英特尔首个使用EUV的工艺:退钴还铜

关注公众号,点击公众号主页右上角“ · · · ”,设置星标,实时关注半导体行业最新资讯
来源:半导体芯闻

在本周早些时候在夏威夷举行的 2022 年 IEEE VLSI 技术和电路研讨会上,英特尔展示了许多涉及其英特尔 4 工艺的论文。这些论文主要由英特尔公司技术开发副总裁 Ben Sell 发表。
Intel 4
这个新节点称为 Intel 4。出于所有实际目的,它是适当的 10 纳米继任者。换句话说,如果它在 2020 年发布,它应该被正确地称为“7nm”。今天,它被称为“Intel 4”,是“Intel 7”(以前称为“10nm Enhanced SuperFin”,以前称为“10nm++”)的继任者。
Intel 4 很好但很奇怪,真的很奇怪。在时间方面,英特尔预计这一制程将在今年晚些时候加速——这意味着会是明年产品使用的工艺。如果一切按计划进行,Intel 4 的继任者“Intel 3”将在几乎整整一年之后(2023 年底开始升级)。这应该开始让您了解英特尔如何看待这个制程。
在深入研究细节之前,我们想强调一下Intel 4 并非设计为一个典型的成熟(full-fledged)节点。虽然它是一个高容量(high-volume )节点,但它可以在其上制作的内容非常有限(因此可能会大大限制其容量)。例如。它不会提供许多您通常会从英特尔节点看到的大型库,例如高密度和中档性能密度库,这些库对图形和其他应用程序等事物很重要,但对 CPU 核心设计来说,这并不重要。
从这个角度看,英特尔的这个节点是为为那些想把使用不同工艺的chiplet合封到一起的compute tile而准备的。
从小处着手,让它发挥作用,建立起来
从历史上看,该公司专注于推出传统上所谓的全节点——大约每两年推出一个节点,带来整整一代的改进。代工厂(例如,台积电以及十年前的富士通、东芝、NEC 等)过去常常引入称为半节点的后续节点,这将进一步改进节点以及较小的间距缩放。
前提很简单:扩展和增强现有的高收益节点既便宜又容易。
而传统的“全节点”和“半节点”模型被淘汰了。随着最近 FinFET 节点的复杂性激增,代工厂转向新的“nodelet”方案。在此模型下,首先引入一个基本节点(例如,7LPP 或 N7),然后由一个或多个增强节点(nodelet)接替,几乎每年都会带来微小但增量的变化(例如,N7P、N7+、 N6,6LPP)。
快速接替Intel 4 的是Intel 3,预计将在明年年底推出。该公司表示,该制程将引入新的库,在密度、功率和性能方面都比Intel 4 有所提高。此外,Intel 4 与Intel 3 向前兼容,使设计迁移更容易。更重要的是,Intel 3 将拥有完整的代工产品。
在许多方面可以看出,英特尔都在借鉴代工手册。很明显,他们正在限制Intel 4 特性和功能的复杂性以降低风险。此外,他们今年推出 Intel 4 的能力将对他们明年按时将 Intel 3 推向市场的能力发挥重要作用,而正确执行是最重要的。他们的目标是构建更广泛、改进的功能组合、库、和其他 IP ,这在成熟的制程中要容易得多,并且这是解决此问题的正确方法。鉴于Intel 3 被定位为英特尔代工服务 (IFS) 的初始旗舰节点,这一点至关重要。
由于Intel 4 的范围有限,并且其快速跟进的成熟Intel 3 节点具有全节点密度/PPA 特性,我们认为最好将Intel 4 视为临时权宜之计节点。
产品
在诸如 IEEE VLSI Symposium 等技术会议上,英特尔通常将其演讲的范围仅限于其工艺的技术方面。在这个相当罕见和不寻常的场合,Sell 谈到了即将推出的第一款 Intel 4 产品——Meteor Lake。采用 Intel 4 的 Meteor Lake 将成为 3D foveros 封装技术的量产产品。Intel 4 支持最新的封装技术,并为 Foveros 提供了更激进的微凸点间距——从 50μm 扩展到 36μm。Meteor Lake 包含一个图形tiles、SoC tiles、计算tiles和 I/O tiles,所有这些都位于一个 Si 中介层上。Meteor Lake 封装和 die shot 如下所示。
制程概述
极紫外 (EUV) 光刻
自对准四边形图案 (SAQP)
有源栅极接触 (COAG)
单虚拟门 (SDB)
增强型铜互连

在进一步讨论之前,我们想重申一下,由于使用该节点的产品有限,Intel 4 将仅提供高性能单元库。通常,英特尔至少为逻辑设计了三个标准库。例如,使用英特尔 10nm,该公司拥有高密度单元、高性能/移动性能单元和超高性能单元。虽然它们使用相同的底层晶体管,但它们的特点是性能、功率和密度特性是 pMOS 和 nMOS 器件的函数。对于 FinFET 器件,这是鳍片数量的直接函数。因此,英特尔 10nm 具有每个器件可容纳 2 个鳍的 HD 单元、每个器件可容纳 3 个鳍的 HP 单元和每个器件可容纳 4 个鳍的 UHP 单元。
扩展(Scaling)是 DTCO-Heavy
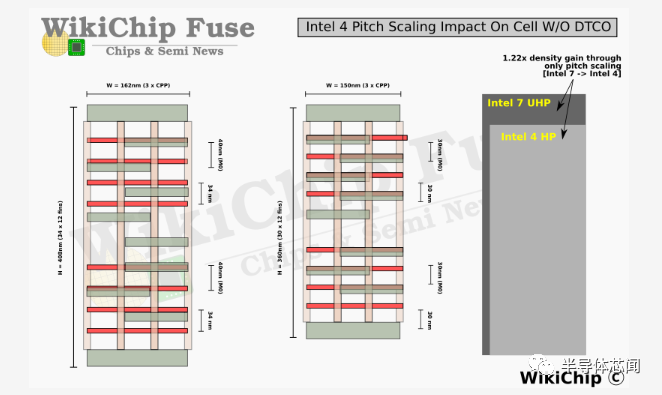
首先,intel 4 使用第二代 COAG 和第二代单虚拟门,允许它们随着新的栅极和鳍片间距进行扩展,同时保持单元高度和单元宽度的优势,从而实现我们在intel 7 中看到的密度改进。以前,英特尔在 nMOS 和 pMOS 器件之间的区域(栅极输入的前接触区域)有两条扩散线(diffusion lines)的间距。Intel 4 利用了单元的这一区域并消除了其中一条扩散线,从而缩短了单元高度并获得了宝贵的空间。我们估计仅此一项就产生了大约 11.5% 的面积缩放。
最后,由于其更高的性能,intel 4 经历了 4:3 的鳍片减少。这是对整体面积额外缩小 25% 的最大贡献。总而言之,DTCO 在传统pitch缩放的基础上增加了 1.5 倍的缩放。这证明了 DTCO 在现代前沿节点中的重要性,以及 STCO 将如何在引入未来技术(如埋入式电源轨和背面供电网络)中发挥更大的作用。

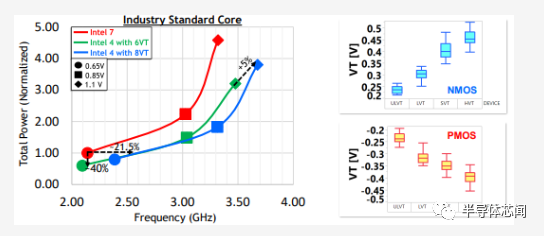
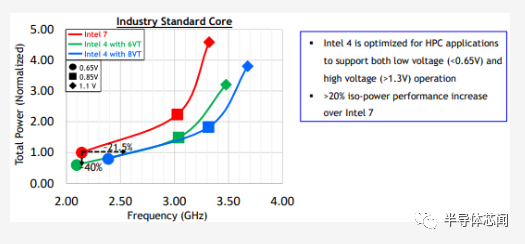
密度
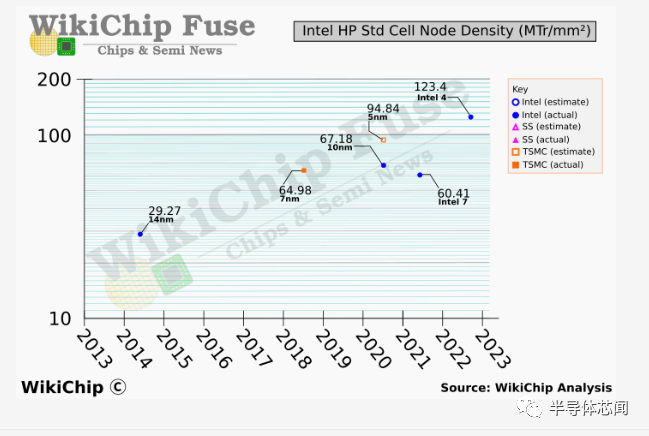
我们自己的估计表明,intel 4 的密度比英特尔 7/10nm 提高了 1.83 倍。但是,我们的估计还表明,intel 4 提供的密度比intel 7 提高了 2.04 倍。这是怎么算出来的?答案实际上在英特尔自己的 VLSI 演示幻灯片中。
随着 10 纳米 SuperFin 及其后继产品增强型 SuperFin(现在称为 Intel 7)的推出,英特尔推出了一种具有 60 纳米多晶间距的新型晶体管,以实现更高的驱动电流性能。在生产性能显著提高的晶体管的同时,它的不利影响是将逻辑密度降低了 0.9 倍。值得注意的是,这些cell被用于Alder Lake中的 Golden Cove 和 Gracemont 核心。
为此,我们估计intel 4 密度为 123.4 MTr/mm²,是英特尔 7 中 60.5 MTr/mm² 的 2.04 倍。我们对 TSMC N5 的数据非常不完整,但我们基于已知间距的粗略估计将其 HP 库为 94.85 MTr/平方毫米。根据最近公开的大多数代工数据,intel 4 HP 单元似乎比 TSMC N5 HP 更密集,并且可能更接近或优于 TSMC N3 HP 单元,并且比三星的 3GAE 更密集。鉴于过去三年 10nm 对公司造成的动荡,以这样的数字出现是相当令人惊讶的。它还强烈表明intel 3 可以匹配并超越即将推出的 3nm 级代工产品。
互连
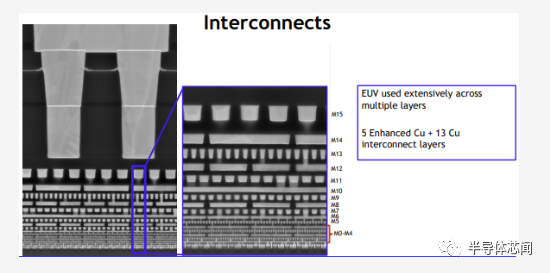
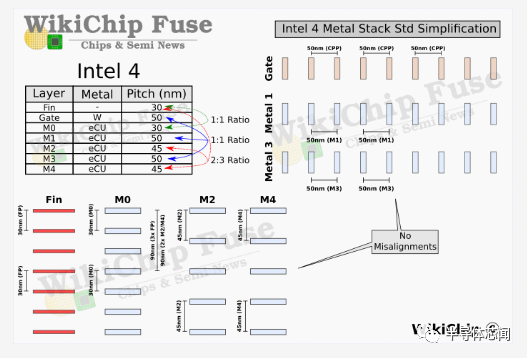
Intel 4 的基本设计规则的一个亮点如下所示,与具有 17 个金属层的 Intel 7 相比,Intel 4 增加了一层。M4 上方的大多数互连都看到了通常的间距缩小,其中大部分在 0.7x-0.85x 缩放左右。与之前的节点一样,两个顶层是厚金属层。与大多数其他wires相比,英特尔大幅缩小了最后一层厚金属层。最受关注的区域是前四个路由层(routing layers)。在那里,不仅某些间距没有缩小,有些实际上变宽了。这些层也经历了新的材料变化。
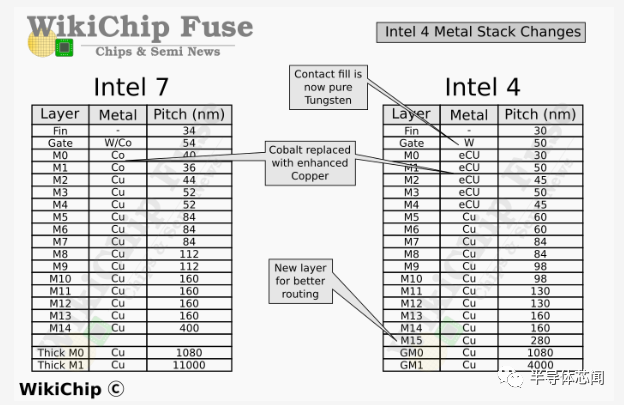
在 Intel 7 中,M1 层非常激进的鳍片间距意味着该公司采用了 3:2 的间距比。这有一些奇怪的副作用。在Intel 4 中,英特尔实际上将间距缩小了近 1.4 倍,以通过相同的间距将其固定到门上。正如我们将在下面展示的那样,这不仅简化了设计,而且完全消除了布局的一些不合适。英特尔似乎对 M3 层做了同样的事情。我们在这里的最后观察涉及也与鳍平行的 M2 和 M4 层。这些具有2:3的比例。
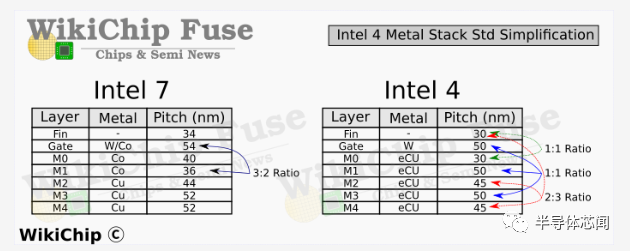
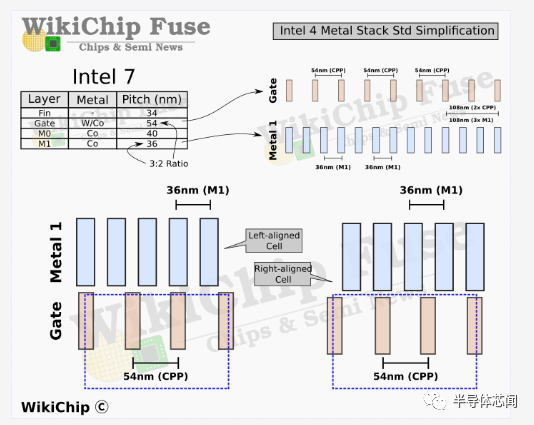
为了简单起见,Intel 4 显然完全放弃了该方案。M1 和 M3 层现在都与poly挂钩,完全消除了这种错位问题。有趣的是,该公司还将 M0 轨道固定在鳍上。那些垂直于多边形。在 Intel 7 中具有 44nm 和 52nm 间距的上 M2 和 M4 层在 Intel 4 中都具有 45nm。从布局的角度来看,选择 45nm 是非常清楚的,因为它们现在以 2 :3的比例固定在鳍片上。请记住,由于单元格高度是一个固定属性,因此在该方向上没有对齐问题。
铜回来了
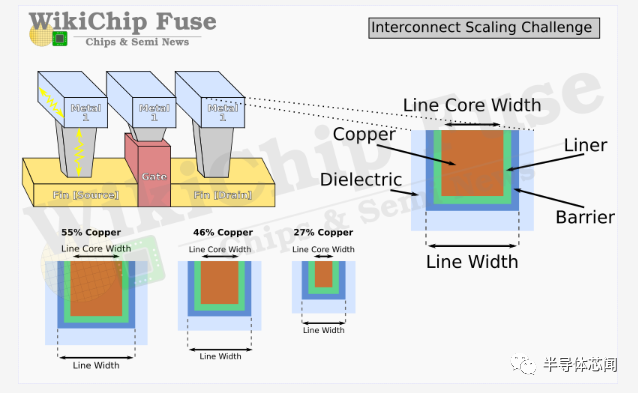
在下图中,英特尔展示了intel 7 与具有钽阻挡层(Tantalum barrier )的纯钴内核与具有氮化钽阻挡层(Tantalum nitride barrier)的传统铜合金内核之间的关系。这两个选项具有互补的属性。纯 Co 提供了相当好的电迁移特性,但提供了更差的线路电阻。同样,Cu 合金提供更好的线路电阻但更差的电迁移寿命。事实上,与纯钴相比,铜合金提供了 0.75 倍的线路电阻,这是相当大的电阻下降。对于 Intel 4,该公司选择在最低的四个金属层中使用增强型铜 (eCu)。这种增强的铜线包括一个钽阻挡层,而在纯铜芯周围也有钴包层。
内存
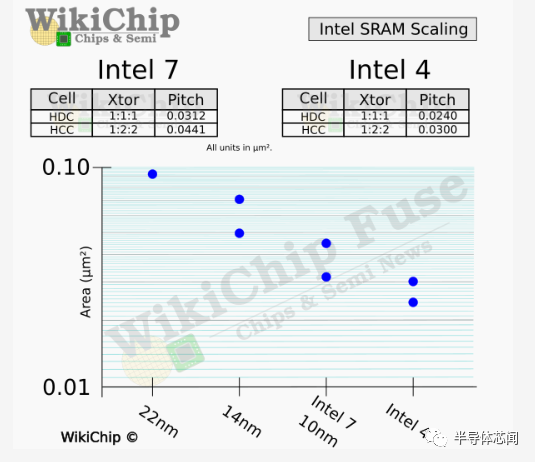
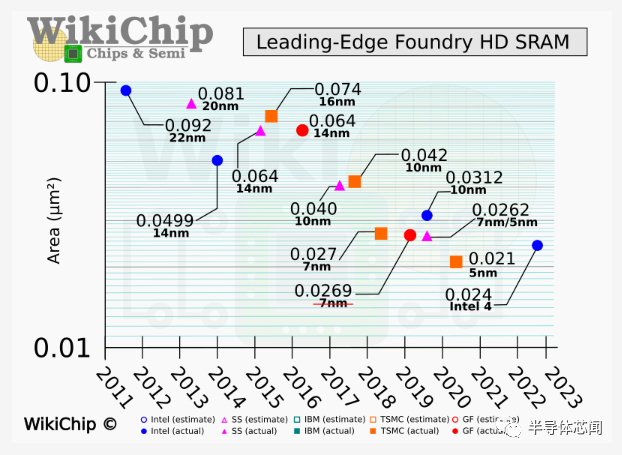
Intel 4 引入了两个标准的 6T SRAM 单元——高密度和大电流单元。高密度 (PU:PG:PD = 1:1:1) cell从 0.0312 平方微米缩小到 0.0240,而高性能 (PU:PG:PD = 1:2:2) cell缩小到 0.0300 平方微米. 这些cell分别看到了 0.77 倍和 0.68 倍的缩放比例,这与我们过去看到的约 0.6 倍的历史缩放比例相去甚远。除了 6T 单元之外,英特尔还开发了一个 8T SRAM 位单元,它在 6T 写入端口的基础上增加了一个 3 鳍读取端口,总面积为 0.0360 平方微米。虽然占用 1.74 倍的面积,但它使用的读/写能量分别比 HDC 和 HCC 低 6 倍和 12 倍。
电容器
结论
在 2022 年 IEEE VLSI 技术和电路研讨会上,英特尔终于公布了他们的下一代领先的高性能工艺节点——intel 4。该节点预计将在今年年底前量产。虽然在功能方面不如他们通常的节点那么全面,但intel 4 提供了足够的功能来支持他们的下一代客户端 SoC(代号 Meteor Lake)所需的计算块。该节点充分利用 EUV 并提供比 Intel 7 大约 20% 的性能/瓦特增益。
在 SoC 级别,该节点在等频下可降低多达 40% 的功率或在等频下提供 >20% 的频率提升-力量。此外,该节点的高性能库拥有完整的 2.04 倍密度缩放,超过intel 7 中用于 Alder Lake 的最高性能单元。在纸面上,这些 PPA 特性使公司的新intel 4 工艺的性能水平优于台积电 N3 和三星 3GAE。在密度方面,英特尔 4 与 N3 高性能库相比似乎极具竞争力。
很明显,Intel 4 是经过精心制作的。仔细的标准单元缩放以及架构简化有助于降低工艺复杂性。随着 EUV 的引入,回归到更简单的材料有助于大大减少掩模、步骤和图案的可变性和复杂性。英特尔表示,与英特尔 7 相比,新节点还大大降低了每个晶体管的成本。
尽管如此,我们认为英intel 4 是一个权宜之计节点——一个最小可行的产品,是通往intel 3 的中间节点,这预计将发生在intel 4 之后大约一年(明年年底)。Intel 3 将是 Intel 的最终 FinFET 工艺。此后的一切都将使用该公司称为 RibbonFET 的新的环栅晶体管架构。intel 3 恰好也是英特尔代工服务 (IFS) 即将推出的旗舰节点。intel 3 建立在intel 4 的基础上,这就是为什么及时正确地将intel 4 提升到良好的良率和高产量如此重要的原因。该公司已经透露,intel 3 将再提供 18% 的性能/瓦特改进,这本身就是一个全节点改进。该过程还将引入一个新的更密集的高性能库以及一组更完整的其他库和 IP。
从本文详述的 Intel 4 工艺,该公司能否重新获得其在半导体行业的领先地位,完全取决于其执行力。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
