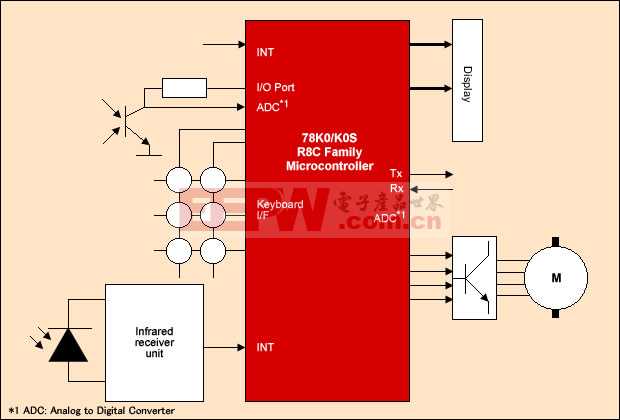
瑞萨为自动驾驶开发车载SoC,视频处理延迟时间仅为70ms
日本瑞萨电子与瑞萨系统设计公司为未来自动驾驶开发了车载计算SoC,并于2016年2月1日在半导体集成电路技术国际学会“ISSCC 2016”上发表了演讲(Session 4.4)。瑞萨还在当天的演示会上,演示了使用该SoC同时处理12通道全高清(1980×1080像素、30帧/秒)影像的情况。这是瑞萨车载信息IC“R-CAR”的第3代产品,预定2018年3月开始量产。
本文引用地址:http://www.eepw.com.cn/article/201602/286687.htm
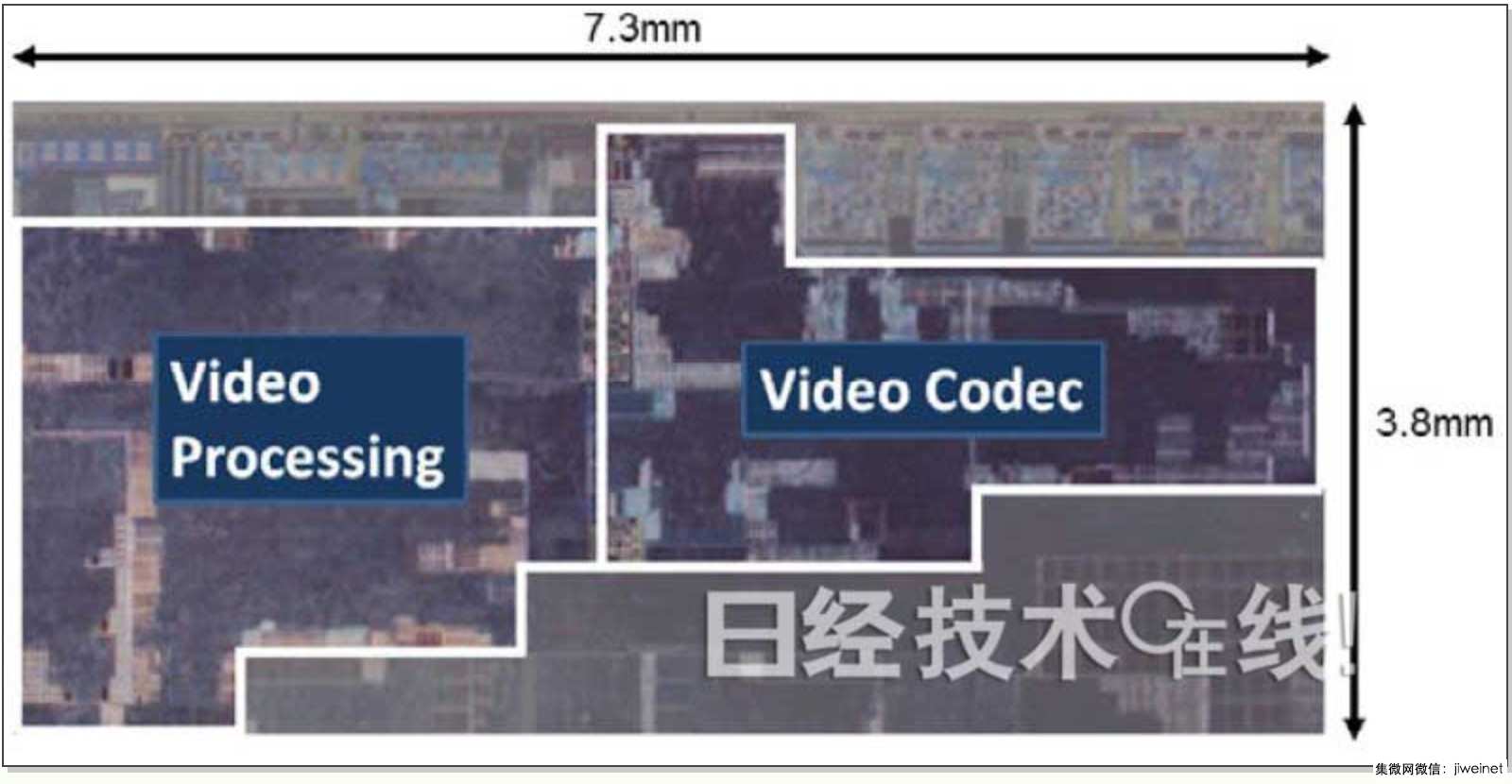
瑞萨开发的车载SoC

演示会现场。近处为车载仪表,远处为在显示器上分12个画面显示了全高清影像。

演示时使用的板卡。据说中间的散热片等部件的下方安装了此次开发的SoC。
据介绍,这款SoC在一个芯片上集成了ARM的多个CPU内核、GPU内核以及6种(17个)视频处理用处理器。瑞萨认为,到2020年前后,汽车的各种仪表、驾驶辅助系统(ADAS)、音响及多个显示器将会整合在一起,为此而开发了这种可实现整合的SoC。
此次开发的SoC采用16nm FinFET工艺制造。核心电压为0.8V,工作频率为400MHz。外置存储器设想使用LPDDR-3200。
设想的使用方法是,利用视频处理用处理器群来处理车载摄像头等的影像,用于娱乐用途,同时面向ADAS以及之后的自动驾驶用途,将这些影像数据用于物体识别等。每秒可处理的视频为7.5亿像素。如果是30帧/秒的全高清影像,这相当于约12个通道的影像。同时还支持4K影像,只是通道数量少一些。
处理延迟减少4成,通过流水线处理将总延迟时间缩短至70ms
如果只是单纯增加像素,也能通过增加处理器内核数量等方法来实现。据瑞萨介绍,此次开发的关键点之一是减少了视频处理延迟。原因是就连泊车等低速行驶时,影像的延迟也必须低于100ms。
视频处理一般首先用流处理器(SP)来处理压缩的视频帧,然后用编解码处理器(CP)来进行解码等。以往的视频处理IC因使用SP进行帧处理的时间各不相同,为了消除这种偏差,SP处理之后需要数帧的缓冲。仅这样的缓冲就会导致近100ms的延迟。
瑞萨为了解决这一问题,对视频编码技术进行选择,让SP等的处理时间一定,而且不等每帧的SP处理结束,每隔几个像素就将数据移交给CP。由此,SP处理之后就不再需要缓冲了,从而实现了视频数据的流水线处理。SP与CP之间的延迟大幅缩短至1ms。据介绍,包括之后的失真补偿处理等在内,视频处理的总体延迟减小到了70ms。
不过,这并不是最终目标。没有驾驶员的完全自动驾驶最早有望于2020年代后半期开始,如果实现自动驾驶,就必须进一步大幅缩短处理延迟。“将来的目标是,通过减少SP处理之前的帧缓冲时间等措施,使压缩视频数据的处理延迟降至10ms以下”(瑞萨系统设计第一开发事业部Cockpit业务推进部第三科首席工程师、在本届ISSCC发表演讲的望月诚二)。
存储控制器为CPU内核设置了“后门”
该SoC的另一个关键点是可在SoC向存储器写入视频数据时压缩数据。比如,如果以非压缩形式将12通道全高清视频数据输入输出存储器,用CP进行数据编码及解码处理时,需要20GB/秒的带宽,会占用存储带宽的40%。这样可能会对CPU内核及GPU内核负责的物体识别处理产生不良影响。因此,瑞萨通过在访问存储器时压缩数据,节约了存储带宽。
不过,这样做存在一个问题。那就是CPU内核等使用的视频数据基本上都是非压缩的,因此保存在存储器里的压缩数据不能直接使用。针对这一点,瑞萨在存储控制器中设置了压缩数据的“影子空间(Shadow space)”。CPU内核访问压缩数据时,会访问这一空间,对数据进行解压缩。
据介绍,这样一来,CP访问存储器时的带宽缩小到了非压缩时的30%,其他处理器访问存储器时的带宽则缩小到了非压缩时的50%。由此,连接处理器或存储器的总线的功耗降低了约50%,SoC的总体功耗也减少20%,降至197mW。
此次开发还有一个关键点。那就是这款SoC符合车载IC故障频率等的标准“ISO26262”。关于这一点,瑞萨在ISSCC 2016的Session 4.5上进行了介绍。







评论