基于DSP的音频会议信号合成算法研究
2.2 有无声能量检测
本文引用地址:http://www.eepw.com.cn/article/83866.htm在ITU-T协议中有无声检测即语音激活检测(Voice Activity Detection)。在多点音频会议中,有无声检测使得在某一时段实际语音合成的终端数目大大少于与会者数目,降低了合成运算量,减轻了处理芯片的负担。同时也是麦克风自适应增益控制AGC的基础。
在数字语音信号中,有无声检测是通过信号能量、过零率参数的组合,与预置的能量门限值进行比较得出。基于短时平均能量的计算是利用一个固定宽度的滑动窗口,每输入一个最新样本,计算该样本之前的窗口覆盖的所有样本的能量平均值,将其与一个能量门限值比较来判断该新样本是静音还是有声。
如上所述,以帧为单位对数字语音进行检测,如果某一帧内有任何一个样本是有声,则该帧就是有声。将窗口以帧为单位滑动,而不是以样本为单位,直接凭每帧的最后一个样本是有无声来确定该帧是有声帧或无声帧,这种简化的判断方式大大节省了运算量。对判断的结果而言并无影响。
使用自适应变化的能量门限可以更加准确地对有无声加以判断。可以通过样本短时能量的一阶线性低通滤波得到背景噪声能量。而自适应能量门限值则保持与短时背景噪声能量一个静音检测的灵敏度常量比值So。长时间连续讲话会升高背景噪声的估计值,这就相应地提高了静音检测能量门限,有可能造成紧接着发生的低幅值的讲话当作静音而未被检测到。所以当检测到话音时可以通过改变低通滤波器的截止频率来重新估计噪声能量。
在过滤静音的同时应当注意如何保留短时能量相对较低的微弱音频信号,如摩擦音和辅音。这些微弱信号的存在保证了语音语义的完整性,所以在短时平均能量判断之外还应该结合过零率的判别保留这些微弱音频信号。采用余音生成器的方式可以实现微弱音频信号的保留,即余音生成器将紧跟在一个语音串后的头几帧。所谓无声的帧仍然应该被当作是有声,从而避免低电平语音被抑制掉。ITU-T G.723.1A对余音生成器算法作了较详细的设计,在此不做详细描述。
2.3 归一化定标处理
多路语音信号合成时采用线性叠加,必须解决的问题是如何防止叠加产生溢出而导致失真。如果采样样本是16bit,而求和缓冲区也是16bit,那两路音频流就容易使求和区溢出。即使提供了高精度的求和缓冲区,使得在求和过程中不会溢出,但是这不能保证求和结果的幅值适合输出硬件器件的要求范围(DA器件范围通常是16bit)。
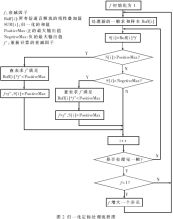
简单的方法是对超出范围的值箝位。更好的方法是对求和结果分帧进行归一化定标,具体就是:对某个求和语音帧中的所有样本分析,若样本S的值超过了器件所能表示的最大范围,那么S之后的所有样本均乘以一个衰减因子f。其中f是能够使S满足输出器件范围的最大值,显然,f的绝对值小于1。这样在箝位后的一段时间内,语音样本之间的大小是相对不变的。
在实验中选用了通用的16bit定点DSP芯片TMS320C549进行实时仿真来完成多路音频流的合成。各路线性样本相加过程中,求和的值是不会溢出的,因为样本是16bit,而累加器是32bit。但和值很容易超过输出硬件设备允许的范围(16bit)。
在归一化定标处理中,初始化时衰减因子f为1,每次开始处理一个新的样本缓冲区时,任何一个样本S超过了范围,将S箝位,并且求得S与允许范围值的比值f,在时序上位于S之后的样本都除以f。但是为了避免语音不必要的衰减,而箝位操作有让f越来越小的趋势,因此需要有让f变大的地方,这发生在每个新样本缓冲区开始处理的入口。新的缓冲区样本仍然需要衰减的可能性很大,所以f不适合每次都从1开始,而是应该在某种程度上继承过去的值。即在每个新样本缓冲区的入口处,只要f不等于1,就将其调整为比f稍大些的值,让它成为新的衰减因子。若样本的确不需要衰减,经过若干帧后f会慢慢变回1。
定点DSP中不易使用除法,所以可以把所有f的值做成一张表,f的取值范围定义为1/16、2/16,直到15/16,它的衰减精度为1/16。当S发生箝位时,用比较法或者查表法求出合适f (15个取值之一)。之所以考虑是1/16的步长,是因为它已经可以确保16个输入流求和不会溢出,如果还需要更大的精度,可以取1/32(2的n次方由定点DSP实现起来较方便)。
归纳起来,归一化定标的核心思想是:f必须很快地变成合适的衰减因子,使得样本不会溢出,然后f会慢慢地变回1。S发生箝位时f立刻被计算出,而在时间上每处理完一个求和帧后,就试图把f向1靠近,f每次增加它与1的差值的1/16。即: f′= f+(1-f)/16。具体的定标流程图如图2所示。
3 试验分析
同时输入10路的音频流到混音模块,每路的采样率都是16kHz,帧长选择10ms,即160个样本。
在对电干扰进行抵消时,对于带宽为3kHz(300~3 300Hz)的宽带随机白噪声,抵消程度优于42dB。在室外,其混响时间较小,对宽带噪声的声干扰的抵消程度优于30dB。在混响较为严重的实验室中,声干扰的抵消程度也可以优于15dB。
经过听觉试验表明,经过定标和回波抑制的合成语音流输出能够清晰分辨出每一路的声音。
使用Matlab比较对输出进行简单箝位和输出定标两种方式的语音时域波形,可以观察到前者波形中有很多因溢出导致的“削波”,而后者的波形失真较小。
数字音频流合成对于多点音频会议系统是不可缺少的。首先对输入的多路音频流进行经过有无声能量检测和回波抑制处理后将有效输入信号线性叠加,然后进行增益定标以便减少失真,以满足输出设备的要求。通过定点DSP的实现以及实验证明这种模式下的音频会议信号合成算法能取得很好的会议效果。
参考文献
1 周 霖. DSP通信工程技术应用[M]. 北京:国防工业出版社,2004:301~315
2 杨行峻.语音数字信号处理[M].北京:电子工业出版社,1995:154~157
3 ITU-T G.723.1 Annex A:Silence Compression Scheme. ITU,1996








评论