FPGA软核之战点燃创新激情
2007年秋Xilinx又在对其MicroBlaze嵌入式处理器内核进行了升级,增添一个内存管理单元(MMU)选项,为32bit的处理器提供高级的、支持虚拟内存的操作系统。开发者还可以只用个更为简单的内存保护单元(MPU)或完全放弃受监管的内存管理。
本文引用地址:http://www.eepw.com.cn/article/81317.htm目前已发布的第一款面向新的MicroBlaze v7的全功能操作系统是Lynuxworks公司的BlueCat Linux。到目前为止,MicroBlaze处理器仅限于支持更简单的嵌入式操作系统,这些系统无法支持虚拟内存或者内存保护。具备了MMU或者MPU选项后,MicroBlaze v7适合于范围更广、需要更高的安全性和可靠性的嵌入式应用。
MicroBlaze v7还有另一项改进措施,新的指令可以提供更快的浮点性能,而且能提高其与协处理器和定制逻辑电路之间的I/O性能。此外,Xilinx已经将CoreConnect接口升级,使之满足最新的CoreConnect 处理器本地总线(PLB)v4.6规范,保证处理器与片上外设之间具有更快的连接速度。
强固的内存管理功能
自从2001年引入软处理器MicroBlaze以来,Xilinx就一直对其进行不断的改进。两年前,Xilinx开始提供一种FPU选项。2006年,Xilinx延长了其指令的流水线,从而容许采用更高的时钟速度。2007年较早时候,Xlinx发布了MicroBlaze v6,增添了少量其他的增强措施。现在,Xilinx借助MicroBlaze v7推出了第一流的内存管理功能,这显著扩展了MicroBlaze所适合的嵌入式应用的范围。
当然,许多嵌入式系统并不需要如此高水平的内存管理,因此MicroBlaze MMU是一种选项功能。另一种可供选择的方法是实施MPU,它可以在无虚拟内存和地址翻译的情况下对内存进行保护。MPU适用于那些必须保护程序存储区不受其他程序意外或者恶意入侵的嵌入式系统。还有另外一种选项,即在无内存保护或者虚拟内存的条件下实施特权模式的执行。在特权模式下,只有操作系统或者有优先特权的应用程序可以执行那些有关系统安全性的指令。
表1 示出每一种选项(MMU、MPU或特权优先执行)是如何影响综合后的处理器规模的,其衡量尺度是,在FPGA的可编程逻辑架构中实现这些功能而必须增加的查阅表(LUT)数量。在单独实现特权模式时,所需的LUT很少,其他的选项就需要事先进行更为周详的考虑。特别是,MMU大约需要1 000个LUT,大约占一个功能配置齐全的MicroBlaze v7内核的1/3。
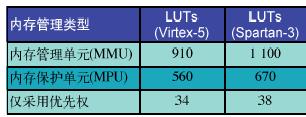
表1 3种MicroBlaze v7内存管理选项的规模
完备的MMU成为最大的内存管理选项的部分原因是,它需要转换监视缓冲器(TLB)来完成虚拟-物理内存地址转换的查阅表的一部分内容。
MicroBlaze v7拥有一个64条目的一体化TLB。为了补充这一软件管理的缓冲器,还提供了用于指令内存页面和数据内存页面的影子条目。这些影子条目的数量是可以由用户定义的:缓冲指令的条目数量可以为1、2、4或8个,而缓冲数据的条目数与之相同。处理器可以自动地管理这些影子条目,从而防止系统失效(thrashing)的出现。内存页面的尺寸范围是1kB~16MB,而且可以混合使用各种页面尺寸。采用有效位数为32bit的寻址方式后,MicroBlaze v7可以对多达4GB内存进行寻址。
MicroBlaze MMU是仿照某款IBM Power 405处理器中的MMU设计的。因为此前有些Virtex系列FPGA集成了一个加固的Power 405内核,其速度要远快于一个综合到该架构中的MicroBlaze 处理器。采用类似的MMU将能够给MicroBlaze v7带来几个好处。首先,编程者将基于虚拟内存的操作系统从Power架构移植到MicroBlaze架构的过程将更为轻松。第二,开发者可以更为轻松地将一个或多个MicroBlaze内核与一个Power 405搭配起来,以共享内存的配置方式构成一个多核设计。第三,未来Xilinx可能通过与IBM合作而向其FPGA中集成更新的Power内核。
更快的CoreConnect总线
CoreConnect是IBM用于SoC的片上总线,它在1999年开发成功。虽然IBM创造CoreConnect的主要意图是为自己的Power架构处理器服务,但任何人都可以免费地获得将CoreConnect作为一种可综合的知识产权(IP)模块使用的许可,它并不局限于某种特定的CPU架构。在过去8年中,软IP厂商已经各自开发出许多与CoreConnect兼容的、可发放许可证的外设内核。唯一一种得到更为广泛支持的片上总线架构是ARM的AMBA。
为了保证更高的效率,CoreConnect将低速和高速的外设分别设置在分开的总线上,两条总线由桥连接起来。截止到目前,MicroBlaze只支持较慢的片上外设总线(OPB),该总线的数据通道宽度为32bit。MicroBlaze v7仍然保持了与OPB之间的后向兼容性,但增加了对速度更快的处理器本地总线(PLB)的支持。在面向32、64或者128bit宽度的综合时,PLB的数据通道是可配置的。总线的带宽取决于这些数据通道的宽度和FPGA的时钟频率,速度最快的Virtex-5器件的时钟频率已经达到了550MHz。在550MHz的频率上,一个128bit的PLB的最大的理论带宽为8.8MB/s。
PLB直接与CPU相连,提供了一条为若干片上外设所共享的多点总线。它是一个Xilinx专有的、被称为快速单工链路(FSL)的接口。FSL是直接的点-点接口,而并非多点总线。FSL的速度要比共享总线的快,但是每个I/O接口需要更多的逻辑门电路。一个SoC设计可以使用一条或多条FSL与一条CoreConnect PLB的组合来满足不同的目标需求,从而给开发者提供了丰富的设计选项。
图1示出了在Xilinx FPGA上实现的一个SoC实例,其中采用了一个MicroBlaze或者Power 405处理器内核。在这个TCP/IP包处理器实例中,最关键的数据通道将Ethernet控制器与外部存储控制器和CPU连接起来。这些数据通道是FSL,宽度可以是32~128bit。重要性较低的部件则分享一个CoreConnect PLB。Xilinx开发工具可以自动对FSL进行配置,使之服务于某个特定的目的,或者让开发者能够对接口进行人工配置。
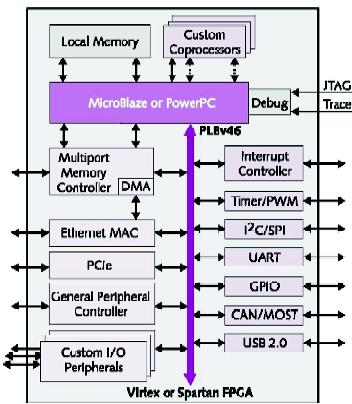
经过IBM的许可,Xilinx对标准的CoreConnect IP进行了轻微的改进。但这些改进是必不可少的,因为FPGA的可编程逻辑门的效率并没有ASIC的标准的单元门那么高,特别是路由信号要横跨一块大芯片时。在FPGA中,数据通道和时钟树所延伸的长度要远远高于ASIC的情况,这使得时序的收敛变得更为困难。对于那些分布在芯片各处的、数不清的外设连接到一条共享总线上的复杂设计而言,该问题变得更为严重。于是,Xilinx对PLB进行了改进,提高了它的同步能力,并消除了不确定的数据猝发现象。Xilinx宣称,这些改进虽然相对而言幅度并不大,却可以让开发者能够在CoreConnect PLB上连接10~20个外设,而不至于出现时序问题。
此外,Xilinx已经改进了PLB,使之能以更高的效率与集成在某些Virtex-5 FPGA中的、加固的收发机交互。这些收发机是一个PCI Express端点和一个3模Ethernet媒体访问控制器(TEMAC),它们可以提供的性能将远远优于那些功能相同、综合到架构中的软IP控制器的性能。上述的PCI Express端点得到了充分的缓冲,并且支持1、2、4或8条通道。TEMAC收发机则支持10Mb/s、100Mb/s和Gigabit Ethernet数据率。在Xilinx的基准测试中,一个基于MicroBlaze v7和TEMAC的包处理器实现了750Mb/s的原始吞吐率,对收发机的理论最大带宽的利用率达到了惊人的75%。
虽然AMBA得到的支持要比CoreConnect所得到的支持广泛,后一种标准对于MicroBlaze来说却更为适合。内置到某些Virtex系列FPGA内部的Power 405处理器则采用了CoreConnect,因此,开发者能够更为轻松地基于Power 405和MicroBlaze内核创制出非对称的多处理器。许多来自于第三方厂商的外设IP内核,往往通过添加一个简单的衬垫适配头就可以与AMBA或者CoreConnect一起工作。
新指令提升性能
Xilinx在MicroBlaze v7中添加了11种新的指令:3种用于浮点运算,其余8种则用于FSL的操作。这些新的浮点指令是简明易用的。其中的一个指令FSQRT,可在27或者29个时钟周期计算出一个32bit浮点值的平方根,具体的时间占用取决于MicroBlaze处理器配置了3级或者5级流水线。如果不采用FSQRT,则同样的运算应通过对软件库的函数调用来实现,耗时约为500个周期。
其他两种新的浮点指令可以把整数转换为浮点数或者执行相反的运算。FLT指令可以在4~6个时钟周期中把一个32bit的整数转换为32bit的浮点数,具体则取决于流水线的深度。要在软件中调用相同的函数将需要330个时钟周期。相反地,FINT指令则可以在5或者7个时钟周期中将一个32bit的浮点数变换为32bit整数,具体的时间长度取决于流水线深度。而软件调用将耗用88个周期的时间。
当协处理器通过FSL连接到MicroBlaze内核上时,另有8种新的指令可以改善I/O特性。这些指令采取了PUT和GET操作的形式,它们可以让程序以闭锁(blocking)或者非闭锁运算的形式管理协处理器的I/O。在分块关系中,CPU停止处理其他的操作,直到将协处理器的请求处理完为止。在非闭锁关系中,CPU继续处理其他操作,而协处理器的请求被送入一个FIFO缓冲器中。在缓冲器未被充满前,CPU不会被闭锁。开发者可以根据协处理器的需要来定义缓冲器的尺寸。
此外,MicroBlaze v7的FSL接口的数量是从前的两倍(16比8),而程序在运行过程中可以动态地将协处理器分配给各FSL接口。先前,协处理器在FSL间的分配是通过硬代码形式嵌入用户的软件中的。进行任何改动进行任何改动时,开发者都必须对软件进行重新编译。动态分配使得开发者编写出的软件能适应不断变化的条件和工作负载。多媒体加速库可以在专门完成快速傅里叶变换(FFT)或者有限脉冲响应(FIR)滤波器运算的协处理器上运行。
表2示出了将一个包处理器设计从MicroBlaze v6移植到v7后的结果—吞吐率改善了3倍以上,从约70Mb/s提升到250Mb/s 。不过,要注意这一对比并未将设计中的每个变量的变化所带来的影响隔离开。特别是,升级的设计版本中Ethernet控制器的速度要快得多。无论如何,这一对比展示了可以实现的性能水平。提升一个系统的最大理论带宽,并不一定能确保获得更高的吞吐率,而MicroBlaze v7的一个功能特色是为TEMAC提供更好的CoreConnect支持,而该功能是以硬连线方式融入Virtex-5 LXT芯片中。
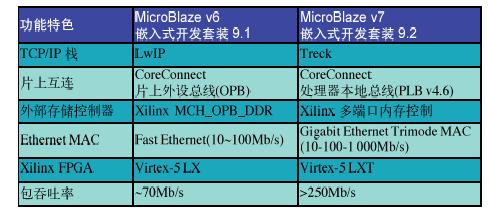
表2 MicroBlaze v6和v7的性能对比
竞争对手ARM
从2006年起MicroBlaze v7是Xilinx今年推出的处理器的第三个新版本。改进步伐的加快可能是由于一个全新的竞争者的到来:ARM的Cortex-M1。
Cortex-M1是第一种批准用于在FPGA中的ARM处理器内核,而且它针对FPGA的可编程逻辑架构进行了优化。较早时,ARM允许获得授权者在FPGA上对其设计进行测试,但不能在芯片中采用最终的设计。推动ARM对其经营路线进行变革的部分原因是ASIC的设计和制造成本的不断上升,而另一部分原因是Xilinx MicroBlaze和Altera Nios II内核的流行。Xilinx和Altera在其处理器方面已经售出了几万个使用许可。
第一家宣布支持Cortex-M1的厂商是规模远远小于Altera或者Xilinx的Actel。Actel与ARM达成了特别的协议,让客户在采购Cortex-M1 FPGA时,无需再购买一个ARM许可证或者向ARM交付使用费。这一交易大大地降低了应用一个基于ARM的设计成本。Xilinx尚未发布一个类似的协议,但是笔者估计在未来很可能会宣布达成协议。虽然Cortex-M1和MicroBlaze处理器看上去将ARM和Xilinx变为两个相互竞争的对手,但它们的关系中的合作性仍然超过竞争性。ARM认为MicroBlaze主要是一种用于吸引客户的特价商品,Xilinx研制它主要是为了能卖出更多的FPGA。一个MicroBlaze v7的许可证售价仅为495美元,因此芯片,而不是许可证才是真正带来赢利的产品。Xilinx同样欣喜地看到客户购买其FPGA后与Cortex-M1一起使用。
即使是这样,虽然ARM和Xilinx的握手可谓真诚,但MicroBlaze v7还是给了Cortex-M1当头一击。与Xilinx用来吸引顾客的特价品一比高下,这一全新的ARM处理器可就吃了亏。虽然MicroBlaze v7定价低廉,但令人难堪的是,它却拥有大量Cortex-M1所不具备的功能,例如一个可任选的FPU、MMU/MPU、32bit 驱动器和指令/数据高速缓存。除此之外,MicroBlaze所能实现的时钟频率也要高于Cortex-M1的。ARM的最大一个卖点是Cortex-M1来自ARM。ARM架构本身几乎都已成为业界标准,而且它得到了数以吨计的各种外设IP、开发工具和软件的支持。
正如表3所示的那样,Altera的Nios II与MicroBlaze更为匹配,虽然它从2004年后没有得到较大幅度的升级。MMU/MPU选项是MicroBlaze v7超越Nios II的第一个巨大优势巨大优势。不过,Altera也拥有一项优势:可以由用户配置的指令集架构。Nios II开发者可以开发定制化的指令集来加速特定的应用,这将极大地提升性能。为了达到类似的效果,MicroBlaze开发者可以在可编程逻辑架构中实现协处理器。
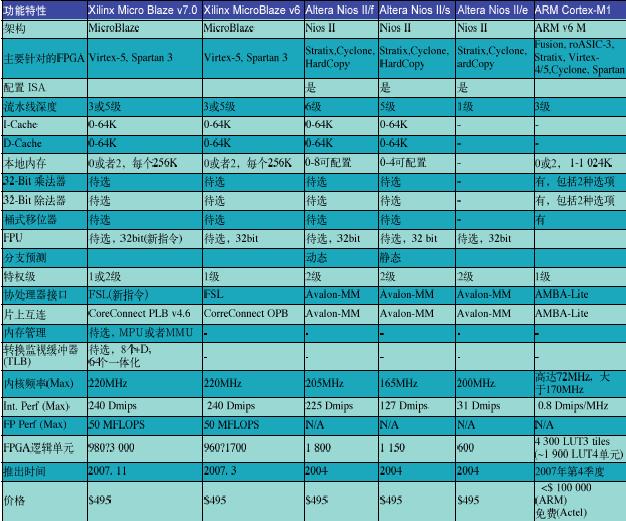
请注意这些处理器之间存在的价格差异正在缩小。在Cortex-M1出现以前,由FPGA厂商发放的处理器内核使用许可与由ARM发放的处理器内核使用许可相比,其价格差异达到了4个数量级:一个MicroBlaze或者Nios II约为500美元,而一个ARM核则要价高达几百万美元。在Cortex-M1推出后,ARM已经一改过去长期以来不透露其许可收费情况的做法。虽然一个Cortex-M1许可的确切价格仍未公布,但ARM宣称它将愿意做不到十万美元的生意,这在价格方面是一个巨大的突破。而且,正如上面曾经提到的那样,Actel可以出售预先被配置了Cortex-M1内核的FPGA,而用户无需获得一个来自于ARM的许可。由于Altera和Xilinx事实上在赠送各自可以直接用于FPGA上的处理器内核产品,ARM不得不修正自己的许可证模式,以便让Cortex-M1更具竞争力。
针对FPGA的CPU的未来发展前景
随着FPGA报价出现下滑,而ASIC的成本在不断上升,以可编程逻辑来实现一片SoC的方法也变得越来越有吸引力。正如笔者曾经指出过的那样,FPGA实现方法在经济性上超过ASIC实现方法时,所对应的制造批量点将向着有利于FPGA的方面倾斜,我们尚未发现今后哪些因素会改变这一发展趋势。正因为如此,MicroBlaze(和Nios II)的未来似乎一片光明。
不过,可能发生变动的一个因素,是开发者在采取FPGA实现方法时所选用的CPU架构。就目前而言,MicroBlaze和Nios II是到目前为止应用最为欢迎,因为它们得到了各自的FPGA厂商的大力推销,而且实际上是免费提供的。
如果其他CPU架构也可以为FPGA所用而且价格可以接受的话,则届时FPGA厂商自己的架构的魅力必然会减退。虽然Altera和Xilinx已经售出的CPU许可证数量大大超出了ARM计划售出的数量,那些认真考虑要大批量制造基于FPGA的SoC的公司,可能更愿意使用一种得到广泛支持的架构,如MicroBlaze和Nios II。
即使出现这种情况,Altera和Xilinx处理器也将达到其目标。它们卖出了更多的FPGA,它们播下了基于FPGA的SoC市场的种子,而且它们正在定义出专门用于FPGA的处理器应该具有的功能特性和优化。无论MicroBlaze和Nios II是否长寿而且兴旺发达,对于各自的厂商而言,它们都是明智的投资。(本文改编自《微处理器报告》,主标题为编者添加)

fpga相关文章:fpga是什么











评论