基于内容的音频检索系统的前端抗噪技术

引言
本文引用地址:https://www.eepw.com.cn/article/166556.htm基于内容的音频检索指通过音频特征分析,对不同音频数据赋以不同语义,使具有相同语义的音频在听觉上保持相似。该技术在许多领域都有极大应用价值。在检索系统中一种常见情形是将安静环境下训练的模型应用于实际有背景噪声的环境。尤其在哼唱输入的情况下,噪声不可避免,因此噪声背景环境中的音频识别技术一直备受关注。本文给出一个将音频增强和音频检索系统相连接的抗噪声音频检索系统,重点分析基于内容的音频检索系统的前端抗噪技术。
2 系统平台的建立
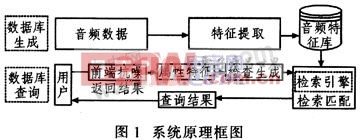
基于内容的音频检索系统运用多媒体信息处理技术,结合人感知心理研究和模式识别技术实现音频检索,包括音频分割、特征提取和索引检索等关键步骤。在提交哼唱式音频过程中不可避免地会受到来自周围环境和传输媒介引入的噪声、设备内部电噪声的干扰。这些干扰将使检索系统的性能恶化。因此,必须对带噪音频进行抗噪处理。音频检索系统首先是建立数据库,对音频数据进行特征提取。音频检索主要采用哼唱查询方式,用户通过查询界面哼入查询信息,然后提交查询。在进行属性特征提取前通过前端抗噪模块增强哼唱语音。接着系统对哼唱音频提取特征,然后检索引擎对特征矢量进行匹配,按相关性排序后通过查询接口返回给用户。图1为抗噪声检索系统原理框图。
3 音频抗噪技术分析
3.1 语音增强算法分类
系统前端输入信号通常是哼唱输入,语音频段可以采用语音增强技术。语音增强是指为了提高受噪声污染的语音信号的质量而对含噪语音所做的处理,主要用于从带噪语音信号中提取纯净的原始音频或原始语音参数。根据不同的标准,语音增强算法有多种分类方法。
从信号输入的通道数分为单通道的语音增强算法与多通道的语音增强算法。单通道语音系统下语音与噪声同时存在于一个通道中,语音信息与噪声信息必须从同一个信号中得出。常用方法包括谱减法、信号统计模型方法、听觉掩蔽算法、维纳滤波方法、信号子空间算法等。多通道语音增强算法则采用麦克风阵列获取信号数据,它可充分利用阵列信号的信号源方向、说话人位置等空间特性,结合语音信号与噪声的特征实现语音增强。代表性的算法有自适应波束形成算法、结合波束形成与后滤波算法及各种基于信号子空间、统计模型算法等。
另一种分类方法是根据对语音信号处理方式的不同,将语音增强算法分为时域语音增强算法和变换域语音增强算法两大类。时域语音增强是在时间域直接处理带噪语音来恢复纯净语音,利用语音信号在时域中的短时平稳特性、相关特性等来研究具有针对性的噪声消除技术,其代表性算法有最大后验概率估计法、卡尔曼滤波法、梳状滤波器法、子空间的方法、自适应噪声抵消算法、语音生成模型等。变换域语音增强需一个适当的变换将语音信号转换到变换域中,然后针对变换域中的带噪语音分量的特性设计算法恢复纯净语音分量,最后通过相应的反变换获得纯净语音信号在时域中的估计。其常用变换有离散傅里叶变换、离散余弦变换及K-L变换和小波变换等,代表性算法有谱减法、维纳滤波法、短时谱幅度的MMSE估计、自适应滤波法等、听觉掩蔽效应增强算法,小波变换算法、基于频域盲源分离的语音增强技术等。还有一些新方法,如神经网络、分形理论等。




评论