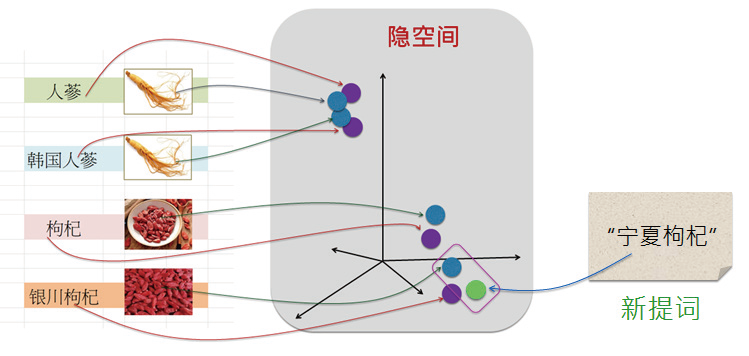
- 1 前言AIGC可生成的内容形式包含文本( 文句)、图像、音频和视频。它能将文本中的语言符号信息或知识,与视觉中可视化的信息( 或知识) 建立出对应的关联。两者互相加强,形成图文并茂的景象,激发人脑更多想象,扩大人们的思维空间。其中,最基础的就是文本(Text) 与图像(Image) 之间的知识关联。本篇来介绍文本与图像的关联,并以CLIP 模型为例,深入介绍多模态AIGC 模型的幕后架构,例如隐空间(Latent space) 就是其中的关键性机制。2 简介CLIP模型在2020 年,OpenAI 团队
- 关键字:
202305 从隐空间 CLIP多模态模型
从隐空间介绍
您好,目前还没有人创建词条从隐空间!
欢迎您创建该词条,阐述对从隐空间的理解,并与今后在此搜索从隐空间的朋友们分享。
创建词条
关于我们 -
广告服务 -
企业会员服务 -
网站地图 -
联系我们 -
征稿 -
友情链接 -
手机EEPW
Copyright ©2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《电子产品世界》杂志社 版权所有 北京东晓国际技术信息咨询有限公司

京ICP备12027778号-2 北京市公安局备案:1101082052 京公网安备11010802012473