六大门派,围攻云端AI芯片光明顶

编辑 | 漠影
AI芯片的战场,明显更热闹了。就在上周五,国际权威人工智能(AI)性能基准测试MLPerf公布了最新的数据中心及边缘场景AI推理榜单结果,无论是参与评选的企业还是实际AI芯片表现,都比往届多了不少看头。
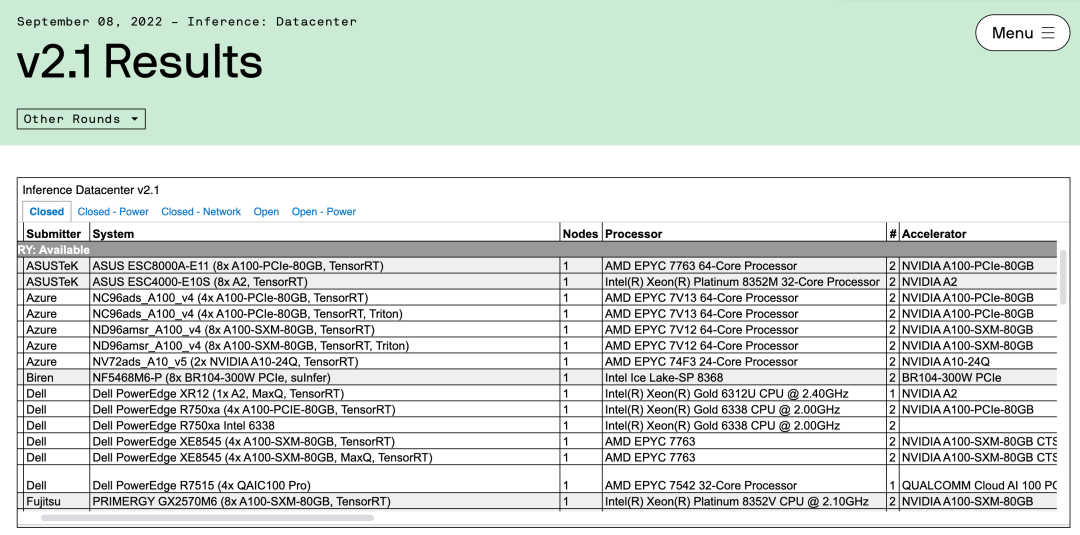
MLPerf数据中心推理榜单:
https://mlcommons.org/en/inference-datacenter-21/
MLPerf边缘推理榜单:
https://mlcommons.org/en/inference-edge-21/
01.H100王者登场,英伟达仍然称雄
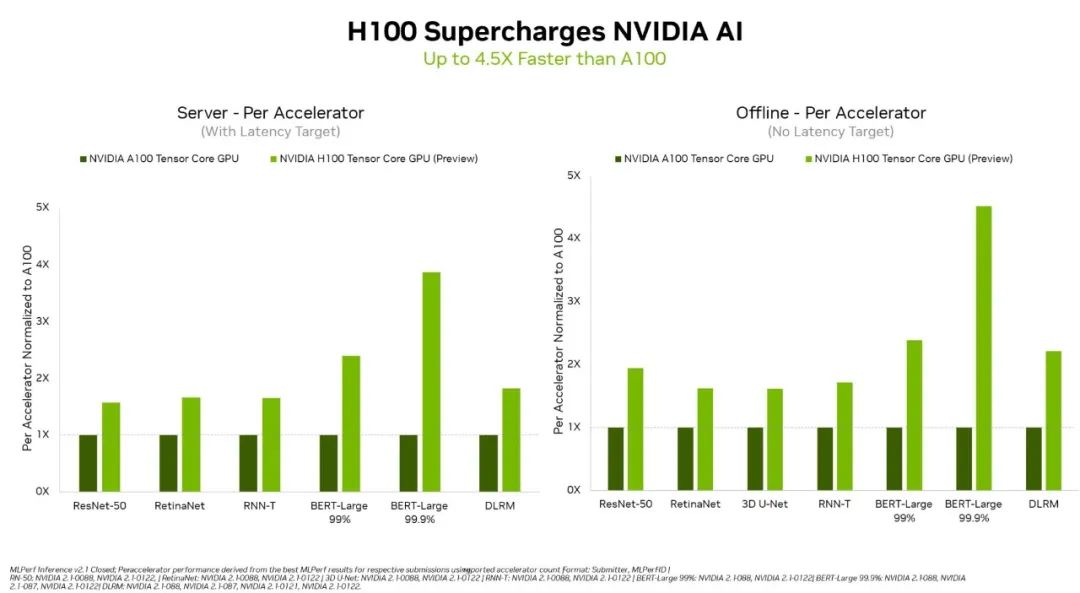
▲英伟达H100性能比A100高出4.5倍(图源:英伟达)
英伟达基于H100 GPU单芯片提交了两个系统,一个系统配备AMD EPYC CPU作为主机处理器,另一个系统配备英特尔至强CPU。可以看到,虽然采用英伟达最新Hopper架构的H100 GPU这次只展示了单芯片的测试成绩,其性能已经在多个情况下超过有2、4、8颗A100芯片的系统的性能。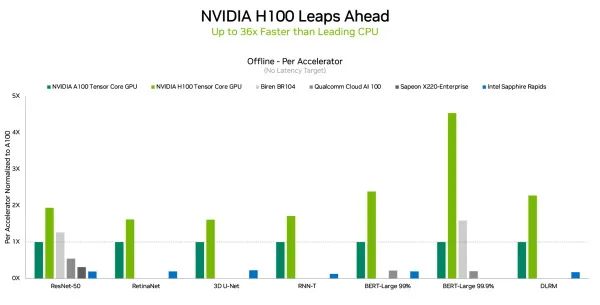
▲英伟达H100在数据中心场景所有工作负载都刷新性能记录(图源:英伟达)
特别是用在对更大规模、更高性能提出要求的自然语言处理BERT-Large模型上,H100的性能比A100和壁仞科技GPU超出一大截,这主要归功于其Transformer Engine。H100 GPU预计在今年年底发布,后续还会参加MLPerf的训练基准测试。此外,在边缘计算方面,将英伟达Ampere架构和Arm CPU内核集成在一块芯片的英伟达Orin,运行了所有MLPerf基准测试,是所有低功耗系统级芯片中赢得测试最多的芯片。值得一提的是,相比今年4月在MLPerf上首次亮相的成绩,英伟达Orin芯片的边缘AI推理能效进一步提高了50%。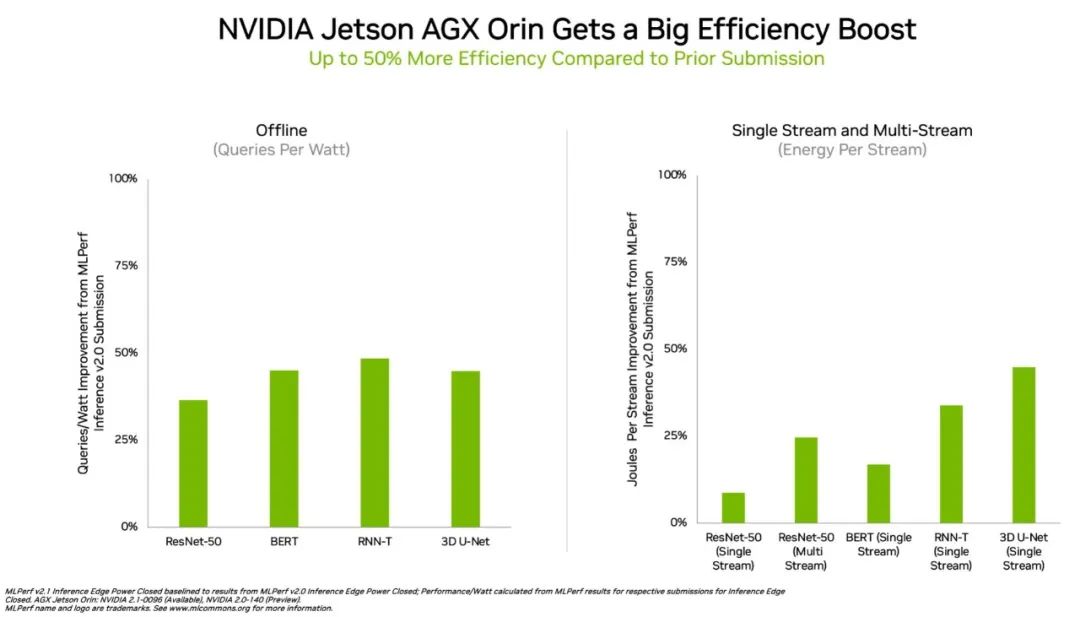
▲在能效方面,Orin边缘AI推理性能提升多达50%(图源:英伟达)
从英伟达往届在MLPerf提交的测试结果,可以看出AI软件带来的性能提升越来越显著。自2020年7月在MLPerf上首次亮相以来,得益于NVIDIA AI软件的不断改进,A100的性能已经提升6倍。目前,NVIDIA AI是唯一能在数据中心和边缘计算中运行所有MLPerf推理工作负载和场景的平台。通过软硬协同优化,英伟达GPU在数据中心及边缘计算中实现AI推理加速的成绩更加突出。02.壁仞科技通用GPU参战ResNet和BERT模型性能超A100
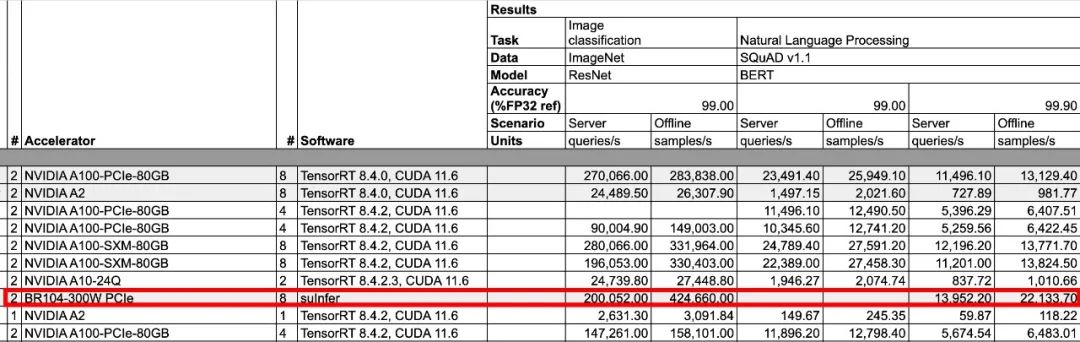
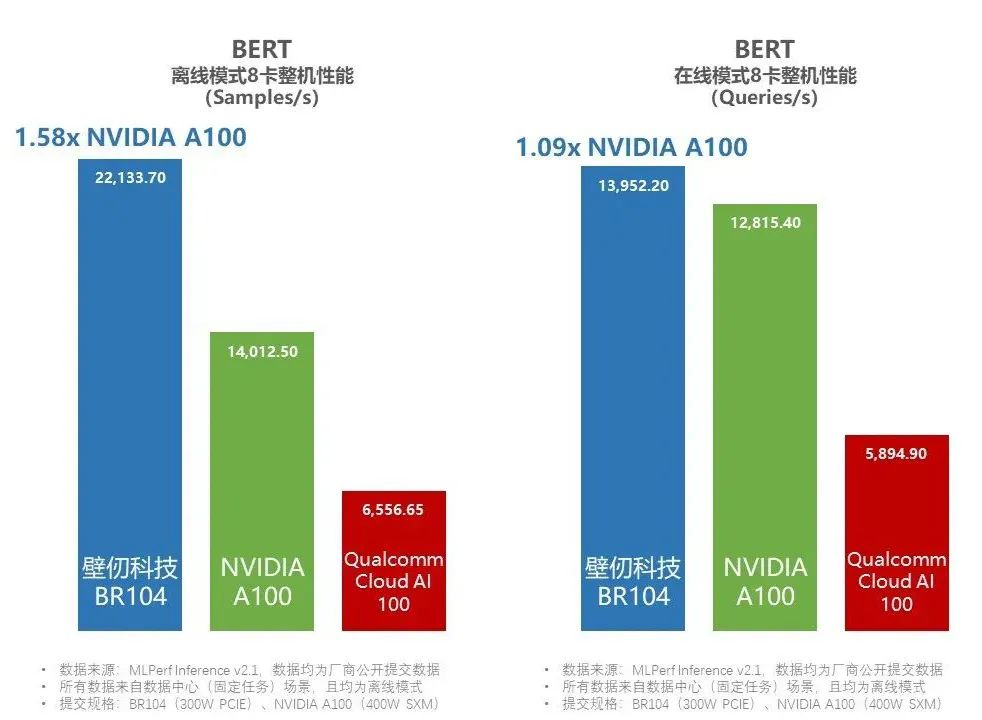
▲壁仞科技BR104在BERT模型评选中同时拿下离线和在线模式的整机性能领先(图源:壁仞科技)
从测试结果来看,在BERT模型的评选中,相较于英伟达提交的基于8张A100的机型,基于8张壁仞科技BR104的机型,性能达到了前者的1.58倍。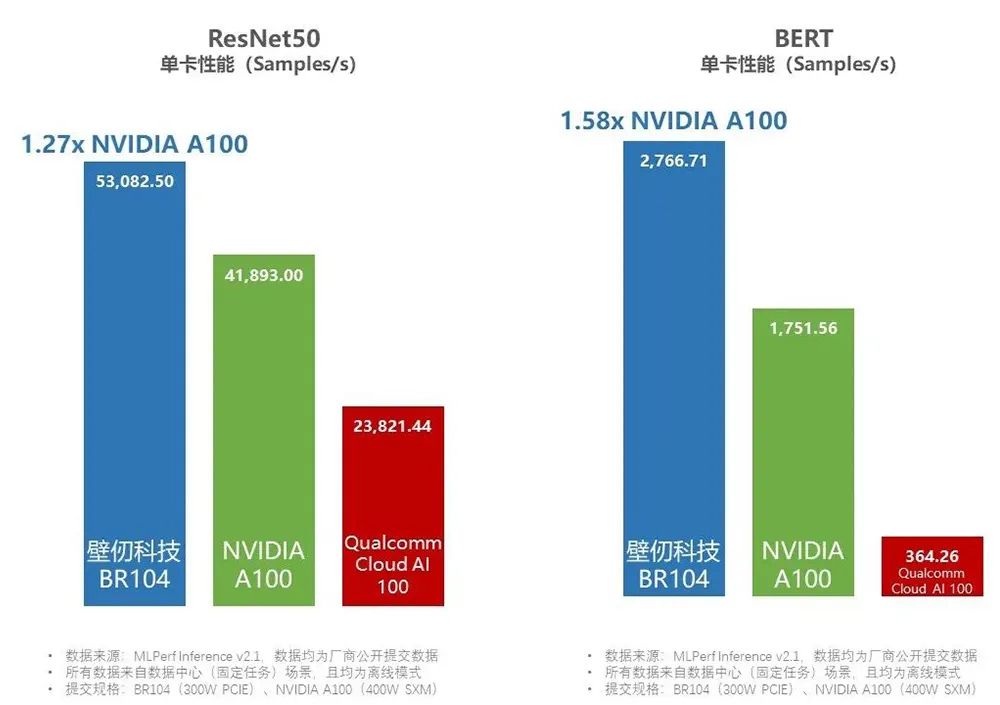
▲壁仞BR104在ResNet-50和BERT模型评选中单卡性能超过A100
总体来看,壁仞科技8卡PCle解决方案的性能表现,估计会介乎英伟达8卡A100与8卡H100之间。除了壁仞科技自己提交的8卡机型外,知名服务器提供商浪潮信息还提交了一款搭载4张壁砺104板卡的服务器,这也是浪潮信息首次提交基于国产厂商芯片的服务器测试成绩。在所有的4卡机型中,浪潮提交的服务器在ResNet50(Offline)和BERT(Offline & Server, 99.9%精度)两个模型下,也夺得了全球第一。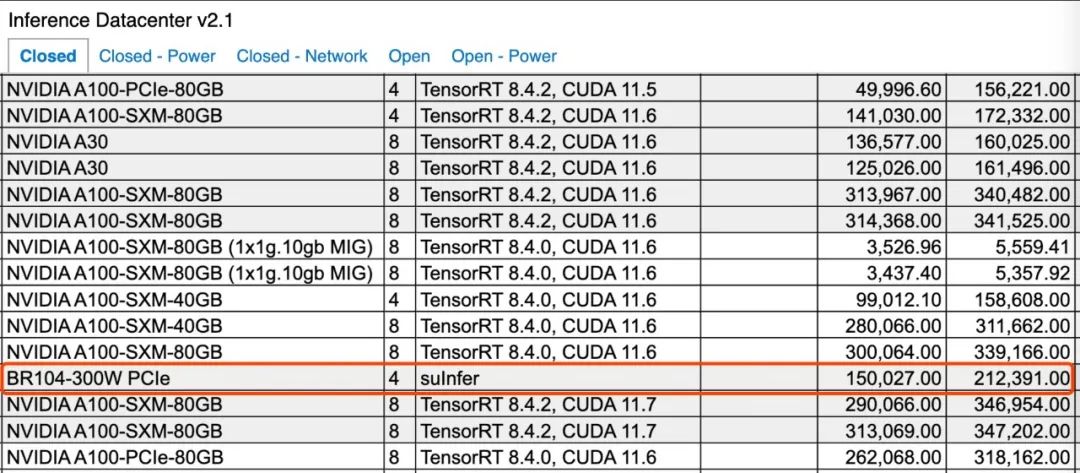
03.墨芯S30夺魁图像分类单卡算力95784 FPS远超H100

▲墨芯人工智能S30计算卡
此次墨芯参加的是开放优化类的测试。根据最新MLPerf推理榜单,墨芯S30计算卡以95784FPS的单卡算力,夺得ResNet-50模型算力第一,是H100的1.2倍、A100的2倍。在运行BERT-Large高精度模型(99.9%)方面,墨芯S30虽未战胜H100,却实现了高于A100性能2倍的成绩,S30单卡算力达3837SPS。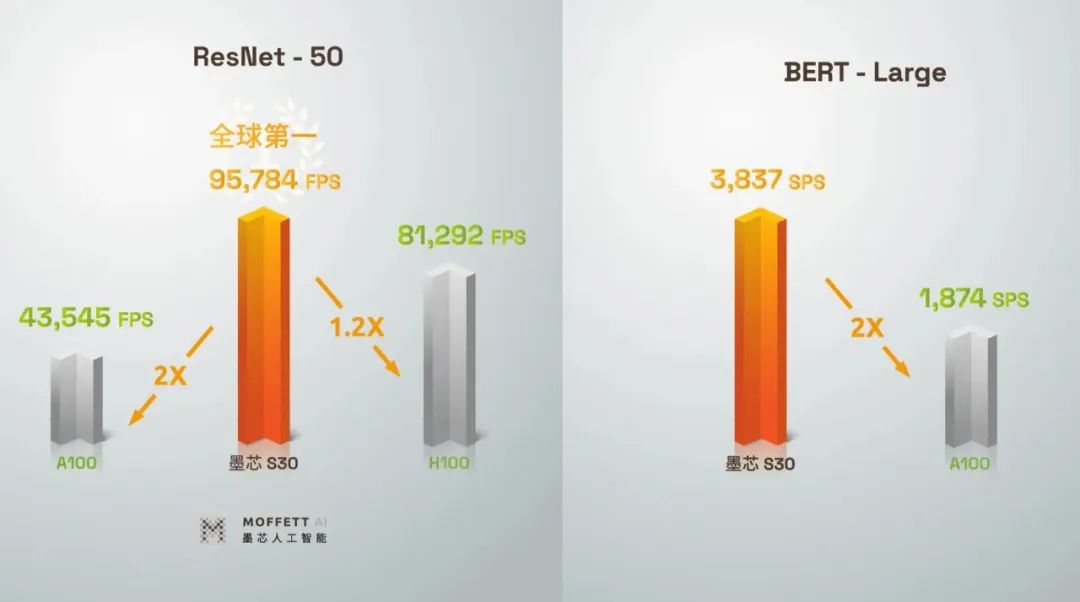
▲运行ResNet-50和BERT-Large模型时,墨芯S30与A100、H100的对比(图源:墨芯人工智能)
值得一提的是,墨芯S30采用的是12nm制程,而英伟达H100采用的是更先进的4nm制程,能够在制程工艺存在代际差的情况下追平两大数据中心主流AI模型的性能表现,主要得益于墨芯自主研发的稀疏化算法及架构。MLPerf的测试要求非常严格,不仅考验各产品算力,同时设置精度要求在99%以上,以考察AI推理精度的高要求对计算性能的影响,也就是说参赛厂商不能以牺牲精度的方式换取算力提升。这亦证明了墨芯能做到在实现稀疏化计算的同时兼顾精度无损。04.高能效,高通云端AI芯片的王牌

▲高通Cloud AI 100
MLPerf最新披露的评测结果中,富士康、创通联达(Thundercomm)、英业达(Inventec)、戴尔、HPE和联想都提交了使用高通Cloud AI 100芯片的测试成绩。可以看出,高通的AI芯片已经在被亚洲云服务器市场接纳。高通Cloud AI 100有两个版本,专业版(400 TOPS)或标准版(300 TOPS),都具有高能效的优势。在图像处理方面,该芯片的每瓦性能比标准部件的NVIDIA Jetson Orin高1倍,在自然语言处理BERT-99模型方面的能效亦是略胜一筹。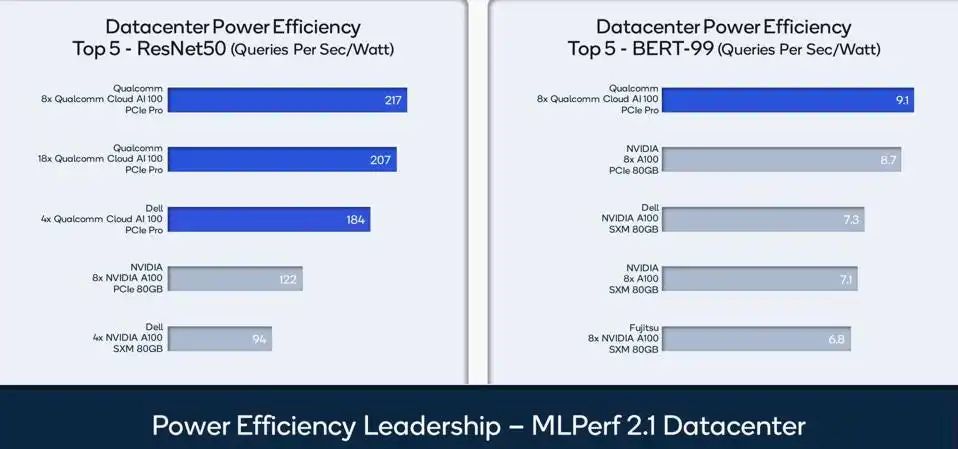
▲高通Cloud AI 100在ResNet-50及BERT-99模型测试中的能效比领先(图源:高通)
在保持高能效的同时,高通的AI芯片并没有以牺牲高性能为代价,一台5卡服务器功耗75W,可实现的性能比2卡A100服务器高出近50%。而单台2卡A100服务器的功耗高达300W。
▲高通Cloud AI 100的每瓦性能表现(图源:高通)
面向边缘计算,高通Cloud AI 100在图形处理方面展现出的高能效已经非常有竞争力,不过大型数据中心对芯片的通用性会有更高要求,如果高通想要进一步打入云端市场,可能得在下一代云边AI芯片的设计上扩展对推荐引擎等更多主流AI模型的支持。
▲实现边缘服务器高能效,不以牺牲高性能为代价(图源:高通)
05.韩国首款AI芯片亮相对打英伟达入门级AI加速卡

▲Sapeon X220部分参数
其测试结果也很有意思。Sapeon X220搭载于Supermicro服务器上,在数据中心推理基准测试中的性能超过了英伟达去年年底发布的入门级AI加速卡A2 GPU。其中,X220-Compact的性能比A2高2.3倍,X220-Enterprise的性能比A2提升4.6倍。能效表现同样不错,在基于最大功耗的每瓦性能方面,X220-Compact的能效是A2的2.2倍,X220-Enterprise的能效是A2的2.0倍。
▲Sapeon X220系列与英伟达A2的性能及能效对比(图源:SAPEON)
值得一提的是,英伟达A2采用的是先进的8nm制程,而Sapeon X220采用的是28nm成熟制程。据悉,Sapeon芯片已经应用在智能音箱、智能视频安全解决方案、基于AI的媒体质量优化解决方案等应用中。今年SK电讯还将AI芯片业务独立出来,成立了一家名为SAPEON的公司。SAPEON首席执行官Soojung Ryu透露说,未来该公司计划拓展X220的各个应用领域,有信心在明年下半年用下一代芯片X330与竞品拉开差距,进一步提高性能。06.英特尔预览下一代服务器CPU阿里倚天710 CPU首参评
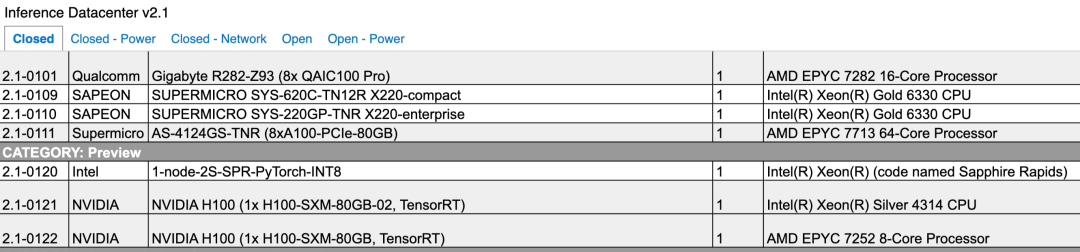
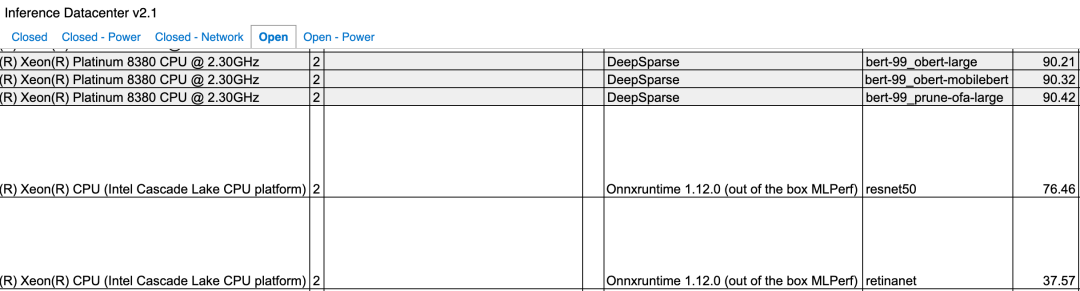
07.结语:英伟达江湖地位稳固国产AI芯片新势力发起冲锋

公众号
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
