基于TMS320VC5507的语音识别系统实现

摘要:语音识别片上系统可以实现简单的人机交互和语音控制,在家电、玩具及各种人机交互系统中有着广泛的应用前景。本文结合汉语语音特点,在TMS320VC5507芯片上实现了高性能特定人与非特定人中小词汇量孤立词识别系统。采用基于循环缓冲区的端点检测算法,双缓冲区的传输方式用于语音录制和回放,分别采用降低特征维数的DTW算法和基于连续隐含马尔可夫模型(CDHMM)的多级搜索算法作为核心识别算法,并给出实验结果。
关键词:特定人;非特定人;片上系统;德州仪器;直接存储访问
1 语音识别片上系统概述
随着数字信号处理技术的发展,语音识别片上系统已成为人们研究的热点。然而,复杂的系统与硬件需求的矛盾,一定程度上限制了它的应用和推广。本文针对上述问题,采用相应的识别策略[1],合理安排算法流程,完成了高性能特定人与非特定人识别系统的片上实现。
2 硬件平台
DSP选型时需综合考虑运算速度、成本、功耗、硬件资源和程序可移植性等因素。本系统采用美国德州仪器(TI)生产的TMS320VC5507定点DSP作为核心处理器[2],并配合使用PLL时钟发生器、JTEG标准测试接口、异步通信串口、DMA控制器、通用输入输出GPIO端口以及多通道缓冲串口(McBSPs)等主要片内外设。系统硬件平台如图1所示。
VC5507 DSP芯片采用先进的多总线结构,内含64 K16 bit的片上RAM和64 KB的ROM;片内可屏蔽ROM固化有引导转载程序(Bootloader)和中断向量表等;采用流水线结构提高指令执行的整体速度。与C54x系列DSP不同的是,VC5507DSP的存储空间包括统一的数据、程序空间和I/O空间,寻址空间可达16 MB;片内包含两个算术逻辑单元(ALUs),在最高时钟频率200 MHz下,指令周期可达5 ns,最高速度可达400 MIPS。
存储器采用三菱公司生产的M5M29GB/T320VP系列Flash芯片。全片容量2 MW,分为128个扇区,通过外部存储器接口(EMIF)方式与读写时序接入DSP;采用2.7 V~3.6 V单电源供电。该系列Flash支持块编程操作[3],读写速度要快得多,有利于实时性的改善。
基金项目:国家自然科学基金资助项目60572083
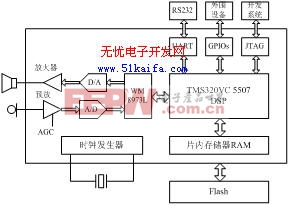
图1 语音识别系统硬件框图
A/D、D/A转换器采用英国Wolfson公司生产的WM8973L芯片。该芯片支持16位A/D、D/A转换,具有可编程输入输出增益控制,可通过软件设置8~96 KHz的多种采样频率[4]。
3 软件结构
3.1 系统概述
特定人识别系统采用12维MFCC参数作为识别引擎的特征参数,训练与识别都是在片上实时实现的,系统框架如图2(a)所示。在训练阶段,由片上实时提取每个词条的特征参数存放到Flash中作为模板库。在识别阶段,将待识别词条实时提取特征参数、端点检测以后,利用动态时间规整(DTW)算法与模板库中的所有模板进行匹配,选择失真度最小的模板作为识别结果。当词表改变时,只需调整Flash存储方式,算法本身无需改动。

(a) 特定人系统
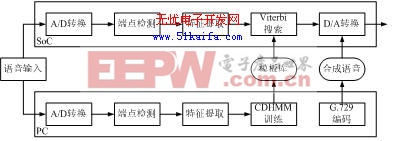
(b) 非特定人系统
图2 识别系统框架
非特定人识别系统的输入特征矢量为27维,包括12维MFCC、12维MFCC一阶差分、一阶对数能量、一阶差分能量以及二阶差分能量。系统以基于因素的CDHMM模型为基本识别框架,采用Viterbi解码的帧同步搜索算法进行识别。HMM模型训练事先在PC机上进行,而Viterbi搜索则在DSP芯片上实时实现,整个系统为双层结构,如图2(b)所示。
训练阶段主要完成如下任务:给定一个HMM模型和一组观察矢量集合,采用迭代算法调整模型参数,使得新模型和给定的观察矢量集合的似然度最大。首先用初始模型估计观察矢量由隐含层所有可能的状态序列输出的后验概率,然后根据前一步的估计结果,利用最大似然准则估计新的HMM模型,所得到的参数用作下一次迭代。识别阶段采用Viterbi搜索,所构建的识别网络包括状态号和状态连接关系等信息。为了减少网络搜索的内存占用量,采用每个词条单独建立网络的方法,使得每个词条的搜索过程可在内存中独立进行[5]。
3.2 语音传输与中断程序设计
受硬件条件限制,系统的多任务调度是由中断服务机制完成的。除了Reset和非屏蔽中断(NMI)外,还设置了两个DMA通道中断。其中DMA通道2负责将麦克风录制的语音数据送至DSP内核进行运算处理;DMA通道3负责将回放语音数据传送至扬声器输出。
在内存中,分别设有两个128 W的接收缓冲区和发送缓冲区。以接收端为例,对于8 kHz采样语音,每0.125 ms接收一个16 bits的采样数据,存入其中一个接收缓冲区中。16 ms后,该接收缓冲区满,由DMA控制器向CPU发出中断请求,进行VAD、特征提取等操作。与此同时,另一个接收缓冲区继续接收语音数据。这种数据传输方式又称为Ping-Pong传输,接收和发送分别设置两个缓冲区,利用等待时隙,当其中一个缓冲区数据传输完成,产生中断时,另一缓冲区继续工作。这种双缓冲区传输方式可以明显改善系统实时性能。
3.3 端点检测
输入到硬件平台的语音信号前后经常含有大量静音或噪声。出于节省硬件资源的考虑,需要引入端点检测算法。为了兼顾实时性能和硬件资源占用率,并防止语音切分过严而影响识别性能,采用基于循环缓冲技术的四阶段语音实时检测方法,将每帧语音能量与阈值相比较,同时依次存入长度为 的循环缓冲区并记录当前位置。算法流程如图3所示,其中 、 、 、 、 为事先设定的阈值,它们是通过大量测试得到的。当检测到连续 帧语音能量高于阈值时,将循环缓冲区从当前位置断开,倒退 帧作为语音起始点。

(a) 端点检测基本流程
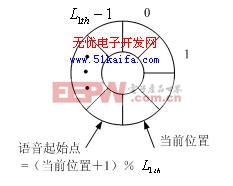
(b) 循环缓冲区设计
图3 基于循环缓冲区的端点检测流程
3.4 特定人识别系统的特征提取与DTW模板匹配
实验表明,采用12维MFCC系数作为特征参数,既可以节省内存空间,又不会对识别率造成很大影响。每帧语音特征参数在内存数据空间中连续存放。采取动态时间规整(DTW)算法,其本质是一种宽度优先的模板匹配过程,即将待识别词条的特征矢量序列与每个模板进行比较,找到一条总失真度最小的路径作为识别结果[6]。DTW算法简单,计算量小,占用内存小,可以解决语速不均匀的问题,适用于特定人小词汇量的孤立词识别系统。
3.5 非特定人识别系统的多级Viterbi搜索与硬件资源消耗分析
非特定人识别基线系统难于在片上实现的瓶颈在于识别时间过长。事实上,如果声学模型构造合理,绝大多数错误结果的似然度往往与正确结果相差较远。因此,本系统采用的基于Viterbi解码的两阶段搜索策略,可以很大程度上缓解识别时间过长的问题。
第一阶段为快速匹配阶段。利用较为简单的208个状态的单音子声学模型,给出匹配程度最高的前Nbest个候选词条,送入第二阶段。第一阶段所占用的主要内存空间有:词条的所有特征,在使用27维特征,最大有效语音长度为128帧情况下,需要6.8 KB;输出分数矩阵,其大小由最大有效语音长度和模型数量决定,是内存开销最主要的部分,在这里需要占用约62 KB的内存;所有词条的对数似然度,200词的情况下为0.8 KB。
第二阶段为精确匹配阶段,采用较复杂的358状态双音子模型,根据第一阶段候选词条构建新的识别网络,进行搜索识别。为了节约内存占用量,设定第一阶段候选词条数量的上限为8,这样,第二阶段可能出现的有效状态数量不会超过208个,从而可以使占用内存最大的输出概率矩阵复用第一阶段输出概率矩阵所占用的那段内存,提高内存使用效率[7]。
4 实验结果
录音环境为办公环境,8 kHz采样,16 bit量化,每个词条最大持续时间为2 s,端点检测的循环缓冲区长度 =7 W。特定人识别系统的测试语音为本实验室自录的100个孤立词人名词表,识别结果如表1所示。非特定人识别系统的训练集为863男生连续语音数据,测试语音为200词的人名词表。第一阶段多候选识别结果如图4所示。可见,虽然一候选的识别率不足94%,但随着候选词条数的增加,正确识别结果几乎都包含在第一阶段前几选的识别结果中。本文选用的八候选策略的识别率可以达到99.5%。系统最终识别结果如表2所示,识别率仅从基线系统的98.5%下降到97.5%,而识别时间仅为基线系统的30%。
表1 特定人系统识别性能
识别率 | 98.00% | |
识别时间(倍实时) | 0.13 | |
内存空间占用 | 程序空间 | 39 KB |
数据空间 | 22 KB | |
表2 非特定人系统识别性能
基线系统 | 识别率 | 98.50% |
识别时间(倍实时) | 1.00 | |
本系统识别率 | 一阶段多候选识别率 | 99.50% |
二阶段第一选识别率 | 97.50% | |
识别时间(倍实时) | 0.34 | |
本系统内存空间占用 | 程序空间 | 29 KB |
数据空间 | 94 KB |
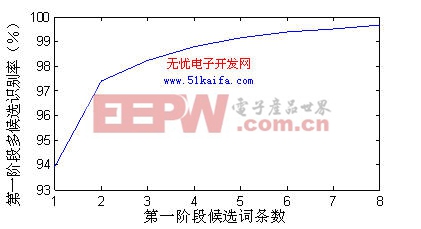
图4 非特定人系统第一阶段多候选识别率
5 结论
本文提出了一种基于定点DSP的特定人与非特定人语音识别片上系统的实现方法。通过降低特征维数,改进语音预处理与识别算法等手段,在保证识别性能的前提下,实现了硬件资源的高效率利用。在运算速度为288 MIPS,工作时钟为144 MHz的条件下,特定人与非特定人识别系统识别率分别为98%与97.5%,识别时间分别为0.13倍实时和0.34倍实时。
本文的创新点在于:采用基于循环缓冲技术的四阶段实时端点检测算法,以及基于双缓冲区的语音传输方式,在核心识别算法的处理中,选择合适的特征维数,合理优化识别算法流程,在保证识别性能不受影响的前提下,有效改善了硬件资源占用率与系统实时性能。
参考文献
[1] Zhu Xuan, Chen Yining, Liu Jia, et al. A Novel efficient decoding algorithm for CDHMM-based speech recognizer on chip [A]. Proceeding of ICASSP [C]. Hong Kong: IEEE Press, 2003, 293-296
[2] SPRS244F. TMS320VC5507 Fixed-Point Digital Signal Processor [S]. Texas: Texas Instruments, 2005
[3] MITSUBISHI LSIs M5M29GB/T320VP-80 BLOCK ERASE FLASH MEMORY [S]. 2001
[4] WM8973L Stereo CODEC for Portable Audio Applications [S]. Edinburgh: Wolfson microelectronics, 2004
[5] 朱璇,陈一宁,刘加,刘润生. 语音识别片上系统中的多级搜索算法[J]. 电子学报,2004,32(1):150-153.
[6] 陈立万. 基于语音识别系统中DTW算法改进技术研究[J]. 微计算机信息,2006,第5期,267-269
[7] 王瑞. 基于子词模型的嵌入式语音识别引擎的设计和实现[D]. 北京:清华大学,2003






评论