基于Altera浮点IP核实现浮点矩阵相乘运算的改进设
3.2 计算结果仿真
对改进的设计进行仿真,采用A9×16数据与B16×8数据相乘,获得计算结果仿真如图4所示。

从图4可见,loadaa、loadbb、calcimatrix三者的时序满足浮点矩阵运算的时序要求,在前两者数据加载后,加载calcimatrix上升沿,进行矩阵相乘。在outvalid为高电平时输出数据,同时完成信号done输出低电平。在输出结果上,共分为9个大组,各大组有8个数据,共组成72个数据结果,其中显示了第一部分输出结果,获得与Matlab仿真相近的计算结果,在精度上相差不到万分之一。

从表1中可以看出,改进后的IP核在处理时间上缩短了807个周期,同时在最高运行时钟上提升了15%,系统整体的持续性能增加了7.2 Gflops。
依据改进前后的IP核,使用Quartus9.1软件进行综合布局布线,映射到Stratix Ⅲ EP3SE110F780C2器件中,可获得相应的资源对比图如图5所示。由于采用的都是并行浮点乘加运算,所以在乘法器资源的消耗上不变;同时由于只是在存储器的存储方式上作出变动,所以二者的存储资源相等。从而只需要对图中显示的矩阵阶数、vectorsize大小进行比较即可,而浮点计算性能与最高时钟频率变化方向相同,所以只对ALM数量及最高时钟频率进行对比。
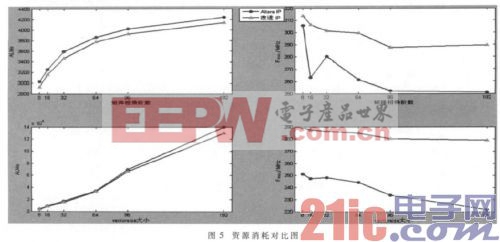
从图5中资源消耗对比可见,当设定vectorsize为固定值8(图5左半部)时,随着矩阵阶数的增加,改进后的IP核在ALM资源消耗上较改进前数量上有一定的减少,在最高时钟频率上都有小幅度提升,这是因为矩阵输入时消耗时间过长;当设定矩阵阶数为192×192(图5右半部)时,随着vectorsize值的增加,改进后IP核在ALM数量上有所减小,在最高时钟频率上则有小幅度提升,且波动幅度在3.4%左右。可见,改进后IP核比原Altera的IP核综合性能有所提升。
尘埃粒子计数器相关文章:尘埃粒子计数器原理







评论