一种数据挖掘系统的研究与实现

摘要 在研究与分析虚拟社会中人与人之间交互关系特点的基础上,设计和实现了互联网中潜在非法组织的成员推理和追踪系统。为再现虚拟社会中人与人之间的交互过程并对其进行推理分析,研究和设计了3大功模块:数据采集模块、数据库模块、网络分析模块。经验证,系统达到了设计要求。
关键词 在线社会网络;数据采集;数据库;网络分析
随着电子信息技术的发展,互联网已走进千家万户,并已广泛应用于各行各业。与此同时,一种新的社会形态逐渐形成,即“在线社会网络”。文中在研究与分析虚拟社会中人与人之间交互关系特点基础上,设计和实现了互联网中潜在非法组织的成员推理和追踪系统。系统包括:数据采集模块(网络爬虫模块)、数据库模块、网络分析模块。
1 数据采集模块设计
数据采集模块主要用来完成BBS论坛数据的收集、分析。
1.1 网络爬虫
网络爬虫是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。它根据既定的抓取目标,有选择地访问万维网上的网页与相关链接,获取需要的信息。与传统的搜索引擎不同,网络爬虫并不追求大的网络覆盖率,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1.2 数据采集模块实现
网络爬虫模块实现了采集数据的功能,包括获取链接、归类链接、主题链接、获取数据和分析数据5个子模块。获取链接功能描述:当输入论坛网址,系统就开始收集该论坛的网页链接,这是一迭代的过程,爬虫程序下载完一个网页链接后,打开该网页的源代码,从中得到下一个链接信息,将所有收集得到的网页链接保存到本地txt文本中。归类链接功能描述:将所有的网页链接按照年份归类到以年份为名称的不同文件夹,方便以后导入数据。主题链接功能描述:根据输入的年份获得所有主题链接,写入txt文本并保存在本地相应的年份文件夹。获取数据功能描述:根据之前抓取的主题链接,逐行打开链接,抓取网页源文件,以txt文本形式保存。分析数据功能描述:利用正则表达式,从收集到的txt源文件中匹配出有效数据保存到本地。
2 数据库模块设计
数据库模块主要是对数据库的操作,包括数据导入,数据更新,数据导出和数据整理4个子模块。数据导入模块功能描述:从本地正则分析过的txt文档提取相应的回复关系保存到数据库中。数据更新模块功能描述:对数据源(Forum)相应表中的回复时间和发表时间记录进行添加和更新。数据导出模块功能描述:根据用户输入的年份,将数据库的旧数据源(Forum)中符合年份要求的记录导入到新数据源(Export Data)中,为网络分析做好准备。数据整理模块功能描述:为以后的网络分析进行的准备工作,其主要功能是完成一些数据库的操作,例如利用原始的Reply关系构建Basic network、Together-reply network、Each-reply network、Semantic netwrok。对语义网络(Semantic netwr ok)中的每条回复进行语义打分等。
3 网络分析模块
网络分析模块是整个系统的核心模块,其主要基于用户交互模块,对网络进行各种犯罪推理,主要包含以下3个子模块:用户可信度更新模块、选择下一个调查目标和犯罪网络的社区发现。
3.1 基于贝叶斯网络用户可信度更新模块
社交和信息通信网络,例如Internet,经常以图表示,其中网络成员用节点表示,成员之间的关系用连接边表示。刑事调查人员可以把每个成员视为一个代理,从互联网搜集关于成员的数据来建立犯罪概率网络。
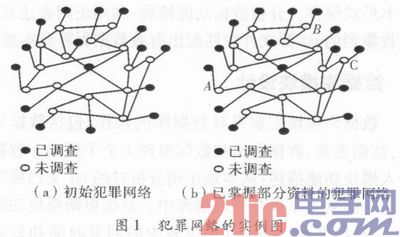
图1(a)是一个犯罪网络的实例图,黑色节点表示该成员被调查过,即刑事调查人员通过分析一个特殊成员的资料信息等来观察成员的状态,可调查人员并不知道这个成员的真实身份,白色节点表示该成员未被调查过。考虑一个图有节点i=1,2,…,n,节点(白色节点)的状态用xi表示,每个xi有M种可能状态,设定M=2,即每个节点有两种状态,犯罪分子和合法用户。每个未被观察过的节点被连接到一个被观察过的节点(黑色节点)yi上。一般来说,观察有关yi的一些信息,然后想推断出一些关于xi的身份。进一步假设xi和)yi之间存在一些统计依赖,用一个联合相容函数表示为φ(xi,yi)。这个函数通常被称作xi的证据,即可以通过观察yi推理得到关于xi的任何事情。因此,能够计算所有未知节点xi的信念b(xi),以至于能够推理得到潜在的未知信息。
更新步骤如下:
输入。本地概率分布φi(xi,yi),如果隐藏节点i被证实是犯罪分子,则φi(xi,yi)={1,0};隐藏节点之间的邻接关系用n×n矩阵来描述,如果两个节点邻近并直接相连,则邻接值为1,否则为0。隐藏节点之间的相容矩阵ψij(xi,yi)用2×2的矩阵来表述,矩阵中各元素的值由隐藏节点之间的依赖或信任关系计算而得。算法。信念传播算法。输出。b(xi),每个隐藏节点xi的犯罪概率。
3.2 利用MPFS算法选择下一步调查目标
当若干犯罪分子已被从犯罪网络中识别出来,就可使用MPFS算法计算这几个犯罪分子之间的最优联系。对于调查人员来说,他们希望以最小的代价尽快调查和确定犯罪分子。刑事调查人员经常会选择一些关键成员作为新的调查目标。但直接使用MPFS算法并不能满足调查人员的需求。所以扩展MPFS算法来帮助刑事调查人员来选择下一步的调查目标。基本思想就是:如果犯罪概率网络中的一些成员被证实了是犯罪分子,刑事调查人员想要知道这些犯罪分子之间的关系如何。一般来说,这些犯罪分子可能属于一个或几个犯罪组织。链接分析经常被用来分析犯罪分子之间的关系,假设犯罪概率网络中已经识别出M个犯罪分子,从这M个犯罪分子中某个节点s有M-1条到其他几节点的最短路径。尽管这M-1条路径是从s到其他节点的最强联系,但仍不知道s与其他犯罪分子之间的真正关系,所以还需要进一步调查研究。在这些最短路径上存在众多可疑成员,然而对刑事调查人员来说,调查这些路径上的所有可疑人员是不可能的,因为这需要大量的人力、物力和时间,因此只能选择关键的可疑目标进行调查。选择标准就是:最短路径经过次数最多的节点作为新的调查目标。
3.3 犯罪网络的社区发现
许多网络中都存在团体组织(Community),即团体内部成员之间联系比较紧密,而与外部成员联系比较松散,一个团体通常由具有相似特征或者相同爱好的成员组成。为寻找犯罪网络中的团体结构,提出了很多社区搜索的聚类分析算法,文中着重介绍分裂算法和凝聚算法。
3.3.1 分裂方法中的GN算法
GN算法就是一种典型的分裂方法。它的关键思想是通过不断地从网络中移除边介数(Betweenness)最大的边将整个网络分解为各个社区。
GN算法的基本流程如下:(1)计算网络中所有边的Betweenness。(2)找到:Betweenness最高的边并将它从网络中移除。(3)重复步骤(2),直到每个节点就是一个退化社区为止。
设一个网络节点数为m,边数为n。GN算法首先随机选择网络中的某个节点作为初始节点计算所有到这个节点的边介数。因为选取的初始节点遍历网络中的每个节点,则网络中的每条边都会有m个介数,然后将m个介数累加得到某条边的最终的边介数。排列所有边的介数,找到边介数最大的边。将边介数最大的边删除,重复以上步骤,最终可以得到网络的社区结构。因为边介数聚类算法是全局搜索算法,使得GN算法有很强的实用性。GN算法准确度比较高,分析团体结构的效果比原有算法要好,成为目前进行网络社团分析的标准算法,并得到广泛应用。
3.3.2 凝聚方法中的Newman快速算法
由于传统的GN算法不能满足大规模的复杂网络,Newman在GN算法的基础上提出了一种快速算法,它可以用于分析节点数达100万的复杂网络。
Newman快速算法实际上是基于贪婪算法思想的一种凝聚算法。算法步骤如下:
(1)初始化网络为n个社区,即每个节点就是一个独立社区。初始的eij和αi满足

其中,ki为节点i的度;m为网络中总的边数。
(2)依次合并有边相连的社团对,并计算合并后的Q值增量
△Q=eij+eij-2aiaj=2(eij-aiaj) (3)
根据贪婪算法的原理,每次合并应该沿着使Q增大最多或者减少最小的方向进行。该步的算法复杂度为O(m)。每次合并以后,对相应的元素eij更新,并将与i,j社团相关的行和列相加。该步的时间复杂度为O(n)。因此,步骤(2)的总时间复杂度为O(m+n)。
(3)重复执行步骤(2),不断合并团体,直到整个网络都合并成为一个团体。最多要执行n-1次合并。
该算法总的算法复杂度为O((m+n)n),对于稀疏网络则为O(n3)。整个算法完成后可以得到一个社团结构分解的树状图。再通过选择在不同位置断开可以得到不同的网状社团结构。在这些社团结构中,选择一个对应着局部最大Q值的,就得到最好的网络社团结构。
4 结束语
以天涯论坛的真实数据,对系统各功能模块进行验证,实验结果表明推理和追踪系统能够获得较为理想的结果。需要改进和下一步研究的内容有如下几方面:
(1)数据采集过程中利用正则匹配将半结构化的网页数据转化为结构化的数据,但是这仅是针对天涯论坛的;对于其他的站点,由于其编码方式的不同,采用相同的正则表达式,不能准确地提取结构化信息。所以需要提出一种泛化的提取策略,保证对决大多数站点的交互信息的正确提取。
(2)数据库模块中,赋予每个用户ID固定的坐标,以满足可视化。这种赋值是绝对化的赋值。应该根据窗口的大小进行相对赋值。经过实测,如果主机现实像素改变,其对应的可视化节点位置可能会发生扭曲。因此系统的可视化模块需要进一步改进。
(3)用户可信度更新采用贝叶斯网络模型,但模型中的本地证据和相容函数都是随机给定的。而实际上,用户的可信度可以通过其交互的方式和发帖的内容进行预测。因此需要针对用户的行为模式,对其可信度进行初步的预测。





评论