基于COFF文件分析提取器的DSP下载文件生成
在基于DSP的嵌入式系统中,软件更新通常需要借助仿真器将最新的可执行程序下载到目标板上,然后提取出可执行二进制程序并写入非易失存储器中。或者离线进行二进制文件的提取,然后再由DSP自己或主机芯片完成文件的烧结。
在此,有必要简单介绍一下TI DSP可执行程序(目标文件)的结构。TI代码产生工具CCS在经过编译、链接之后,产生的目标文件是一种模块化的文件格式——COFF格式。程序中的代码和数据在COFF文件中是以段的形式组织。
在此基础上,再来讨论上面两种方法的弊端。前者只要程序有变化,就会造成新生成目标文件各段的大小和运行地址的变化,其系统引导程序也需要作相应的改动。如果需要对大量的DSP系统进行软件更新或经常需要软件更新的情况下,这种方法的效率非常低下,缺乏灵活性。后者的通常做法是先用工具软件hex6x先将编译器生成的目标文件转换成多个TI格式的.hex文件,再逐一分析.hex文件,手工去掉其中的一些标志信息,并根据需要对文件进行必要的分割合并,最后调用TI提供的工具软件hexbin将各个.hex文件转换成二进制文件,生成文件的数目随应用而变化。这种方法因为涉及到手工操作费时费力不说且很容易出错。同样也存在着灵活性差的弊端,遇到有大量增减以及配置文件有修改的时候就会导致生成文件数目的增减,需要修改DSP或主机boot程序以适应这种改变。通过对目标文件结构的分析,可以直接提取可供下载的二进制文件。
1 目标文件结构分析
DSP的源程序——C代码或汇编代码在编译后生成的COFF文件包含多个段,默认的情况下,COFF文件包含3个段:.text:通常包含可执行代码;.data:通常包含已初始化的数据;.bss:通常为未初始化的数据保留空间。
当然汇编器和链接器允许自己建立和链接自定义的块,这些块与以上的3个段类似。所有的段分为两大类:已初始化段和未初始化段。这两类段的最大区别就在于是否出现在加载文件中。
下面来分析COFF文件的结构,COFF文件从上到下中依次是文件头、可选的文件头、段头信息表、段头信息表对应的段数据、重定位信息、行号入口表、符号表、字符串表,如图1所示。其中第3~6项包含多个数据区,前4项与加载文件密切相关。
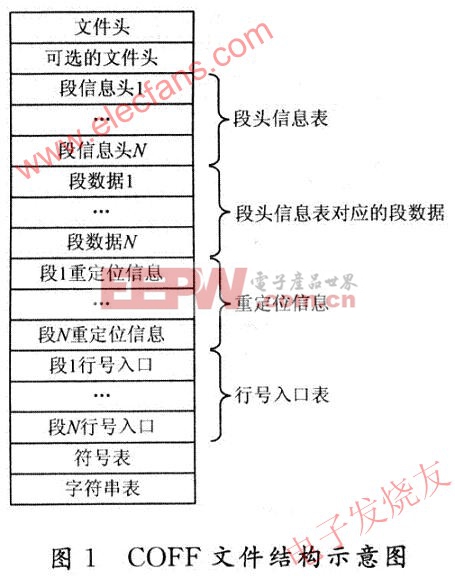
由于前4项与加载文件相关,下面对这4项逐一分析一下:
(1)文件头:顾名思义,就是COFF文件的头,用来保存COFF文件的基本信息,如段数目、时间戳、符号表位置等。从文件的0偏移处开始,用C的结构描述如下:

文件头中的标记包含了诸如大小端模式、COFF是否为可执行文件等信息,具体解释见参考文献。
(2)可选头:可选头接在文件头的后面,也就是从COFF文件的Ox0014偏移处开始。长度可以为O。不同平台的可选头,长度和结构都不相同,TI DSP采用的可选头长度为28 B,用C的结构描述如下:


(3)段头:段头紧跟在可选文件头的后面(如果可选文件头的长度为0,它紧跟在文件头后),一般COFF包含多个段头,数目就是文件头中的usSection—Counter。它的长度为48 B,用C的结构描述如下:

段头可以说是最重要的头,文件分析提取器的核心就是用它来描述它的。一个COFF文件可以不要其它的节,但文件头和段头这两节是必不可少的。有必要详述一下它的成员:
cName用来保存段名,常用的段名有.text,.da—ta,.bss等。对于用户自定义长度超过8 B的段名,则为指向符号表的指针。
uiVirtAddr是段数据载入或连接时的虚拟地址。对于可执行文件,这个地址是相对于它的地址空间而言。当可执行文件被载入内存时,这个地址就是段中数据的第一个字节的位置。大多数情况下与uiPhyAddr相同。
uiSecSize是段中数据的实际长度,在读取段数据时就由它来确定要读多少字节。
uiSecPointer是段数据在COFF文件中的偏移量,以绝对地址标识。
uiRelPointer是该段重定位信息的绝对地址,它指向了重定位表的1个记录。
uiLNOffset是该段行号表的绝对地址,它指向的是行号表中的1个记录。
uiRelSize是重定位信息的记录数,从uiRelPointer指向的记录开始,到第ulNumRel个记录为止,都是该段的重定位信息。
uiLNSize和uiRelSize相似,不过它是行号信息的记录数。
uiFlags是该段的属性标识,与下载相关的标识如表1所示。

其余定义请见参考文献。
(4)段数据:保存各个段的数据,在目标文件中这些数据都以原始数据(Raw Data)形式存在,只有需要下载的数据段才存在该区域。
2 COFF文件分析提取器的工作流程
首先读入目标文件,该文件扩展名为out,以二进制形式读入。分析.out文件的文件头以确定有多少个段,然后逐段分析段信息头,根据段属性标识以确定是否需要下载,段头中的绝对地址、段数据长度等信息作为升级文件的一部分。与需下载的段数据合并成最终的下载文件,为了适应自动化升级的需要,下载文件头部还保留了COFF文件的时戳。值得注意的是因为TMS320C6000 DSP为32位处理器,需要对段落头中段数据长度信息进行32位整型对齐,在此采用Ceil对齐——不足的字节以O补齐。具体流程如图2所示。
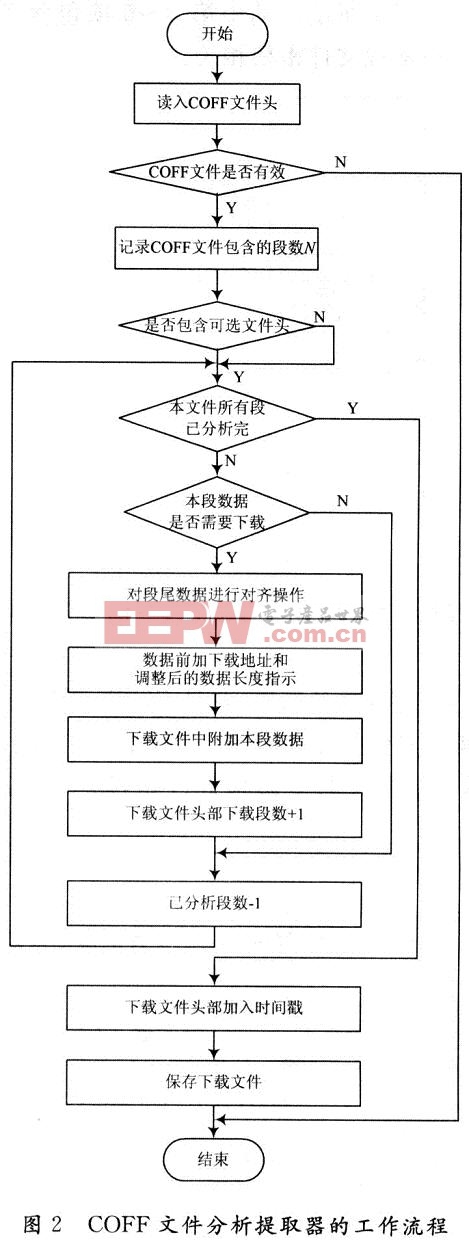
而COFF文件中的重定位信息、行号入口表、符号表、字符串表等数据区,对于下载文件的制作没有直接联系,可以不做分析。当然,如果在PC上制作可视化工具的话,另当别论,限于篇幅在此不做讨论。
3 COFF文件分析提取器的应用
开发的DSP应用系统一般采用HOST—SLAVE模式,即DSP是作为系统的信号处理协处理单元,HOST保存有所有处理器的下载文件。COFF文件分析提取器在做离线使用时,提取出的下载文件由H0ST负责保存、上电加载。HOST的引导程序在上电时读取已经构建好的二进制文件,根据段数目、每段大小以及目标数据的下载地址等相关信息即可完成对目标代码的自动下载。COFF文件分析提取器在线使用时,时间戳就作为版本是否更新的依据,HOST一旦侦测到版本服务器有新版本的COFF文件并得到用户升级确认后,就可启动文件提取器。
目前,这种利用COFF文件分析提取器生成DSP下载文件的方式,已经在中兴通讯多个产品线广泛应用,大大提高了产品的可测试性和易维护性。
4 结 语
在此讨论的方法基于对COFF文件结构的分析,读取DSP编译器生成的.out文件,根据文件本身携带的信息,直接提取生成可供下载的二进制文件。最终生成的二进制文件中包含有与.out文件相同的信息,在下载时利用这些信息即可完成对DSP芯片的加载。













评论