利用MEMS麦克风阵列定位并识别音频或语音信源

* 意大利米兰大学计算机学系
** 意大利米兰比可卡大学
*** 意法半导体(意大利Agrate)公司
摘要:在过去10年里,以人类语言和音频信号为媒介的人机交互应用在日常生活的作用越来越重要。设备本身必须充分利用不同的功能,才能取得最佳的性能,例如,音频定位、自动语音识别、自动说话人识别等。本文着重探讨取得这些结果所需的算法和完整的嵌入式方案即MEMS麦克风阵列所需的硬件架构。
1. 前言
自动语音识别、语音模式识别和说话人识别及确认等应用对噪声十分敏感,信源定位识别是音频和语音信号捕捉处理应用的一个关键的预处理功能。特别是基于微机电系统(MEMS) [1][2]的麦克风阵列出现后,麦克风阵列音频定位方案引起科研企业和开发人员的广泛关注。
目前业界正在使用MEMS麦克风阵列子系统开发嵌入式音频定位、自动语音识别和自动说话人识别解决方案,声音识别定位是我们识别确认他人身份的基本功能,当我们听到有人讲话时,会将头转向说话人,查看说话人。
音源定位是自动语音识别和自动说话人识别系统的一个重要环节,对于提高语音识别系统的性能至关重要。麦克风阵列可捕捉从不同方向传来的声音,通过算法运算使麦克风指向某一个特定方向,放大从该方向捕捉到的音频信号,同时衰减从其它方向捕捉的音频信号,整个动作就像一个智能麦克风。
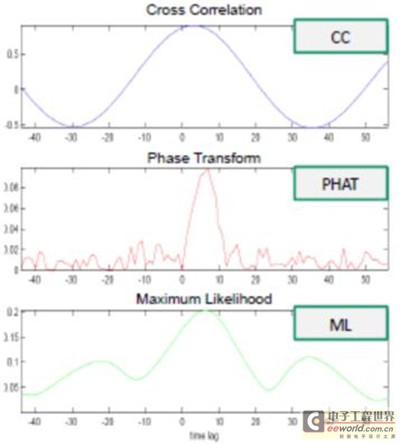
图 1.综合利用麦克风音源互相关性(CC)、相变(PHAT)和最大相似性处理(ML)技术的音源定位
2. 系统框架
整个系统由以下几个子系统组成:音源方向测定、数据融合、自动语音识别和自动说话人确认。其中,音频方向测定子系统基于麦克风阵列,运行三个不同的音频方向估算算法;数据融合子系统负责推断方向,自动语音识别子系统利用传入的音频信号增强主音源信号强度,衰减主音源周围的其它音频信号。最后,自动说话人确认子系统识别某些关键词汇,再利用相关特征与说话人匹配。
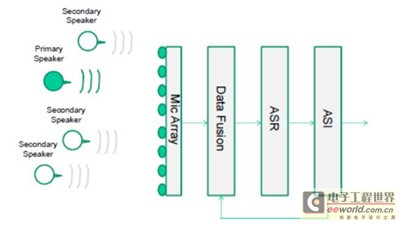
图 2. 系统框架
如果语音识别任务没有成功,则反馈给数据融合系统,估算新方向传入的语音,然后驱动麦克风阵列指向该方向。
2.1 语音识别和说话人识别
语音特征提取(27 LPC-倒普系数)需要确定语音的端点,将语音分成数个短祯(每祯20 ms),通过一个DTW模式对准算法与一组参考语音(模板)匹配。然后,应用欧氏距离测量法进行相似性评估。
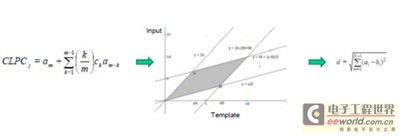
图 3. 特征提取、模式匹配和评分是说话人语音识别确认任务的主要环节
说话人身份评分采用的是动态时间规整近邻(DTW-KNN)算法的距离测量方法,即动态时间规整测量算法与近邻决策算法的合并算法。这个算法需要使用均方根、过零率、自动相关和倒普线性预测系数。使用欧氏距离算法计算成本函数,使用KNN 算法计算最小距离匹配度 k。
3. MEMS麦克风阵列
我们采用STM32F4微控制器和MEMS麦克风开发一个硬件音频信号同步采集处理子系统,其信号捕捉能力相当于8个采样率高达48 KHz的麦克风 。

图 4. 采用STM32F4微控制器和MEMS麦克风的硬件音频信号同步采集处理子系统
3.1 MEMS技术
MEMS技术的主要特性是在能够同一芯片表面集成微电子和微机械单元,在同一封装内整合不同的功能。这样,过去分别由传感器、执行器(例如,射流管理或机械交互)和逻辑、控制单元完成的不同功能,今天可以整合在同一个封装内。从生化分析,到惯性系统,从机械传感器,到音频和声波传感器, MEMS产品覆盖很多应用领域。
3.2 MEMS麦克风和音频编码
MEMS麦克风尺寸虽然比其它技术麦克风小,但是,从物理和机械角度看,却具备标准驻极体麦克风的全部功能,其核心部件是一个振膜,振膜和固定框架共同组成一个可变电容器。当声波引起振膜变形时,电容会发生变化,从而导致电压变化。
被捕捉到的信号的后期处理,即功率放大和模数转换过程,都是在同一芯片上完成,因此,麦克风输出是高频PDM信号。在脉冲密度调制过程,逻辑1对应一个正 (+A) 脉冲,而逻辑0对应一个负(-A)脉冲。因此,假设输入一个周期的正弦音频,当输入电压在最大正振幅时,输出为一个由“1”组成的脉冲序列;当输入电压在最大负振幅时,输出则是一个由“0”组成的序列。当穿过0振幅时,声波在1和0序列之间快速变化。如果方法正确,PDM可通过数字方法给高品质音频编码,而且实现方法简易,成本低廉。因此,PDM比特流是MEMS麦克风常用的数据输出格式。
另一方面,PCM是一个非常著名的音频编码标准,以相同的间隔对信号振幅定期采样,在数字步进范围内,每个采样被量化至最接近值。决定比特流是否忠实原模拟信号的是PCM比特流的两个基本属性:采样率,即每秒采样次数;位宽,即每个采样包含的二进制数个数;通过降低采样率(降低十分之一)和提高字长,可以将PDM编码信号转成PCM信号,PDM数据速率与降低十分之一的PCM采样率的比值被称为降采样率。因此,对于N:1降采样率,只要每N个间隔采样一次(不考虑剩余的N-1),即可完成降低十分之一的采样过程。
3.3 麦克风阵列
从硬件角度看,这款产品基于STM32F407VGT6高性能微控制器,能够通过8个MEMS麦克风采集信号。STM32F4微控制器基于工作频率最高168 MHz的高性能ARM® Cortex™-M4 32 RISC处理器内核,集成高速嵌入式存储器(闪存容量最高1 MB, SRAM容量最高192KB)以及标准和先进的通信接口,例如,I2S全双工接口、SPI、 USB FS/HS和以太网。
STM32 F4系列是意法半导体首批基于支持FPv4-SP 浮点扩展运算的ARM Cortex-M4F内核的STM32微控制器,这使得该器件适用于重负荷算法,浮点单元完全支持单精度加法、减法、乘法、除法和累加以及均方根运算,还提供定点和浮点数据格式转换和浮点常数指令,完全兼容ANSI/IEEE Std 754-1985二进制浮点算术标准。为提高ARM架构的数字信号处理和多媒体应用性能,指令集还增加了DSP指令集。新指令是数字信号处理架构常用指令,包括带符号乘加变化(variations on signed multiply–accumulate)、饱和加减和前导零计数。
麦克风阵列通过RJ45以太风接口或USB OTG FS接口连接其它器件,与其它器件交互是通过可控制基本板设置的DIP开关实现。
如下图所示,每个MEMS麦克风都是由同一个时钟源触发,时钟源由专用振荡器驱动,对每个GPIO端口的一个引脚输出1位PDM 高频信号。输出PDM数据频率与输入时钟同步,因此,DMA控制器以同一频率即音频捕捉频率对GPIO端口进行读操作,然后将1 ms音频数据(每次)保存在存储器缓冲电路。这时,该缓冲器包含麦克风交叉信号,然后软件利用优化的快速解码函数对数据进行解复用处理。最后,PDM 数据通过数字信号处理环节,再进行PDM转PCM处理。

图 6.每个MEMS麦克风都是由同一个时钟源触发,时钟源由专用振荡器驱动,对每个GPIO端口的一个引脚输出1位PDM 高频信号
麦克风传来的 PDM信号经过过滤和十分之一降采样率处理,以取得所需频率和分辨率的信号。麦克风输出的PDM数据频率(麦克风的输入时钟)必须是系统最终音频输出的倍数,滤波器管道输出是一个16位值,我们将 [-32768, 32767]视为一个单位增益(0 dB)的输出范围。
原先滤波管道产生的数字音频信号在信号调理前被进一步处理。管道第一级是一个高通滤波器,主要用于除掉信号DC失调。为保护信号质量,该滤波级是使用一个截止频率不在可听频率范围内的 IIR滤波器,管道第二级是一个基于IIR滤波器的低通滤波器。两个滤波器有启用和禁用以及配置功能;可通过外部整数变量控制增益。

图7. 麦克风传来的 PDM信号经过过滤和十分之一降采样率处理,以取得所需频率和分辨率的信号
如上文所述,数据采集有两个比特流解决方案,通过DP开关选择使用哪一个方案。当选用 USB且在主机USB插入麦克风阵列时,主机将STM32_MEMS_Microphones视为一个标准的USB音频设备。因此,主机系统无需安装驱动软件。例如, STM32_MEMS_Microphones可直接连接第三方PC音频采集软件。当选用以太网时,STM32_MEMS_Microphones发送RTP数据包。在网络服务器的以太网设置页对目的地IP、设备单播地址和采集参数进行配置。
4. 结论
音源定位识别是语音识别技术中的一个重要的语音预处理环节,对提高音频应用和声控应用性能具有重要意义。音源定位主要用于自动语音识别、音频模式识别、说话人发现及识别。MEMS技术的问世让麦克风阵列能够嵌入在上述应用设计中,执行音频信号预处理过程,为应用级提供最好的信息。
该嵌入式单个说话人及其语音定位识别方案基于一个集成ARM处理器和一组MEMS麦克风的原型板。初步测试结果证明了这一集成方案的可行性,且系统级模块可以做语音、音频识别目标板,满足人机、人与周围环境的自然用户界面的功能要求。
参考文献
[1] F. Riberio, D.A. Florencio, D.E. Ba, Using Reverberation to Improve Range and Elevation Discrimination for Small Array Sound Source Localization, IEEE Transaction on Audio, Speech, and Language Processing, vol. 18, n. 7, September 2010
[2] ST brings MEMS microphones to distant-speech research project, Solid State Technology, Volume 56, Issue 1, 2012

评论