TI KeyStone 架构支持 L2 与传输处理
借助多内核导航器,系统中的所有数据包都能够满足数据包DMA 接口规范要求。数据包通常以图 8 中的主机类型数据包格式表示,其可实现灵活的存储器使用模式。在这种格式下,数据包通过链路缓冲器描述符 (BD) 来表述。我们将第一个 BD被称为数据包描述符 (PD)。BD 具有指向储存数据包有效负载的数据包缓冲器指针。队列管理器可与 PD 协同工作。
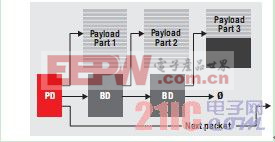
图 8 –主机类型的数据包格式
9
队列管理器可在其内部随机访问存储器 (RAM) 中维护数据包链路信息,从而为实现超高效率的数据包压入与弹出提供简单的软件应用编程接口 (API)。此外,其还可以确保队列所有访问的多核原子性,从而将多核软件从门控与保护逻辑中释放出来。为了实现基于演进数据包系统 (EPS) QoS 的无线电广播承载服务架构目标,相似服务等级的无线电广播承载都要以硬件队列集的形式出现。
零复制 RLC/MAC 概念充分利用数据有效负载无需在 PHY 编码器/解码器的 PDCP 加密(解密)与 CRC 生成(或校验)之间进行处理的这一原理。RLC 与 MAC 子层需要对数据包进行汇聚/解汇聚、分段/解分段、多路复用/解多路复用,并需添加/移除控制信息与报头。想要在无需触及有效负载数据(零复制)的情况下实现这一点可节约多达 90-95% 的处理周期时间。因此,有效负载数据驻留在 DDR 中,而且 L2 DSP 核心软件是不可触及的。
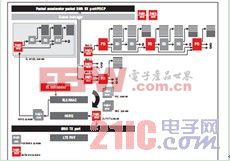
图 9 – 下行数据流示例
10
例如,在下行方向,网络协处理器数据包 DMA 进程负责对数据包进行接收、分段与分配。RLC/MAC 软件可在数据包描述符上运行且无需访问数据包有效负载。其构建的 MAC PDU 可被 SRIO 数据包 DMA 发出并反向重组成相邻的存储器。
RLC/MAC 软件使用数据包 API 库在数据包内运行。该软件可在数据包链中移除/插入描述符,而且还能执行数据包合并/分离操作。在需要额外报头时才用得上新的描述符。图 9 以在网络协处理器中执行 PDCP (RoHC) 等所有快速通道处理为假定条件,对下行数据流进行了总结。
我们将所有指向预分配固定容量数据缓冲器的 BD 链接在一起,并将其放置在下行 (DL) 自由队列中。有多个自由队列,每一个队列都对应一个固定容量的缓冲器。当来自网络协处理器的数据包到达后,网络协处理器中的数据包 DMA 即从 DL 自由队列中拉取 BD,然后根据 GTP-U ID/RBQ ID 映射对其进行初始化和构建 PD,并将 PD 压入 RBQ。DL 调度程序制定分配决策,并向 RLC/MAC 进程发布分配授权。
RLC 与 MAC 根据需要弹出授权的 RBQ,然后将 PD 路由至 RLC 与MAC 队列。可能对数据包分段,之后统一进行多路复用并为其添加报头。数据包被保留在 RLC AM 重传队列中,同时对这些数据包克隆的复制版本(新的 PD 指向同一缓冲器)会向下流至可创建 MAC PDU 的协议栈。当传输就绪时,数据包(用于已分配 UE 的 MAC PDU)在硬件 DL PHY 队列中排队。SRIO 中的数据包 DMA 从 DL PHY 队列获取数据包,然后将它们传输至 LTE PHY 设备。传输开始后,数据包进入 HARQ 重传队列,并且在成功交付后返回到 DL 自由队列中。
调度层对于调度层,制定无线电广播资源的分配时需将瞬时通道条件、流量条件以及 QoS 等要求纳入考虑范围。因为通道与流量条件因时间和频率的不同会有很大差异,因此能否实现高效的带宽利用率很大程度上取决于调度程序选择最佳可能用户(单个用户或用户对)的能力。
典型的调度算法可为单个或多个用户模式构建一组调度假定方案。调度程序然后根据链路的自适应性为每种假定计算中标率。最终,调度程序选出最佳假定方案并用以指导通道分配。
调度算法的复杂性是由单个调度假定的计算成本以及需检查的假定数目来决定的。信号处理密度型调度是一种高效率的动态的通道感知型调度。上行端的 FDD/TDD 调度程序需要计算足够大的一套假定方案才能维持单个或多个用户模式的调度增益;同时,带下行链路波束成形 (downlink beam foaming) 的 TDD 调度程序要求的假定方案可假定定向传输与特征值分解 (EVD) 计算。KeyStone 架构中的 C66x DSP 内核可支持专业的定点与浮点指令,可实现高效的 EVD 计算,如矩阵相乘、矩阵求逆以及大量用户(数以百计甚至数以千计)的高效搜索与筛选。图 10 提供了由 TI 仿真工具生成的调度程序可视化示例。此例使用 100 个无线电广播资源模块,每个传输时间间隔(TTI,1 毫秒)可生成 20 个分配授权。频谱的较低位部分可用于半持续性语音流量,而较高位部分则用于特定的数据流量。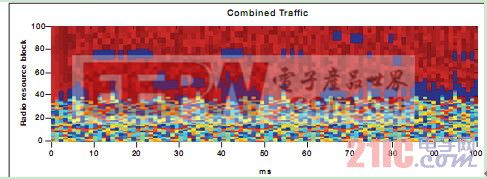
图 10 – 调度程序可视化示例
结论TI KeyStone 多内核 SoC 架构可提供一个低时延、高吞吐量的低成本高效率平台,可支持适用于宏与小型蜂窝 eNodeB 系统的真正多标准 (LTE、WCDMA)解决方案。高吞吐量硬件加速器与数据包基础局端加速可实现灵活且可扩展的 LTE 部署,同时还能最大限度地缩短 LTE 系统所需的时延。在同一 DSP 中集成定点与浮点技术可实现优化的矩阵处理最,以满足 LTE要求的调度效率。
根据对宏 LTE 系统的解决方案分析,由于采用KeyStone 多内核架构实现快速通道与零复制处理,可以将 20 MHz、2x2 多重输入多重输出 (MIMO) 以及 105 Mbps 下行与 52Mbps 上行数据率- L2 数据-以及传输层系统开销降低10 到 15 倍。借助针对 LTE 调度程序运行而优化的 C66x DSP 定点与浮点指令,还可以使用更多高级调度算法,从而将频谱利用率提高 20%。







评论