数字音频技术与杜比AC-3
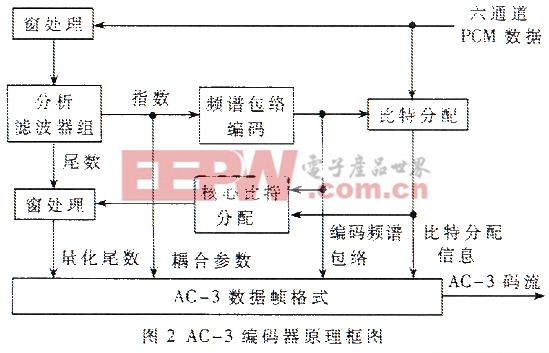 图2为AC-3编码器原理框图。AC-3输入PC声音数据,输出压缩后的数码流。编码的第一步是,运用TDAC(Time Domain Aliasing Cancellation)滤波器把时域内的PC取样数据变换成频域内成块的一系列变换系数,每个变换系数以二进制指数形式表示,即由一个指数和一个尾数构成。指数部分经编码后构成了整个信号大致的频谱,又被称为频谱包络。用频谱包括和遮蔽由线的相关性决定每个尾数的比特分配。由于比特分配中采用了前/后向混合自适应比特分配以及公共比特池等技术,因而可使有限的码率在各声道之间、不同的频率分量之间获得合理的分配;在对尾数的量化过程中,可对尾数进行抖晃处理,抖晃所使用的伪随机数生器的可在不同的平台上获得相同的结果。最后由六个块的频谱包络、粗量化的尾数及相应的参数组成AC-3数据帧格式,连续的帧汇成数码流输出。 由时域变换到频域的块长度的选择是指数变换编码的基础。在AC-3中定义了两种长度切换,一种是512个样值点的长块,一种是256个样值点的短块。在信号频谱分析时,对要处理的声道信号块区截取得越长越好,这样可以得到较好的频率分辨力,同时也能得到较高的编码效率。但是较长的数据块可能包含了一些不同一些可能被识别的噪音,如pre-echo。也就是说人耳因时间和频率上存在的遮蔽效应在进行指数变换编码时是有矛质的,不能同时兼顾,必须统筹处理。对于稳态信号,其频率随时间变换缓慢,为提高编码效率,要求滤波器组有好的频率分辨力,即要求一个长区块;而对于快速变化的信号,则要求好的时间分辨力,即要求一个短区块。在编码器中,输入信号在经过3Hz高通滤波器去除直流成分后,再经过一个8kHz的高通滤波器取出高频成分,用其能量与预先设定的阈值相比较,以检测信号的瞬变情况。 AC-3采用基于改良离散余弦变换(MDCT)的自适应变换编码(ATC)算法。虽然在AC-3标准中定义了MDCT变换,但是实际采用一个N/4点的IFFT(快速傅立叶变换),再加上两个简单的Pre-IFFT和Post-IFFT作为调整,以实现一个N点的IMDCT变换。ATC算法的一个重要考虑是基于听觉遮蔽效应的临界频带理论,即在临界频带内一个声音对另一个声音信号的遮蔽效应最明显。因此,划分频带的滤波器组要有足够迅速的频率响应,以此保证临界频带外的噪声衰减足够大,使时域和频率内的噪声限定在遮蔽阈值以下。 在AC-3编码器的比特分配技术中,采用了应用广泛的前向和后向自适应比特分配法则。前向自适应方法是编码器计算比特分配,并把比特分配信息明确地编入数据比特流中,其特点是在前端编码过程中使用听觉模型,因此修改模型对接收侧解码过程没有影响;其缺点是降低编码效率,因为要传送比特分配信息而占用了一部分有效比特。后向自适应方法没有得到编码器明确的比特分配信息,而是从数码流中产生比特分配信息,优点是不占用有效比特,因此有更高的传输效率。其缺点是要从接收的数据中计算比特分配,如果计算太复杂会使解码器的成本升高。此外,解码器的算法也会随着编码器听觉模型的改变而改变。AC-3采用混合前向/后向自适应比特分配,在提高码率和降低成本间取得了平衡。
图2为AC-3编码器原理框图。AC-3输入PC声音数据,输出压缩后的数码流。编码的第一步是,运用TDAC(Time Domain Aliasing Cancellation)滤波器把时域内的PC取样数据变换成频域内成块的一系列变换系数,每个变换系数以二进制指数形式表示,即由一个指数和一个尾数构成。指数部分经编码后构成了整个信号大致的频谱,又被称为频谱包络。用频谱包括和遮蔽由线的相关性决定每个尾数的比特分配。由于比特分配中采用了前/后向混合自适应比特分配以及公共比特池等技术,因而可使有限的码率在各声道之间、不同的频率分量之间获得合理的分配;在对尾数的量化过程中,可对尾数进行抖晃处理,抖晃所使用的伪随机数生器的可在不同的平台上获得相同的结果。最后由六个块的频谱包络、粗量化的尾数及相应的参数组成AC-3数据帧格式,连续的帧汇成数码流输出。 由时域变换到频域的块长度的选择是指数变换编码的基础。在AC-3中定义了两种长度切换,一种是512个样值点的长块,一种是256个样值点的短块。在信号频谱分析时,对要处理的声道信号块区截取得越长越好,这样可以得到较好的频率分辨力,同时也能得到较高的编码效率。但是较长的数据块可能包含了一些不同一些可能被识别的噪音,如pre-echo。也就是说人耳因时间和频率上存在的遮蔽效应在进行指数变换编码时是有矛质的,不能同时兼顾,必须统筹处理。对于稳态信号,其频率随时间变换缓慢,为提高编码效率,要求滤波器组有好的频率分辨力,即要求一个长区块;而对于快速变化的信号,则要求好的时间分辨力,即要求一个短区块。在编码器中,输入信号在经过3Hz高通滤波器去除直流成分后,再经过一个8kHz的高通滤波器取出高频成分,用其能量与预先设定的阈值相比较,以检测信号的瞬变情况。 AC-3采用基于改良离散余弦变换(MDCT)的自适应变换编码(ATC)算法。虽然在AC-3标准中定义了MDCT变换,但是实际采用一个N/4点的IFFT(快速傅立叶变换),再加上两个简单的Pre-IFFT和Post-IFFT作为调整,以实现一个N点的IMDCT变换。ATC算法的一个重要考虑是基于听觉遮蔽效应的临界频带理论,即在临界频带内一个声音对另一个声音信号的遮蔽效应最明显。因此,划分频带的滤波器组要有足够迅速的频率响应,以此保证临界频带外的噪声衰减足够大,使时域和频率内的噪声限定在遮蔽阈值以下。 在AC-3编码器的比特分配技术中,采用了应用广泛的前向和后向自适应比特分配法则。前向自适应方法是编码器计算比特分配,并把比特分配信息明确地编入数据比特流中,其特点是在前端编码过程中使用听觉模型,因此修改模型对接收侧解码过程没有影响;其缺点是降低编码效率,因为要传送比特分配信息而占用了一部分有效比特。后向自适应方法没有得到编码器明确的比特分配信息,而是从数码流中产生比特分配信息,优点是不占用有效比特,因此有更高的传输效率。其缺点是要从接收的数据中计算比特分配,如果计算太复杂会使解码器的成本升高。此外,解码器的算法也会随着编码器听觉模型的改变而改变。AC-3采用混合前向/后向自适应比特分配,在提高码率和降低成本间取得了平衡。 图3为AC-3解码器的原理框图。AC-3解码器的解码原理基本上是编码的逆向过程,首先解码器必须与编码数据流同步,然后从经过数据纠错校验的数码流中分离出控制数据、系统配置参数、编码后的频谱包络及量化后的尾数等内容,根据声音的频谱包络产生比特分配信息,对尾数部分进行反量化,恢复变换系数的指数和尾数,再经过合成滤波器组,把数据由频域变换到时域,最后输出重建的PCM样值信号。 通过对AC-3的了解,可以看到AC-3技术充分利用人耳的感官模型,针对不同性质的信号,采取了相应有效的算法,达到了在保证较高音质的前提下实现较高码率的预期目的,是一种非常高效而又经济的数字音频压缩系统。AC-3是美国数字电视系统的强制标准,是欧洲数字电视系统的推荐标准,同时,AC-3还是DVD系统的强制标准。目前我国正在发展和推广数字电视系统,所有有理由相信AC-3技术会有一个不错的应用前景。
图3为AC-3解码器的原理框图。AC-3解码器的解码原理基本上是编码的逆向过程,首先解码器必须与编码数据流同步,然后从经过数据纠错校验的数码流中分离出控制数据、系统配置参数、编码后的频谱包络及量化后的尾数等内容,根据声音的频谱包络产生比特分配信息,对尾数部分进行反量化,恢复变换系数的指数和尾数,再经过合成滤波器组,把数据由频域变换到时域,最后输出重建的PCM样值信号。 通过对AC-3的了解,可以看到AC-3技术充分利用人耳的感官模型,针对不同性质的信号,采取了相应有效的算法,达到了在保证较高音质的前提下实现较高码率的预期目的,是一种非常高效而又经济的数字音频压缩系统。AC-3是美国数字电视系统的强制标准,是欧洲数字电视系统的推荐标准,同时,AC-3还是DVD系统的强制标准。目前我国正在发展和推广数字电视系统,所有有理由相信AC-3技术会有一个不错的应用前景。


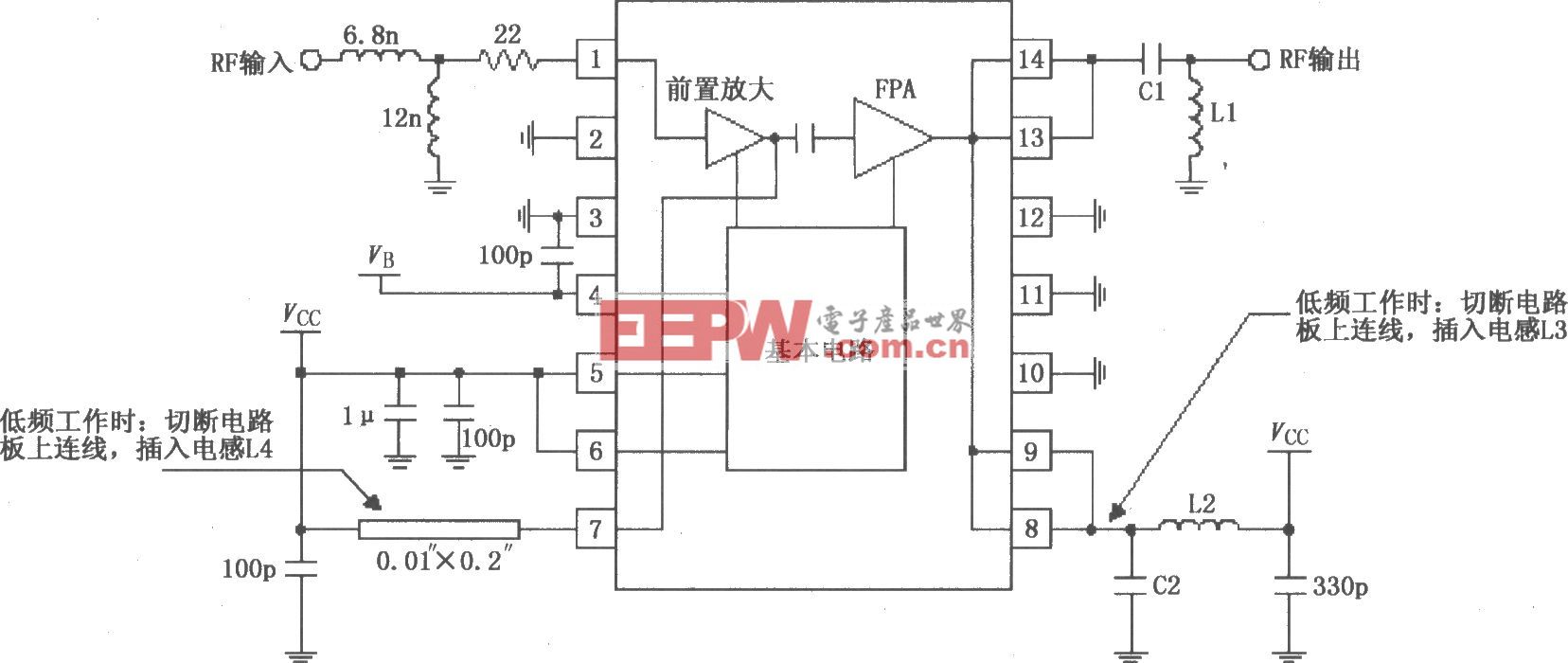


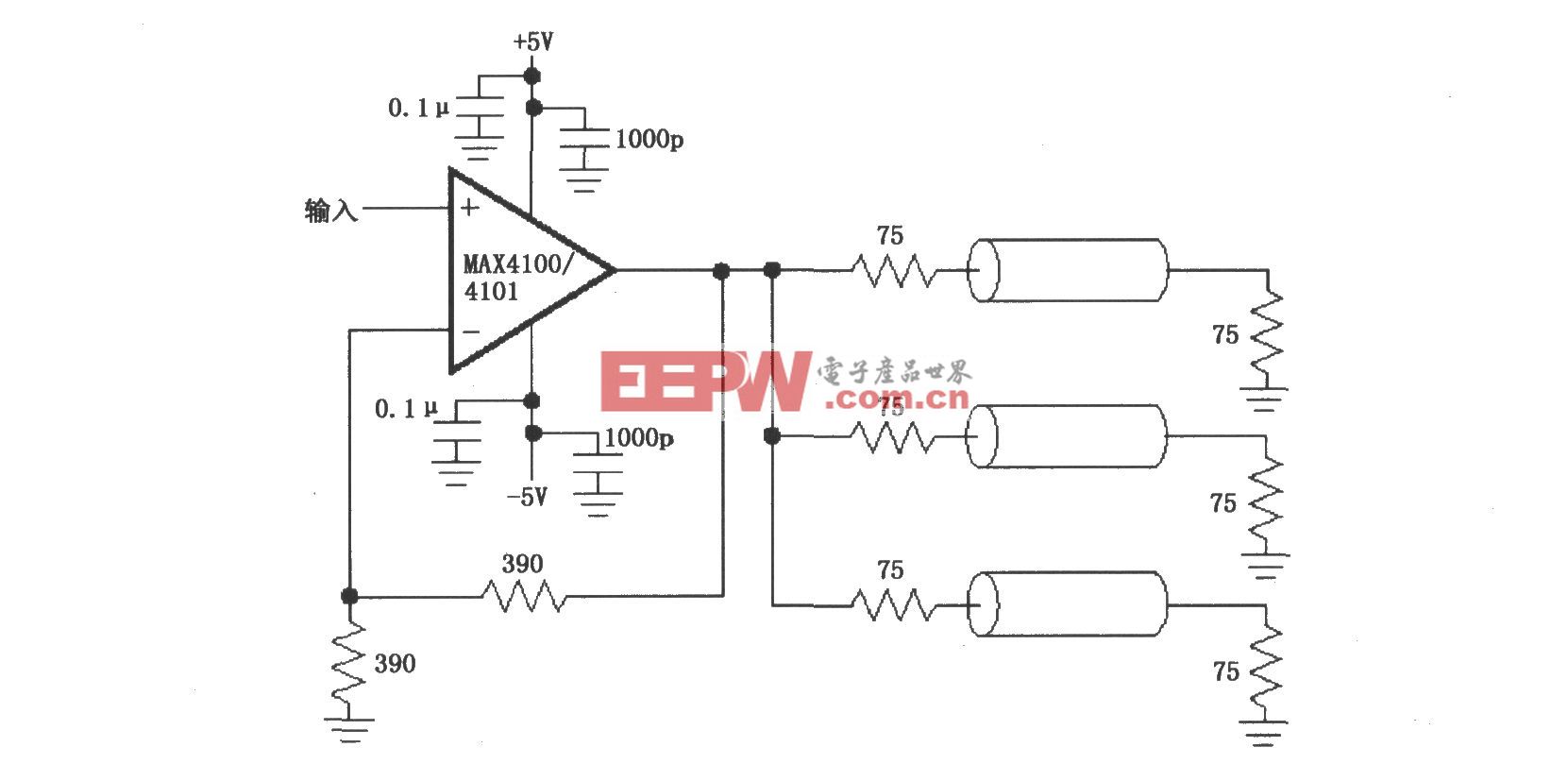

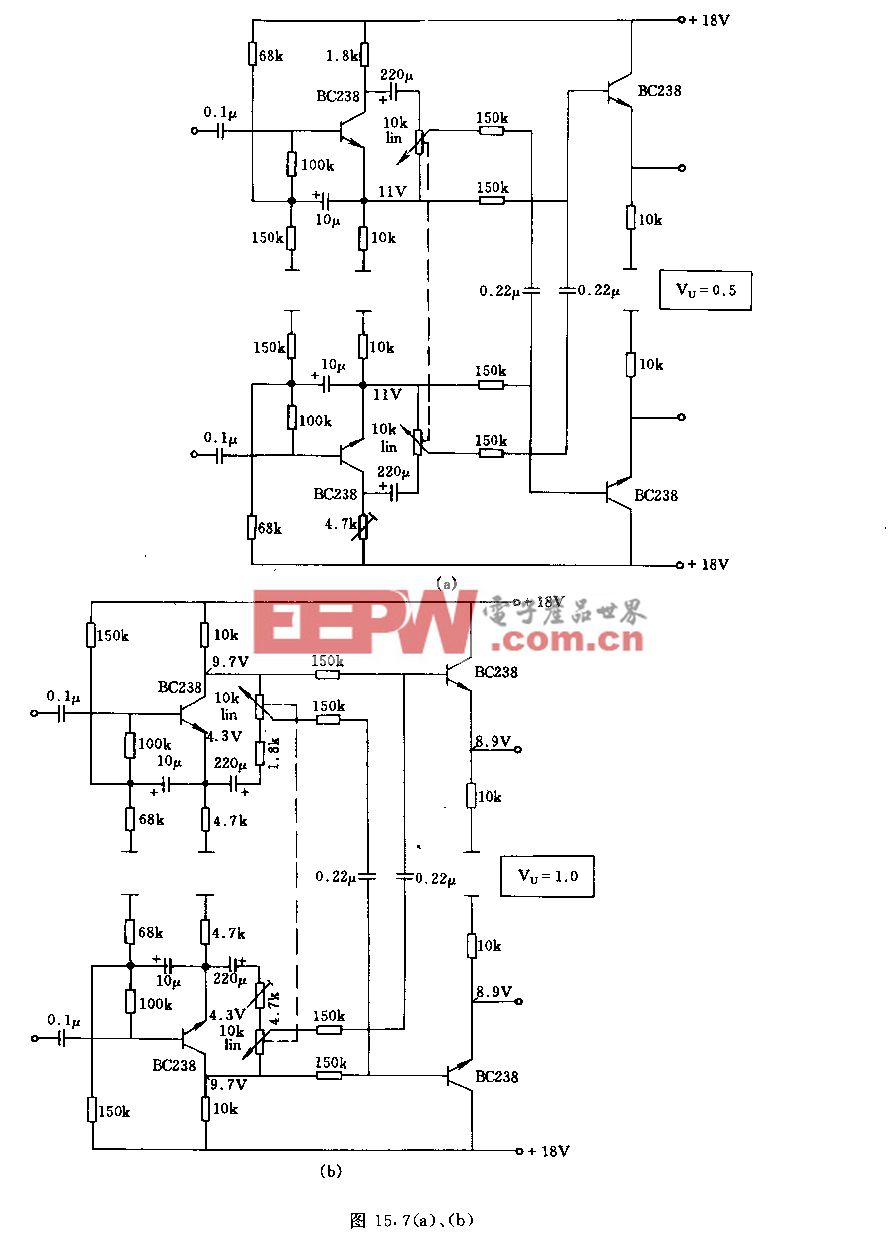

评论