)以Snapdragon系列实现的影像辨识可说是最佳的例子。 高通从Snapdragon 820开始采用自家开发的模型,McGregor说:「Snapdragon基本上就是推理引擎」。
具有平行处理组件(如GPU、DSP和FPGA)的处理解决方案非常适于作为推理引擎。 McGregor解释说,许多正在开发中的客制化芯片解决方案都采用可内建于SoC的DSP或FPGA。
Linley Gwennap首席分析师Linley Gwennap对此表示赞同。 他在最近出刊的《微处理器报告》(Microprocessor Report)中写道:高通、苹果(Apple)和英特尔(Movidius)都在「打造一种新的产品类别:神经加速器。 」
Gwennap解释说,对于这些以客户端为基础的加速器需求来自于要求极低延迟的自动驾驶车。 Gwennap在该报告的评论中指出,在本地进行处理的新技术将会开始「渗透至一些较低成本的应用」。 他预测,「在消费装置中,小型的神经加速器可能是SoC中的一个重要区块,就像是绘图核心或图像处理器一样。 几家知识产权(IP)供货商开始提供这一类加速器,期望尽可能地降低额外的硬件成本。 」
Gwennap在《EE Times》的访谈中指出,Movidius Neural Compute Stick对于开发人员几乎没有什么不同。 「对于开发人员来说,这并没什么不起。 典型的PC就能产生至少100GFLOPS,特别是如果它还内建绘图卡,直接在PC上进行开发会更好。 对于需要较低功率处理器的嵌入式系统,高通Snapdragon 835提供超过250GOPS的效能,对于大多数的推理应用来说都够了。 」

不过,Movidius的El-Ouazzane并不赞同这样的看法。
首先,Movidius Neural Compute Stick利用USB让神经网络更易于存取,有利于制造商或程序增补人员用于开发深度神经网络原型或进行调整。
其次是电源效率的问题。 El-Ouazzane指出,Movidius的解决方案可让神经网络在边缘运算时旳功耗小于2瓦(W)。
然后,还有成本的考虑。 El-Ouazzane说:「我认为这是一个杀手级因素。 Movidius Neural Compute Stick要价79美元,可望让神经网络的发展变得『超级普遍』。 」
他预期开发人员能使用Movidius的神经运算平台(Neural Compute Platform)应用程序编程接口(API),「将经过训练的Caffe、前馈卷积神经网络(CNN)输入工具套件中,并进行配置,然后编译成一种可用于嵌入式部署的调整版本。 」
以AI为导向的嵌入式应用?
随着许多嵌入式系开始变得「智能」且「自主」,El-Ouazzane预计以AI为导向的嵌入式系统即将爆发。
但是,不久的将来即将出现什么样的AI装置?
McGregor预测,「我认为在2025年以前,每个人所接触的每一款新系统/平台都将具有某种程度的AI元素,它可能内建于装置本身,或存在于网络、云端,或是分散在其间。 」
他补充说:「它可能就像是用户接口或应用一样简单,或者是像虚拟助理或自主控制般复杂的某种装。 目前已经有许多应用已经导入了AI,包括虚拟助理、搜索引擎、财务建模、与文章写作。..。. 等等。 」
他说:「而在装置上,AI将因各种不同的原因而持续成长,特别是数据的安全、实时互动/处理以及带宽限制等。 然而,在装置上进行训练才是真正的挑战,最终可能需要新的处理模型。 」
英特尔想掌握一切。..
当然,Movidus现在是英特尔的子公司,但其目标并不仅限于有更多嵌入式系统在边缘执行神经网络。 El-Ouazzane将其产品发布架构在英特尔端对端AI产品组合的更大脉络之下。
他指出,英特尔拥有广泛的AI产品组合,并为其提供一整套完整的开发工具和资源。
「无论是在英特尔Nervana云端上训练AI神经网络、优化新兴的工作负载(如AI、、VR和AR),以及使用英特尔Xeon Scalable处理器实现自动驾驶,或是以Movidius视觉处理器技术将AI导入边缘,」英特尔宣称该公司已为下一代AI驱动的产品和服务提供了全面的AI产品组合、工具、训练和部署选择。
然而,Movidus是否真的能在即将变得无所不在的AI嵌入式系统中成为其关键参考架构,目前还不而知。
Tirias Research的McGregor尽管认同Neural Compute Stick是「一款可在新设计中快速评估AI模型训练效能的有利工具,」但他仍指出,「设计人员仍然必须在最后的系统设计时间执行类测试,特别是如果他们并未使用Moviduis的芯片和/或Caffe架构。 」
The Linley Group的Gwennap还认为,Movidius无法达到其目标——实现在边缘运算神经网络的嵌入式系统设计。
区隔推理引擎与训练
Gwennap指出,「值得注意的是,新的AI时代并不会有『参考架构』。 诸如TensorFlow和Caffe等架构将会把软件(神经网络)和硬件分开来。 」他补充说:「映像到Myriad VPU的网络可以轻易地映像到Snapdragon或其他处理器上。 因此,AI处理器将在性能和效率的基础上进行竞争,而不是锁定于指令集。 」
同样地,他也不认同「同样的工具适用于训练和推理」的论点。 Gwennap说:「一旦网络开始接受训练,就可以轻松地部署在支持主流架构的任何平台上。 而且,主流的架构都是开放源码,以避免单一家厂商锁定。 」。
El-Ouazzane看好AI处理器抽取底层硬件的能力,它让设计者可将推论与练训分离开来。 但他重申先前的观点,从长远来看,能够使用相同的工具进行神经网络的训练和部署,才有助于系统设计人员。
他以Movidius的开发蓝图为例表示,未来三年,深度学习的效能预计将会增加50倍。 「为了在不增加功耗的情况下实现这一目标,我们可以在训练方面设计许多架构技巧。 」El-Ouazzane补充说:「当你在斟酌这些技巧时,让学习和推理方面置于同一平台是至关重要的。 」








评论