让机器“解疑释惑”:视觉世界中的结构化理解|VALSE2018之八(3)

刚才我们所介绍的仍然是具有类似语义信息的这样一些特征,其实这样的特征并不一定要具有相同语义。在具体工作中,可以考虑这些特征可以具有不同的语义信息。比如说物体检测中可能有专门对应每一个物体的特征,比如说这位女士自己的特征,对于牙刷也有它自己的特征,小孩和他的牙刷都有自己的特征,往上走不同物体之间关系也有一组专门识别物体关系的特征。继续上走,每个语句也有自己的特征。如果考虑每一个特征都是一个结点的话,仍然可以利用它们之间的关系,通用边进行信息传递,最终提高这三个不同任务的效果。


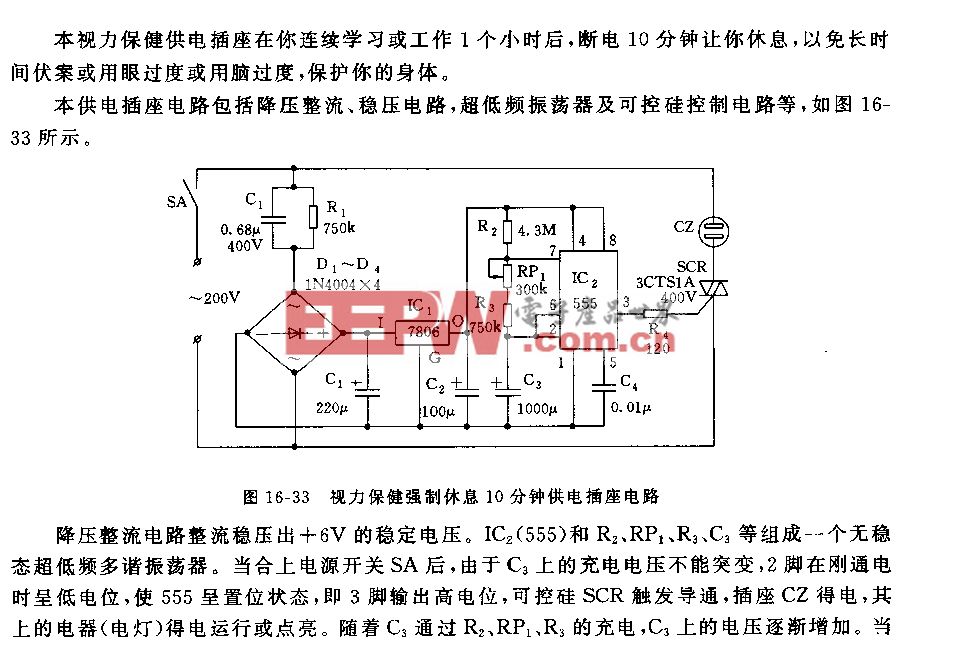
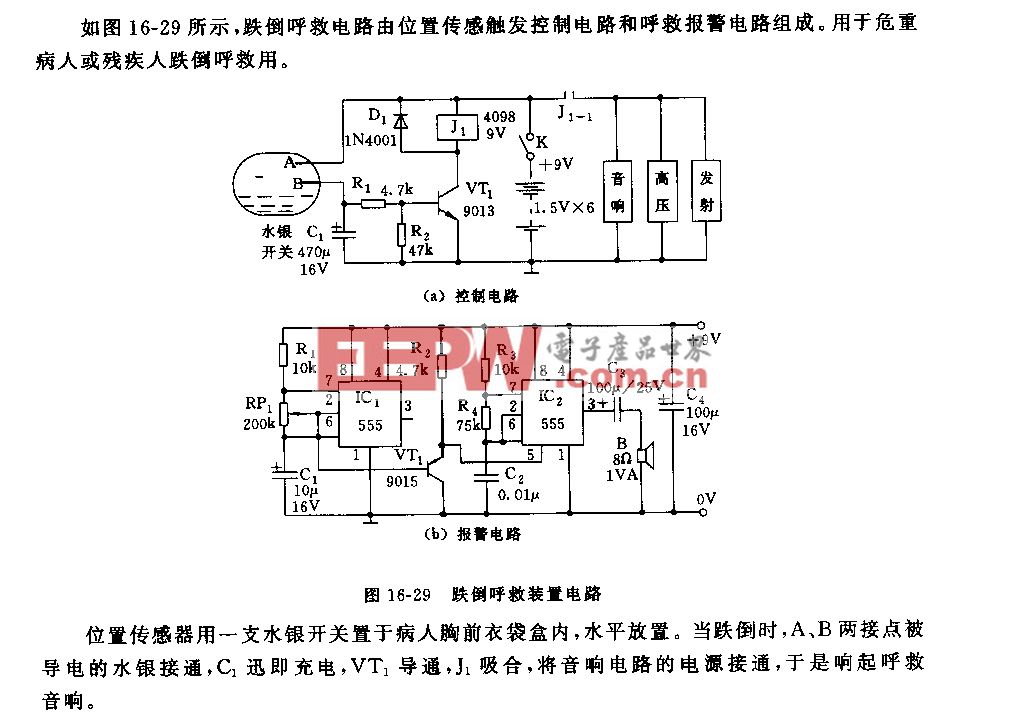
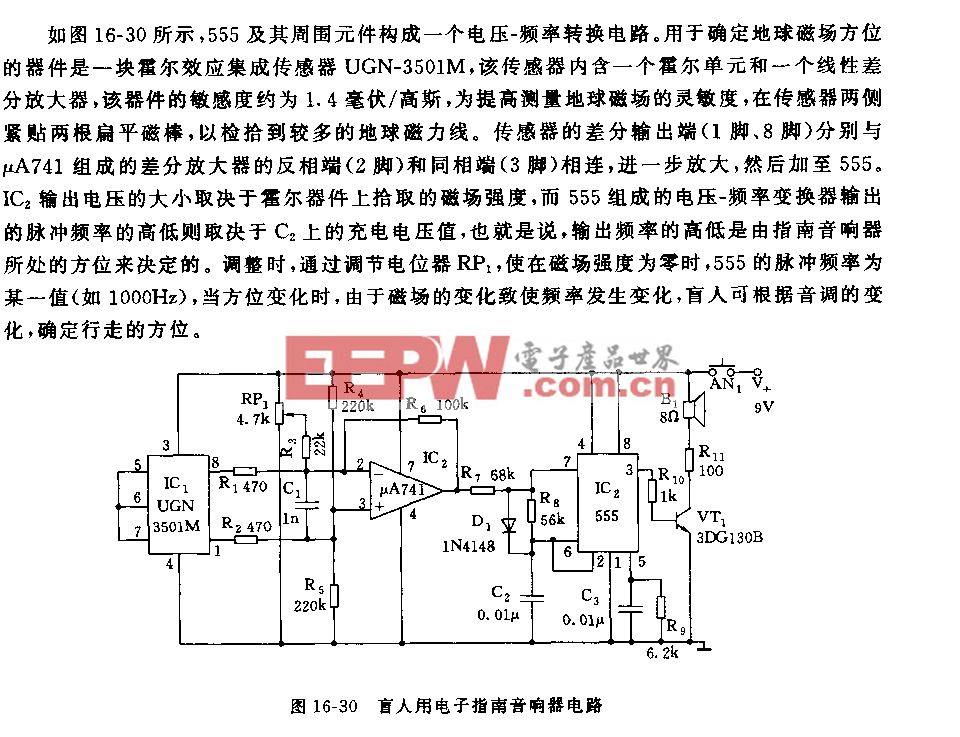
上面介绍利用结构化信息传递在不同任务进行结构化信息建模。它面临的问题是信息传递没有任何理论指导,我们只是通过观察来设计并通过实验发现这样做有效。为了解决这个问题,我们引入统计模型。具体而言,我们引入条件随机场,帮助我们进行网络结构设计。网络结构符合这样的统计模型。在具体工作中,我们对特征之间的信息传递利用条件随机场进行建模,也对加入门限控制的特征信息传递利用条件随机场进行建模。

在统计模型指导下,另外一个优势可以利用统计模型中一个很好的信息传递方法,帮助指导我们怎样在各个节点之间传递信息才是最有效的。

所以,对于结构化信息传递,在已有基础上考虑结构化的输出,可以引入结构化特征,将结构化特征和结构化输出进行联合学习。



除了结构化学习,我们实验室在基础网络设计上我们也做了很多工作。林达华老师设计非常好的网络-PoLyNet,它是一种非常深的网络结构。这个网络结构的基本想法是同一个模块中,引入多个inception module,可以并行或串行。利用这个方法达华老师所带的学生参加2016年的竞赛,竞赛中单个模型结果是当时最好的。

另外一个工作动机是,如果有同样大小的人脸,但是局部特征是不一样的。比如说在这个例子中有三张同样大小人脸,但是人的眼睛和嘴巴视觉信息大小是不一样的。这就要求我们的神经元具有多样性能够捕捉到这些不同大小的特征。

为了捕捉到不同大小的特征,有一种设计,就是设计不同大小的滤波器或者将不同大小的滤波器进行叠加,比如说有3×3再往上叠,可以得到5x5,这会增大参数量和计算复杂度。
我们考虑另外一种方式就是下采样。第一个分支中不采用任何下采样,这样情况下3×3的卷积对应的视觉信息就是3×3的大小,如果另外一个分支使用2的下采样,特征会变得原来1/2,3×3卷积看到大小就是6×6。通过这种方法,只需要改变下采样的参数,就能帮助我们实现捕捉不同大小特征的目的。最终,我们利用上采操作,使下采样造成的不同大小分辨率的特征变成同样大小,便于把它们连接起来。下采样和上采样不需要参数,运算快。这种做法取得了良好的实验效果。
论文相关代码在:
https://github.com/bearpaw/PyraNet.


另外一个问题,最近大家提出多种网络结构化,如ResNet,DenseNet,ResNext,甚至像GoogleNet和我们设计的PolyNet,这些网络具有一个共性:它有多个分支。有一个问题是,对应于有多个分支的网络结构情况下,常用的参数初始化方法的基本假设是不成立的。如果用这样的参数初始化会带来一些问题。为了解决这个问题,我们进行严格的理论推导,并给出最终答案。推导发现与输入、输出分支数和参数初始化是相关的。在图像分类以及人体姿态识别上都发现使用我们的方法以后会得到更好的效果。

另外就是人的行为识别。行为识别和很多做视频任务里很重要的信息是运动。


如果要得到关于运动的信息,我们发现有一种很简单的操作,就是先得到两帧图像特征,把两个特征点对点(element-wise)相减。这个相减是时间上的梯度,空间上的梯度可以用很简单的操作得到。这样简单的操作它背后来源于我们数学的推导,数学的推导告诉我们这样特征的表示和光流(optical flow)是正交的,正交意味着它们是互补的,这种特征会拥有原来optical flow没有的信息。实验发现使用我们这种特征而不使用optical flow,能达到的相似的准确率,但在速度上可以快很多。另外,由于特征是由它互补的,特征结合以后可以进一步改善准确率。论文相关代码会在近期提供。

总结一下,结构化深度学习在很多视觉任务中都是有效的。结构化信息通常是来源于观察,来源于对问题的理解。视觉领域的研究者对特定问题的观察和理解可以联合深度学习一起推进整个视觉的进步。另外,我们可以对输出和特征进行结构化的建模。而深度学习这样一个工具提供的能力是将结构的建模和特征的学习进行联合学习,增大最终解决任务的能力。

最后,广而告之: 将在ECCV2018举办首届WIDER Face and Pedestrian 竞赛和workshop。该竞赛包含以下三个子任务:
WIDER Face:探索人脸检测的新方法,
WIDER Pedestrian:探索监控和自动驾驶环境下行人检测的新方法,
WIDER Person Search:一个全新的从192部电影中人物检索的挑战。
每个任务的获胜团队将获得现金奖励和亚马逊服务器机时奖励。 竞赛中获胜并具有创新方法的团队将获邀参加ECCV workshop并共同撰写竞赛报告文章。
文中提到的参考文献百度网盘链接:
https://pan.baidu.com/s/1hmclXnibvm_kUIgJTi_Zyw 密码: n9bi
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

fpga相关文章:fpga是什么