【领域报告】图像OCR年度进展|VALSE2018之十一 (2)


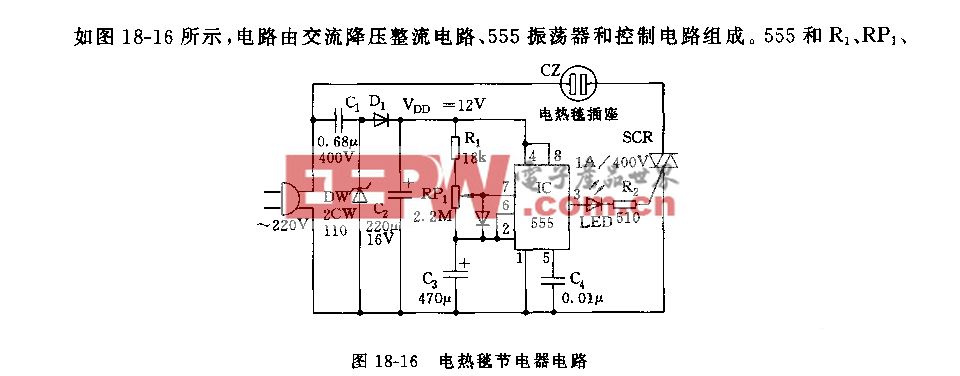
角点检测使用的是基于DSSD的方法,此外我们将角点检测和文本区域的分割在同一个网络框架内实现。
从实验结果中可以看出用了角点以后检测性能提升比较明显。

第二个方面是关于文本识别的进展,进展稍微小一点,因为目前的识别性能已经比较好。

利用attention model去做序列文字识别,可能会因为图像分辨率较低、遮挡、文字间间隔较大等问题而导致attention位置并不是很准,从而造成字符的错误识别。海康威视在ICCV2017上提出使用字符像素级别的监督信息使attention更加准确地聚焦在文字区域,从而使识别变得更精准。他们用了部分像素级别的标注,有了类别信息以后做多任务,结果较为精准。并且只要部分字符的标注就可以带来网络性能的一定提升。

针对有形变或者任意方向文字的识别问题,Cheng等人在CVPR2018上提出了该模型。他们在水平方向之外加了一个竖直方向的双向LSTM,这样的话就有从上到下,从下到上,从左到右,从右到左四个方向序列的特征建模。接下来引入一个权重,该权重用来表示来自不同方向的特征在识别任务中发挥作用的重要性。这对性能有一定提升,尤其是对任意排列的文字识别。


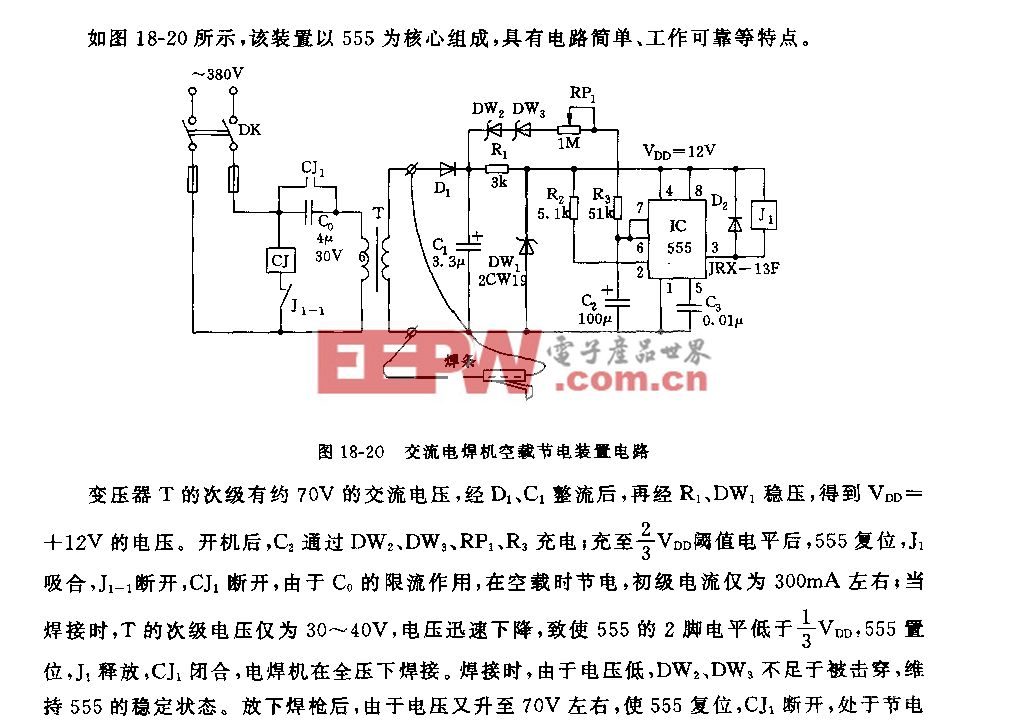
端到端识别从ICCV2017开始出现了将检测和识别统一在一个网络框架下的思路。目前来说这种做法训练起来较为困难。它的主要思路是通过RPN产生一些proposal,然后在后面接上序列识别网络。为了使网络有效,往往需要对检测和识别模块分别进行预训练,预训练完后再把两个模块一起进行进一步训练。这种方法较为复杂。

其它方法也采用了大同小异的思路,比如去年ICCV的这篇文章,在RPN的基础上,加入能产生任意方向文字框的proposal,可以做任意方向文字的端到端识别。

这篇CVPR的工作也是大同小异,使用了更好的检测器EAST,识别部分和训练过程基本和之前端到端的识别工作类似。



最后我们介绍一些新的数据集。比如说去年icdar比赛中的中文数据集RCTW,以及多语言检测数据集MLT,同时包含了语种识别和检测任务。RCTW数据集主要由场景中文文字构成,总共包含了12,034张图片,其中训练集8034张,测试集4000张。比赛分为文字检测和端到端文字识别两部分。MLT数据集由6个文种共9种语言的文字图片构成,共18,00张图片。该比赛包括了文字检测、语种识别以及文字检测加语种识别三个任务。


另外是今年华南理工金连文老师提出的比较有意思的数据集,用来探讨异常排列、有形变的文字的检测和识别问题。该数据集共1000张训练图片和500张测试图片,每张图片包含了至少一个曲行文字样本。另外,ICDAR2017上也有一个类似的数据集Total-Text,包括了水平方向、多方向以及曲形文字共1555张图片。
总结一下,通过数据集的演变过程,关于场景文字的研究方法有这样几个趋势:第一,以后检测和识别端到端进行可能是一个趋势,但是未必一定把这两个任务接在一起;第二,处理更难的文字,例如不规则文字,可能也是一个有意思的方向;第三,方法的泛化能力,英文上结果比较好的模型在中文中不一定有效,中英文差别很大,应设计适应多语种的方法来解决这些问题。
参考文献链接:
https://pan.baidu.com/s/10LT47XsUpzBjHu8S9mcy7Q 密码: k2iv
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。