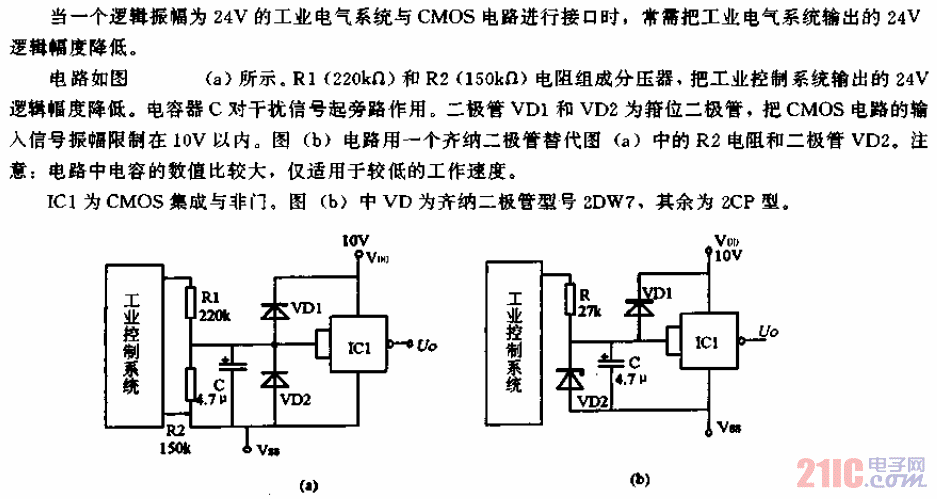
“强化学习”推动自适应控制器的兴起

工业过程控制传统上依赖固定参数控制器(如 PID)和基于模型的方法(如模型预测控制 MPC)。这些方法成熟可靠,但在非线性、时变或模型不精确的系统中,往往难以维持最优控制性能。
强化学习(RL)是自适应与自整定控制领域的一项重要技术,它使控制器能够通过与过程的交互直接学习最优策略。强化学习可通过混合架构集成到工业控制系统中,同时兼顾安全性、实时性要求,并采用合适的硬件实现方式。
现代工业过程受原材料波动、设备老化、工况变化等因素影响,不确定性不断增加。传统控制策略通常基于标称工况整定,当系统动态特性发生漂移时,需要反复重新调参。虽然已有自适应控制技术,但大多依赖显式过程模型和预定义自适应规律。
强化学习提供了一种数据驱动的替代方案。通过学习能够最大化奖励函数的控制策略,强化学习可以在无需显式系统辨识的情况下实现持续自适应。下图对比了传统反馈控制与基于强化学习的控制架构在概念上的区别。

在实际应用中,强化学习常与模型预测控制(MPC)结合使用。MPC 层负责约束处理并保证系统稳定性,而强化学习智能体则负责调整控制参数或选择运行模式。这种职责分离使工程师能够充分发挥两者优势:MPC 提供确定性约束处理能力,强化学习提供长期优化能力。
用于控制的强化学习基础
在强化学习中,智能体通过观测系统状态、执行动作、获取奖励来与环境交互。随着时间推移,智能体学习得到一种策略,将观测到的状态映射为最优动作。在过程控制场景中:
状态:包括传感器测量值或估计变量;
动作:对应执行器指令;
奖励:表征控制目标,如跟踪精度、能效、约束满足程度等。
与传统控制器不同,强化学习系统根据性能反馈持续更新控制策略。奖励信号构成额外的反馈路径,驱动智能体学习,而非直接产生控制量。
强化学习如何实现自整定控制?
强化学习在工业领域最实用的应用之一是自整定控制。此时,强化学习智能体并不直接操纵执行器,而是调整现有控制器的参数。
最常见的例子是基于强化学习的 PID 参数整定。PID 控制器保留在主控制回路中,强化学习智能体处于监督层,评估动态和稳态性能,逐步更新控制器增益。
这种架构风险低、可保留现有安全认证,且无需对老旧系统进行大规模结构改造即可部署。
在安全关键工业环境中,由学习智能体直接驱动执行器的纯强化学习控制方案很少被采用。因此,大多数实际应用采用混合架构,如强化学习与 MPC 的组合。
工业强化学习中的安全考量
部署基于学习的控制器时,安全是核心问题。探索是强化学习的核心环节,但如果不加约束,可能产生不安全动作。
可采用安全屏蔽机制,在强化学习输出的控制动作作用于对象前进行拦截与校验,对不安全动作进行修正或拒绝,并在奖励函数中进行惩罚。这种方法可在不违反严格安全约束的前提下进行学习。
实时性与计算约束
控制系统的周期常以毫秒计,要求执行具有确定性。强化学习会带来额外计算负担,尤其在使用神经网络时。
为满足实时要求,通常将推理与学习任务解耦:实时处理器执行控制回路,应用处理器或加速器以较低速率处理强化学习推理与学习。
软硬件协同设计要点
对电子工程师而言,基于强化学习的控制带来新的设计挑战:任务划分、内存管理、通信延迟均需仔细设计。为满足功耗与性能要求,常采用定点运算、低精度神经网络和硬件加速器。
分布式架构也逐渐兴起:强化学习智能体部署在边缘侧,高层协调通过工业以太网或工业物联网框架实现。
部署与流程限制
尽管潜力巨大,强化学习并不能直接替代传统控制。其稳定性难以严格保证,学习得到的策略也可能难以解释。
多数工业部署采用分阶段流程:在数字孪生中离线训练、充分验证、有限在线学习、部署后持续监控。这种规范流程对风险管控至关重要。
总结
强化学习为复杂工业过程中的自适应与自整定控制提供了强大框架。通过混合架构集成,并配合合适的软硬件协同设计,强化学习能够在保证安全可靠的同时提升控制性能。
随着智能控制系统日益普及,理解基于学习的控制器与实时约束、嵌入式硬件的交互方式,对电子工程师至关重要。








评论