音频编码和解码原理
数字音频信号首先进入数字滤波器组,它被分成等带宽的32个子频带,可由数字滤波器输出32个子带数据信号。这种处理方法与图像编码信号进行DCT变换的作用相似,但不是像图像信号那样分为64种余弦频率信息,这里仅分成32个子带,即将音频数据流改为32种频率的组合。声音的分解力低于图像,这种处理方法是可行的。然后,对32个子带的伴音数据进行再量化,以便再压缩数据量。对于各个子频带的量化步长不相同,量化步长是根据人耳的听觉阈值和掩蔽效应而确定的。经过量化处理的已压缩数据,保留了伴音信息的主体部分,而舍弃了听觉效果影响较小的伴音信息。
进入编码系统的输入信号,分流部分信号送到并列的1024点快速傅利叶变换器(FFT)进行变换,它检测输入信号每一个瞬间取样点在主频谱分量频域的分布的强度,经变换的信号送到心理声学模型控制单元。根据听觉心理声学测量统计结果,可以归纳出一个心理声学控制对照表格,并按照此表格制成控制单元,而单元电路可以集中地反映出人耳的阈值特性和掩蔽特性。
经过量化的32个子频带数据已经被压缩,还要加上比例因子、位分配信息等辅助信息,共同加到1位流格式化单元,编码成为两个层次的伴音编码信号。它既含有32个子频带的伴音数码,又带有这些数码所对应的位分配数据和不同频带数据的强弱比例因子。待将来数据解码时,可根据各子频带的数据恢复声音信号,以及压缩时码位分配和强弱比例情况,在进行反量化时,参照压缩时的程序进行还原。
可见,伴音的压缩编码和图像处理一样,也要经过变换、量化、码位压缩等处理过程,它运用了许多数学模型和心理听觉测量的统计数据,对32个子频带和各个层次信号的处理也各有不相同的取样速率。实际的心理听觉模型和适时处理控制过程十分复杂。这些算法细节都已按硬件方式被固化在解码芯片中,这些内容不能再改变。
3、伴音与图像的同步
图像和声音信号的压缩方法有许多不同,图像数据量又远远大于声音数据量,两者传送的数据码率大不相同。每传送14~15个视频数据包才传送1个音频数据包,而播放声音和图像的内容又必须作到良好同步,否则将无法保证视听统一的效果。
为了作到声图同步,MPEG-1采用了独立的系统时钟(简称为STC)作为编码的参照基准,并将图像和声音的数据分为许多播放单元。例如,将图像分为若干帧,将声音分为若干段落。在数据编码时,在每个播放单元前面加置一个展示时标(PTS),或者加置一个解码时标(DTS)。当这些时标出现时,表示前一个播放单元已经结束,一个新的图像和声音播放单元立即开始。在播放相互对应的同一图像单元和声音单元时,可实现互相同步。
为了使整个系统在时钟在编码和重放时,声图有共同的时钟基准,又引入系统参考时钟SCR的概念。系统参考时钟是一个实时时钟,其数值代表声图的实际播放时间,用它作为参照基准,以保证声图信号的传输时间保持一致。实时时钟SCR必须与生活中的真实时间一致,要求它的准确度很高,否则可能发生声音和图像都播快或播慢的现象。为了使SCR时间基准稳定、准确,MPEG-1采用了系统时钟频率SCF,以它作为定时信息的参照基础。SCF系统时钟的频率是90KHz,频率误差为90KHz±4.5KHz。声图信号以SCF为统一的基准,其它定时信号SCR、PTS、DTS也是以它为基础。
三、其它MPEG标准的音频编码器
1、MPEG-2音频编码方框图
MPEG-1是处理双声道立体声信号,而MPEG-2是处理5声道(或7声道)环绕立体声信号,它的重放效果更加逼真。
图2.3.3是MPEG-2音频编码方框图。它输入互相独立的5声道音频信号,有前置左、右主声道(L、R),前置中央声道(C),还有后置左、右环绕声道(LS、RS)。各声源经过模-数转化后,首先进入子带滤波器,每一声道都要分割为32个子频带,各子带的带宽均为750Hz。为了兼容MPEG-1、普通双声道立体声和环绕模拟立体声等编码方式,原来按MPEG-1编码的立体声道能够扩展为多声道,应当包括所有5声道的信息,为此设置了矩阵变换电路。该电路可生成兼容的传统立体声信号LO、RO,还有经过“加重”的左、中、右、左环绕、右环绕声音信号(共5路)。对5路环绕立体声信号进行“加重”处理的原因:当计算兼容的立体声信号(LO、RO)时,为了防止过载,已在编码前对所有信号进行了衰减,经加重处理可以去失真;另外,矩阵转变中也包含了衰减因子和类似相移的处理。
编码器原始信号是5路,输入通道是5个,经过矩阵转化处理后产生了7种声音信号。应当设置通道选择电路,它能够根据需要,对7路信号进行合理的选择处理。该处理过程决定于解矩阵的过程,以及传输通道的分配信息;合理的通道选择,有利于减弱人为噪声加工而引起的噪声干扰。此外,还设置了多声道预测计算电路,用于减少各通道间冗余度。在进行多声道预测时,在传输通道内的兼容信号LO、RO,可由MPEG-1数据计算出来。根据人耳生理声学基
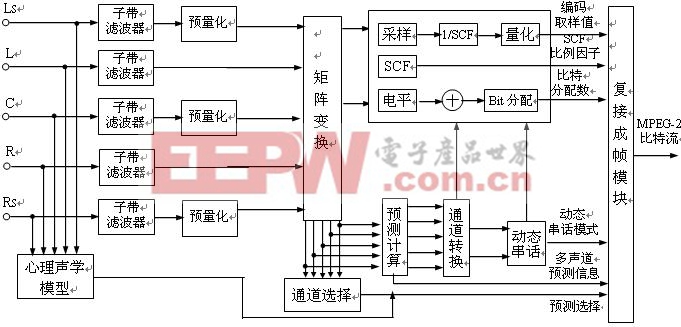
础,后级设置了动态串话电路,可在给定比特的情况下提高声音质量,或在要求声音质量的前提下降低比特率。但设置该电路增加了MPEG-2解码器的复杂程度。
经过编码器产生了多种信息,主要有编码取样值,比例因子,比特分配数据,动态串话模式,多声道预测信息,通道预测选择信号等,诸信息传递给复接成帧模块电路,最后以MPEG-2比特流形式输出压缩编码信号。
MPEG-2解码器基本上是编码器的逆过程,其电路结构简单一些,运算量小一些。解码器的解码转换矩阵可输出5路信号,再经过32分频子带滤波器处理,可输出LS、L、C、R、RS信号;另外,经过量化、SCF和子带滤波器处理后,还可以取得前置立体声LO、RO,共计可输出7路音频信号。







评论