基于SPCE061A的语音识别系统的设计

1引言
语音识别技术就是让机器通过识别和理解把语音信号转变为相应的文本或命令的技术。语音识别是一门交叉学科,正逐步成为信息技术中人机接口的关键技术,语音识别技术与语音合成技术的结合,使人们能够甩掉键盘,通过语音命令进行操作。近年来语音学研究的深入和数字信号处理软硬件技术的发展,语音技术的应用己经逐步具备走出实验室,服务于社会的能力。尤其在中小字表孤立词语音识别技术已基本成熟,逐渐开始应用于家电产品、智能玩具等对识别率要求不是极其严格的领域。
2 硬件系统的总体方案介绍
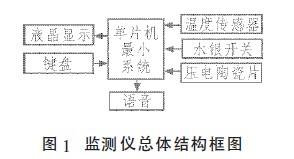
本系统采用凌阳SPCE061A作为主控芯片,并根据功能需求设计嵌入式语音识别系统的硬件。由于这是一款包含DSP功能并集成了户A/D,D/A等一系列功能的语音处理专用SOC,模块电路、外扩存储FLASH、LED显示电路、通信模块、功放和喇叭输出模块等。
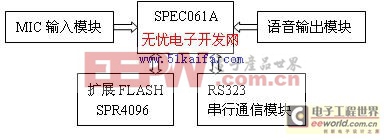
图1 语音识别系统的硬件组成
2.1电源电路
SPCE061A采用低电压供电方式,这可以大大降低芯片的功率损耗。其中,SPCE06lA的电源分两种,即内核电源(VDD)和I/O口电源(VDDH)。I/O口电源采用5V电压,而内核电源则为3.3V或者更低。降低芯片内核电压的目的主要还是降低芯片的功耗,同时也可以降低芯片的工作温度,延长芯片使用寿命。尽管这种语音芯片的工作电压范围很大,但是为了使芯片内核运行更加稳定,同时又保证I/O口及外部扩展部件的工作电压要求,系统采取:
AC220V电源通过AC10V进行整流,利用以7805稳压集成块为核心的电路,产生+5V电源,作为语音识别与播放模块共同使用的电源。5V电源经过TR1972-33得到DC3.3v为CPU核心供电。
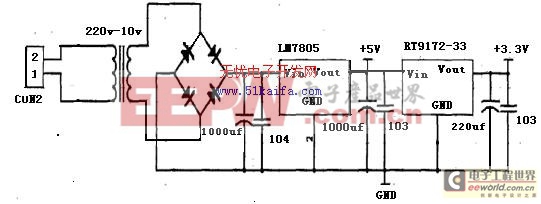
图2 电源电路
2.2存储模块部分电路设计
因为SPCE061A的FLASH只有32Kwords,要存放大量的语音资源,就需要外扩存储器。系统使用的是一种用SIO扩展串行存储器的方法。本方案采用凌阳公司的SPR4096芯片进行设计。SPR4096是一个高性能的4M-bit(512K×8-bit)总线FLASH,分为256个扇区(sector)每个扇区为2K-byte。SPR4096还内置了一个4K×8-bit的SRAM。在进行FLASH的编程/擦除的时候,可以并发执行SRAM的读/写。SPR4096内置了一个总线存储器接口和一个串行接口,它允许单片机通过8-bit并行模式或者1-bit的串行模式访问FLASH SRAM存储区。本例使用串行模式,其接口的工作频率为5MHz。SPR4096有两个电源输入端VDDI和VDDQ。VDDI为内部FLASH和控制逻辑供电;VDDQ专门为I/O供电。SPR4096最大读电流为2mA,最大编程/擦除电流为6mA。
2.3音频输出电路模块
放音利用的是SPCE06lA内部集成的DAC,它是电流输出,为了能够驱动扬声器SPEAKER放音需要相应的驱动电路。图中的SPY0030单运放是凌阳公司的产品。与常用的单运放LM386比,SPY0030的优势在如LM386的工作电压需要在4v以上,而SPY0030只需要2.4v可工作,LM386的输出功率在100mw以下,而SPY0030约为700mw,可以提供足够的驱动能力。音频输出电路如图3所示。
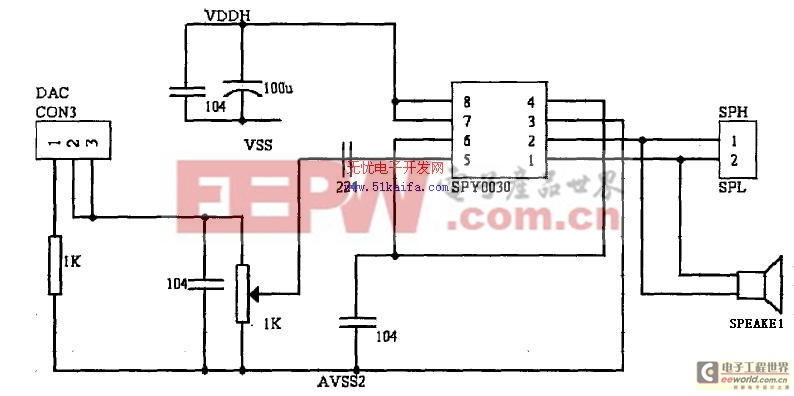
图3 音频输出电路
2.4 MIC输入模块
SPCE061A的A/D转换器有8个通道,其中有1个通道是MIC-NI输入,它专门用于对语音信号进行采样。语音信号经过MCI转换成电信号,然后输入至SPCE061A内部前置放大器。由于人们说话时,麦克风距离嘴边的距离不同,语音信号的能量将会有很大的差异,此时,如果芯片的的输入信号太大或是太小都将影响识别的精度。而SPCE06lA内部就带有自动增益控制电路AGC能随时跟踪、监视前置放大器输出的音频信号电平,当输入信号增大时AGC电路自动减小放大器的增益;当输入信号减小时,AGC电路自动增大放大器的增益,从而以补偿太小或是太大的信号,以便使进入户A/D的信号保持在最佳电平,又可使削波减至最小。
2.5通信接口电路
单片机中的数据通过串口经MAX232电平转换成RS-232电平向上位传输。由于SPCE06lA的串行口都为TTL电平,它与RS-232C电平互不相容,所以在二者接口处,必须进行电平转换。利用MAX232芯片外接5V电源,外接电容,可产生正负10V的电源形成232C的收发器。本系统中设有通信电路是为将大量语音数据处理都需要上传给PC,由PC完成。比如,噪声能量和过零率的计算,数字滤波器设计,模型库的训练等。
3软件设计部分
总体来说,本系统包含语音识别模块的软件设计和语音回放模块的软件设计。
3.1语音识别部分设计
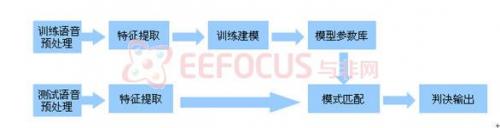
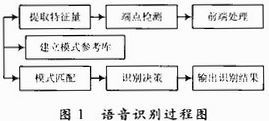
语音识别程序是软件编程的主体工作识别模块的程序流程图4所示。本系统采用了常用的能量过零率双门限法进行语音端点检测,采用了计算量较小的线性预测倒谱系数作为语音信号特征矢量,另外,基于非特定人的嵌入式系统要求,为了达到减少计算量和存储量的目的,在特征参数提取完成之后,利用矢量量化方法进行数据压缩。语音识别模型采用(DHMM)离散隐马尔可夫模型,利用Baum-welth重估算法、前向后向算法、viterbi算法来完成语音模板的训练和语音识别的任务。

图4 语音识别模块流程图
初始化子程序的作用是将微处理器中与语音识别相关的资源进行参数设置,使其实现为相应的功能,例如自动A/D变换等;
端点检测用来避免不必要的计算量,同时设定语音识别解码的起点和终点,防止无效搜索;预处理用来提高语音识别性能,增强稳健性的重要环节。预处理包括对原始语音信号的滤波、预加重、加窗、分帧等环节。同时还可能包含语音增强、噪声抵消、端点检测等等。预加重主要是为了提升高频部分,以弥补声音在唇部辐射时产生的高频部分的损失,可以使信号的频谱平坦,减少信号的动态范围;
特征提取就是对语音信号进行分析处理,去除对语音识别无关紧要的冗余信息,提取出对语音识别有用的重要信息;
矢量量化(VQ)是一种重要的信号压缩方法,它可以减少语音信号处理中所需要的大量的存储空间,并可以减少识别匹配的计算量;
语音信号本身是一个可观察的序列:它是由大脑中的(不可观察的)、根据言语需要和语法知识(状态选择)所发出的音素(词、句)的参数流,所以用离散隐马尔可夫模型(DHMM)来模拟语音信号。
3.2语音播放的模块设计
为了有一个友好的人机交互的功能,该系统还必须语音回放。语音数据的保存形式是以台湾凌阳公司开发的几种语音压缩编码算法来实现的。同时,凌阳公司还提供了相应的语音压缩与解压算法的API接口,可以方便开发人员进行编程开发工作。
先用凌阳Compress Tool事先把所需要的语音信号录制好,用凌阳压缩工具进行压缩,这样就可以得到所要播报的语音了。语音播放程序调用凌阳提供的音频编码算法库中的API函数,采用凌阳压缩算法中的SACM_S480进行自动放音,其语音自动播放程序流程图如下图5所示。语音播放是在中断服务程序中执行,本系统使用了FIQ_TMA中断源。语音播放通常会出现两种情况:一是系统能正确识别语音,此时的识别后处理是通过语音播报出正确的结果;二是系统不能正确识别语音,则播报出不能识别的原因。语音回放流程图如图5所示。

图5 语音回放流程图
4 总结
本文的创新点是设计的提出的嵌入式非特定人语音识别系统所选用的SPCE061A微处理CPU最高时钟可达到49MHZ,因此在处理复杂的数字信号方面它可以和DSP相媲美,但其价格却要比专用的DSP芯片廉价,并且它具有较强的中断处理能力,系统支持10个中断向量及10余个中断源,适合实时语音处理,并具有双通道10位DAC方式的音频输出功能,配置带自动增益控制功能(AGC)的麦克风输入方式,为语音处理带来了极大便利;其次,采用了离散隐马尔可夫模型来模拟语音信号,并且随着DHMM在语音模板的训练阶段计算复杂度的增加,识别阶段的计算负担相应的大大减少,对于特定人、小词汇量的语音控制系统己能满足要求。此项目投入市场后,半年内产生50余万的经济效益。
参考文献
[1]薛均义,张延斌,虞鹤松等.凌阳16位单片机原理及应用[M].北京航空航天大学出版社2003.72~89
[2]易克初等.语音信号处理.国防工业出版社[M].2000.11-15 ;154-172
[3]胡航.语音信号处理.哈尔滨工业大学出版社[M].2000.88-120
[4]胡凯,张颖超.生化分析仪的设计及与PC机的通信[J].微计算机信息.2006,9-1:20-22
[5]马鸿文.基于AT89C52单片机的自动存取柜的设计与实现[J].微计算机信息,2006,7-2:10-13.
矢量控制相关文章:矢量控制原理
评论