基于听觉特性的声纹识别系统的研究

声纹识别技术(说话人识别技术)是一种生物认证技术,也是一项根据说话人波形反映其生理和行为特征的语音参数来自动识别测试的说话人身份的技术。
本文引用地址:https://www.eepw.com.cn/article/201609/303780.htm在未来的生活中,说话人识别将会以它自身独特的便捷性,实惠性和精准性受人瞩目,并且逐渐普及在生物认证技术领域。
说话人识别首要录制声音样本和提取语音特征参数,再把它们保存在数据库中,最后把准备验证的声音和数据库中的语音特征相匹配,利用匹配结果相似度来获得说话人的身份。
1 常用语音库
目前,世界各国都很重视建设语音数据库。最具代表的是美国建立的LDC(Linguistic Data Consortium)和OGI(Oregon Graduate Inst itute),以及欧洲国家建立的ELRA(European Language Resollces Association)组织。这些组织都是长期研究语音信号处理技术的。他们开发出规模巨大的语音研究资源。
第一个高质、大容量、高可信度的声音数据库是YOHO数据库。表1是YOHO说话人数据库。它是经过数字化的数据库,其输入特征参照了第三代安全终端单位(STU—III)的安全语音电话。设计了与文本有关的说话人确认系统,此系统是会提示用户说什么话,在YOHO中使用的是:“合成块”短语的语法。
这个数据库的环境是“办公环境”。另一方面,它还满足在噪声的环境和远距离麦克风的条件下对语音做测试。而这些均满足了消费者的消费需要。
国内,浙江大学CCNT实验室提出和建立了面向移动通信环境的说话人识别语音库SRMC(speaker recognition in mobile communicatio n)。
生活中,如果要采集语音的话,就会常常使用计算机,麦克风,还有录音功能电话机,此外还要有相应的调制解调器。这些录音设备都很普通且常见。
我们该怎样去评价和使用一个标准的语音数据库?我们需要对评价下个定义。如评价的细节、训练和测试数据集的分割。在特定条件(如训练和测试采用不同的麦克风)下进行系统性能评价,需要有足够的录音数据。

2 声纹识别系统
2.1 实验设计
由于实验条件的限制,本课题的语音库是自己创建的,实验用来训练和测试的说话人录音,大部分是班级同学和同一实验室的同学。在这个实验中我们使用的是普通话,我们中每一个人说话速度和音量都处于正常情况。实验语音是在两天时间内采集得到的。采集环境是实验室,一共有十个同学进行录音。男女比例是一比一。在本实验中,我们尽量保持实验室环境安静,假设我们采集的声音都是纯音,没有噪音。实验中用到的录音软件是cool edit 2000,用的录音设备是普通的立体声麦克风和COMPAQ笔记本电脑,我们把采样频率定为8000Hz,每一帧的帧长定为256个点,帧之间的距离定为80点,用16比特量化方式进行量化。采样之后,得到了标准化的数字语音,这个实验中,用到的语料是阿拉伯数字。包含之间的数字,每个人的语音是1个阿拉伯数字,每个人每一天要有9次朗读机会。我们把获得的所有的数据样本存储在计算机的硬盘中,拿出第一天的语音来进行训练使用,把第二天的语音用来做测试。每一个数字录音看做一个单位来进行测试。本文的实验中利用阿拉伯数字1~9的语音单元构成的隐马尔可夫模型。建市了与文本有关的身份确认系统。如图1所示。
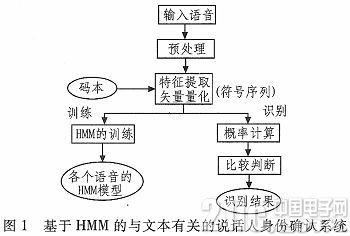
首先录制语音,采集语音,建立语音模板库,在实验室环境下,采集参加训练和识别的说话人语音。分别建立两个数据库。第一天录音存储为Xi,第二天录音存储为Ri。分别存储在计算机的硬盘中的录音DIY资料文件夹下。语音库是用来存储说话人的语音。当需要识别时可以用来识别说话人身份。随后将语音送至预处理功能模块。
其次对数字化语音进行预处理,此模块的任务语音信号的数字化处理,把处理过的语音拿来端点检测。预处理过程包含去除语音信号的噪声、对信号进行预加重、加窗、分帧等。经过加窗这一步骤之后,得到了一帧帧的语音序列,然后进行预加重处理。把信号做预加重处理是为了把信号中的高频部分提取出来,这样做整个频谱就会变得平坦起来,然后在全部的频带中一直保持这种平坦,这个时候我们可以用相同的信噪比求得频谱。这样都完成之后就可以频谱分析了。预加重滤波器的形式如:
H(z)=1-μz-1 (1)
式(1)中,μ的值在本实验中选取0.937 5。引进了预加重参数μ,可以看出,有利于提高说话人的识别率。表2中可以看到不同预加重参数下的识别率。
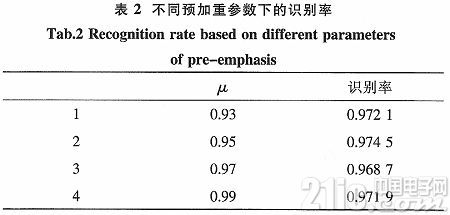
由表2可知,μ值改变,识别率也在改变。μ=0.95时,识别率最高。本实验选取的预加重参数值在0.93~0.95之间。
接下来是对语音信号分帧加窗。因为语音信号不是平稳的信号,假定语音信号在10~30 ms之间是平稳的。为了得到短时的语音信号,对语音信号进行加窗计算。本课题主要选用的是汉明窗。汉明窗显示了一个好的窗口的优点。其在时域中波形细节不容易丢失,且能防止泄露。汉明窗函数式:
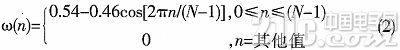
经过前面的一些处理之后,采集的语音信号就被分割成一帧帧的短时的加窗信号,把这些信号假设成随机平稳的信号,然后提取语音特征参数。
提取出来的语音参数,对其端点检测。此时,先设置门限,依据短时能量和过零率的公式,求出来短时能量值和过零率值。然后用手工方法在MATLAB上去除语音信号中的静音段和噪音语段来进行端点检测。
对系统的输入信号进行判断,准确地找到语音信号的起始点和终止点的位置。除去语音中的杂乱语音段,只有这样才能采集到真正的语音数据,减少数据冗余和运算量,并减少处理时间。如表3所示。在这里本课题用的是双门限法。将短时平均能量和短时平均过零率结合起来,进行端点检测,可以很好的检测语音是否开始和结束。



评论