实时融合计费系统的设计与实现
对一次性费用计算、使用费计算、周期费用计算和优惠计算等提供统一的属性访问接口,使得费用计算和数据源的变化无关,实现通用的费用计算引擎。当增加新的业务(新的格式、内容)时,只要增加实现一个适配器就可以被批价引擎接受。传统的资费模型通常通过用户资料中的多个属性,组合运算后得到若干条资费规则,资费规则只有在程序运行时才知道用户适用的资费。资费配置后是否正确生效具有不确定性。基于适配器模式的批价引擎采用了资费规则包的资费模型,形成可供用户选择的资费计划,这样用户所匹配的资费规则可以从用户资料中直接查询出来,可靠性更能得到保证。通过对各种话单、事件进行分析,资费配置和对抽象的“事件属性”进行定义,对新的网络(业务)计费只要在基础数据配置表中增加相应的事件属性描述即可。
为了解决基于C/C++语言实现的批价引擎可扩展性差的问题,批价引擎还创新性的采用了嵌入Python脚本技术,利用C++程序运行时的动态解析Python脚本和Python本身强大的表达能力,可以使计费规则的表达无限灵活。Python语言是面向对象的脚本语言,同时也支持传统的结构化编程,具有很好的动态解释性。复杂的资费策略可以通过脚本实现。脚本就像插件一样,可以根据需要任意配置,极大地提高系统的表达能力和扩展性。为运营商提供强大的运营支撑能力,方便运营商的业务快速推出和开展。
2.3 虚拟余额技术
传统的计费系统没有虚拟余额的概念,只支持一种余额类型,即金额。其他类型的消费都要转换为金额才能实现。随着电信业务的发展,各种各样的基于时长、次数、流量等消费的方式越来越多,都转成金额也是一种方式,但不灵活。在余额管理模块设计中,系统引入了虚拟余额的概念。系统支持用户的余额可以是除了金额外的其他类型“余额”,如时长、次数、流量等。同时支持虚拟类型的扩充,有效增加用户消费的方式,方便电信业务的拓展。
3 共享内存数据库
计费系统中各种业务程序需要对数据库中的数据进行频繁的查询操作,涉及的数据量非常巨大,访问数据库的频率很高,由此产生过多的数据库交互导致程序性能降低。使用共享内存技术将数据库待查询的数据上载到业务程序所在的系统内存中,结合业务需求建立快速有效的查询方式,提高查询速度,减少对数据库性能的依赖。
根据需要查询的数据量,在系统内存中开辟足够的共享内存段,用于存放数据记录。同时根据数据查询的需求建立对应的查询方式(即建立索引),创建对应的共享内存段,用于存放索引及辅助维护数据。共享内存数据库框架如图4所示。
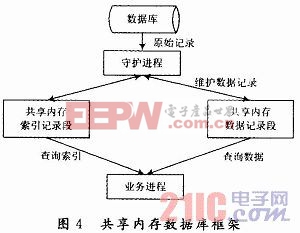
守护进程根据预先定义,查询并获取数据库中的原始数据,经过处理形成需要存放的记录并插入共享内存的数据段,同时根据查询方式形成对应的索引记录,插入共享内存的索引段。在数据被批量上载后,业务进程可以连接共享内存,先访问索引段,然后获取对应的数据记
录。数据库数据发生变动时,守护进程根据相应的机制获取变动的数据,依照前面业务进程查询数据的方法,如果找到指定数据就更新,如果没找到就插入新记录。
4 结语
随着电信技术的不断发展,传统的准实时计费系统已不能满足电信运营商的需求。本文设计了一种实时融合认证在线计费系统,该系统采用可定制规则分拣的预处理引擎、基于适配器模式的批价引擎和嵌入式脚本等技术满足了灵活的多种业务融合计费需求。同时,该系统还采用了多级消息分发、共享内存数据库等技术,保证了系统的实时性。该系统消息平均响应时间99.9%小于400 ms。系统单节点支持用户数由现在的300万提升到2 000万,系统容量提升后,一般的电信企业部署单节点,最多两个节点即可满足容量要求。系统的单节点混合呼叫处理能力由现在的2 400 CaPs提升到4 000 Caps。数据处理性能提升后,将能满足未来海量数据处理的需要。


评论