定制DSP设计MPEG-4无线视频产品
在视频编码中常常会遇到可变长度解码。比特流/可变长度解码DDCU 可以加快从输入比特流中取出可变长度字段的速度,这是一种基本操作。如果用软件来实现这种比特流管理,会消耗大量的时钟周期来处理指针的移位、屏蔽和管理,而采用比特流/可变长度解码DDCU则可以在一个简单的硬件单元里快速完成同样的功能。
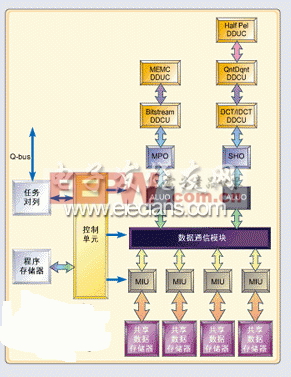
在比特流/可变长度解码DDCU中,由用户设计的指令组集中完成普通比特的提取和插入操作。这种DDCU不但能加快处理速度,提高整个视频引擎的性能,还可以解放处理器中的其他资源,使之得以用于周围的其他处理过程。因此,采用这种DDCU不但可以减小指令长度,同时还增强了系统性能。实际上,在DSP中加入这种计算单元会使可变长度解码的速度增快23.2%。
2. 量化/反量化DDCU
量化和反量化是视频编解码中的两种基本操作,其计算量占整个视频编解码计算量的10%甚至更多。量化/反量化DDCU允许在单周期内处理多像素,其内部操作可以满足多种MPEG-4等级的量化需求。在比特流/可变长度解码DDCU中,将可变长度解码模块的计算需求降低15.4%时,指令存储空间也会减小,这一特性同样适用于量化、反量化DDCU。
3. 半像素内插/运动补偿DDCU
这种运算单元用于加速半像素内插操作,该操作所需计算量相当大。在解码器中,内插/补偿操作所消耗的时钟周期约为总时钟周期的40%。该单元中所涉及的运算其实很简单,只需要面积很小的硅片就能完成,因此很容易移入DDCU中去。就算是边缘扩展这样的涉及大量计算的操作,只要不需要进行优化处理,也还是可以较好地移入硬件中。
不论采用哪种内插类型,内插/运动补偿DDCU中的指令组都允许每周期内插4个像素,这一特性也减少了需要执行的指令数。通过使用内插/运动补偿DDCU,半像素内插/运动补偿操作的速度可以增快74.6%。
4. DCT/IDCT DDCU
IDCT(反离散余弦变换)和DCT(离散余弦变换)都是视频编码中固有的运算。众所周知,这两种运算需要占用大量的时钟周期,并要求在编写其汇编代码时非常小心。本文谈到的这种专用DCT/IDCT DDCU单元(依据IEEE 1180-1990规范)可模仿DCT/IDCT中的“蝶形”运算。通过使用这种计算单元可以大大提高视频设计的性能和生产力,从而使开发人员能够集中精力开发视频应用中的其他方面,以达到使其产品区别于其他同类产品的目的。
5. 运动估计(MEMC)DDCU
MEMC单元用于帮助完成运动估计这一计算量最大的操作。无线视频应用中,在每个运动矢量的位置上都必须进行误差测量。MEMC DDCU可以完成两种最常见的误差测量计算:绝对误差和(SAD)测量和平方误差和(SSE)测量。DSP平台中若加入该运算单元,那么每周期误差测量时所比较和累加的像素位置就可以多达4个。
6. 四分之一像素运动补偿单元
基本来说,该单元所提供的功能是对半像素内插单元的一种必要的扩展。四分之一像素算法比半像素算法稍微复杂一些,因为它首先采用了一个2维FIR 滤波器来获取半像素值,然后才使用线性插值法来计算四分之一像素值。这个2维滤波器直接并入半像素内插单元,致使半像素内插单元的硅片面积稍有增大,但这种方式仍然保持了较高的像素处理速度,这一速度远远超过只采用Simple Profile 设计的DSP引擎。
7. 全局运动补偿单元
在视频应用中有一种变形函数(warping functiON)专门用来描述当前视频对像相对于参考视频对像的变化。全局运动补偿(GMC)单元就是为加速这种函数的运算而设计的。该单元最大可支持 3点变形(即参考VOP的仿射变换)。一旦从比特流中分析出变形点的个数后,就用这个数值来初始化GMC。GMC计算变形等式的速度远远快于纯软件实现方式的计算速度。
8. 语境自适应算法编/解码DDCU
构成语境需要进行逐位操作,而逐位操作只能在标准的32位DSP中实现。为了打破这一限制,语境自适应算法编/解码DDCU采用硬件方法形成语境值。该DDCU内部有一个查找表,用于存放所有可能的语境值,以便快速查找判断。语境自适应编解码运算单元支持以1b/周期的速度进行算法编、解码。怎样创建一个工作平台
设计者定义了需要用到的DDCU之后,就可以用它们来创建满足其特殊要求的用户应用引擎,并由此构建起工作平台,从而设计出具有MPEG-4视频功能的产品。
为清楚起见,让我们来看一个例子,例中的引擎是专门针对可传送MPEG-4信息的3G移动电话设计的。这样的引擎要想在3G移动电话上实现预期的视频功能,就必须以低于20MHz的速度处理第1级和第2级MPEG-4简单视觉等级,这样才能为诸如音频和语音处理等其他DSP功能留有一定的可规划带宽。
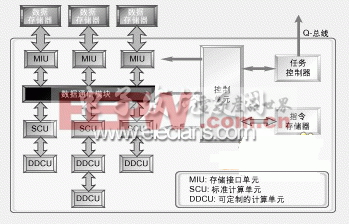
在开始设计用户DSP时,分配1 ALU、1 SHIFT和1MAC单元作为起始基准平台是比较合理的。要想增加并行性,只需将这些计算单元再分配给两个单独的指令段:ALU和SHIFT分配给同一段, MAC分配给另一段。如果该视频应用采用的是帧处理速度为每秒15帧的CIF格式,那么要在这个用户平台上编译视频应用程序就需要40MHz的带宽,若采用QCIF格式则只需10MHz带宽。尽管这样的带宽已经很具竞争力了,但仍然不能满足前面提到的具有MPEG-4功能的3G移动电话的需要。
降低带宽要求的解决方案
首先,要分析在用户平台中加入不同的计算单元对其性能的影响(这些计算单元全部来自MPEG-4 DDCU库)。也就是说,我们定义了一系列的引擎,以此分析不同的计算单元混用方式所造成的性能影响。分析表明,应该保留两段型引擎定义,因为这可以限制指令宽度,使之不至于过宽。
然后再定义一些新的引擎,经过编译,分析其结果。新引擎定义分析的整个过程用了1或2个小时。由于DDCU库是提前创建好的,因此许多引擎可以在一天时间内就分析完。接着从这些引擎中选出最能满足目标产品要求的,用来构建工作平台。
这样得到的工作平台与基准平台相比,增加了一个ALU和四个MPEG-4 DDCU:比特流DDCU、量化/反量化DDCU、半像素DDCU和DCT/IDCT DDCU(见图2)。在起始平台的基础上添加这些运算单元,目的就是在不增大指令存储或数据存储的前提下,尽可能降低对时钟速率(MHz)的要求。完成这些操作之后,我们得到了这样一个用户应用引擎,该引擎可以用带宽只有18MHz的DSP完成每秒15帧的CIF格式图像的解码,同时还能满足这种3G无线视频应用的其他关键要求(低功率、小晶片尺寸以及低时钟速率)。
从图3中可以看出DDCU对加快整个应用运行速度的作用。图中第一条表示在标准CU构成的基准平台上,整个运算时间在IDCT、运动补偿(MC)以及可变长度编码和反量化(VLD/DQnt)这几种DDCU之间的分布情况。
可以看出,在这几种DDCU中,MC部分占用时钟周期最多。因此我们在工作平台上添加了一个DDCU来加速半像素内插操作,提高MC部分的速度。一旦MC部分所占用的时钟周期数大幅降低,VLD/DQnt马上就上升成为了限制整个应用性能的最主要因素。针对这一情况,再添加一个比特流 DDCU和一个量化/反量化DDCU,又进一步提高了性能。这样,最初的基准平台已经经过了两次组合。此时,再将IDCT DDCU加入其中,整个应用的性能就得到了更大的提高。图3中的最后一条给出了三次组合后整个应用需要耗费的时钟周期。

超级电容器相关文章:超级电容器原理







评论