WinCE设计开发常见问题(WinCE开发特性及忠告)
最近一段时间,移动设备开发越来越多的成为了程序员社区的话题。移动设备主要包括智能手机和PDA,是嵌入式开发中很重要的一个方向。在智能手机领域被大多数手机厂商支持的J2ME无疑是领头羊,微软CE平台的SmartPhone也逐渐成为关注焦点。一直不温不火的PDA市场,也在行业应用领域有所收获,Pocket PC由于其开发与Windows平台的一致性而得到了开发人员的青睐。
在长期关注程序员论坛的过程中,我发现由于Windows CE开发的独特性,加之多个版本并存、缺乏中文参考资料,所以论坛上充斥着大量相同的入门问题。我希望在这里能够为刚转入Windows CE开发的程序员明晰一些概念,将现有的Windows CE版本与开发工具之间的关系给大家解释清楚。
Windows CE与平台开发
Windows CE是微软为嵌入式设备打造的操作系统,而嵌入式设备可谓多种多样,这就要求CE操作系统必须是可定制的,所以微软将Windows CE设计为模块化的操作系统。说简单点,我们可以把Windows CE想像成一盒积木,你可以用积木搭建出任何物体,但不一定要把所有的积木都用上。
Windows CE搭建出来的物体就是平台,是适应某种有固定标准的嵌入式设备的操作系统子集,最著名的平台就是Pocket PC了,是提供给没有键盘的掌上电脑使用的平台。由于平台和硬件的一致性,所以有时候我们也用平台的名称来称呼整个系统——硬件与操作系统的总和。
我们也可以自己开发平台,开发工具是微软提供的Platform Builder,Platform Builder的版本号是和Windows CE的版本号一致的。
更多程序员关心的是应用程序的开发,而应用程序开发是针对特定平台的,我们在开发之前必须安装目标平台的SDK,才能够开发出适应目标平台的开发工具。
Windows CE开发环境综述
初学者另外一个比较糊涂的概念是版本的问题,现在市面上能够见到Windows CE的两代产品,它们的内核分别基于Windows CE 3.0和Windows CE.NET(即4.0)。
微软将今年刚面世的Pocket PC 2003和Smart Phone 2003统称为Windows Mobile 2003,我们大多数时候还是习惯地沿用老称谓。
而市面上经常见到的Pocket PC 2002是基于Windows CE 3.0的平台,而Pocket PC 2003则是基于Windows CE.NET的平台,需要注意的是,Pocket PC 2003的内核是Windows CE.NET 4.2。而SmartPhone2003也是基于Windows CE.NET的。SmartPhone的最初版本是2002,基于Windows CE 3.0的,但是微软没有推出SmartPhone2002的中文版。
清晰了平台与CE之间的关系,解释平台与开发工具之间的关系就很容易了。微软提供给应用程序开发者的工具包括:Embedded Visual Tools 3.0,其中包括Embedded Visual C 3.0和Embedded Visual Basic 3.0;Embedded Visual C 4.0和Visual Studio.NET。
开发工具的版本号是与Windows CE的版本号对应的。EVC3.0和EVB3.0是用来开发基于Windows CE 3.0平台的应用程序的,比较常见的平台有:Pocket PC 2002、Pocket PC 2000、Palm-size PC、HPC。而EVC4.0是用来开发Windows CE.NET平台的程序的,主要包括Pocket PC 2003和SmartPhone 2003。
Visual Studio.NET针对嵌入式设备开发需要SDE的支持,而VS.NET 2003中包括了SDE,不需要另外安装。Visual Studio.NET开发的程序需要目标平台支持.NET Compact Framework。现在支持.NET Compact Framework的平台有Pocket PC 2002和Pocket PC 2003。这里需要注意的是SmartPhone 2003是不支持.NET Compact Framework的。
EVB开发入门
微软已经宣布EVB不再支持Windows CE.NET,所以EVB的最终版本是3.0。但由于EVB的易上手性和快速开发的特点,在VS.NET横空出世之前,它成为Windows CE平台上快速开发的不二之选。现在EVB仍然适合Windows CE 3.0平台上小型应用程序的快速开发。如果您不是专职的Windows CE程序员,而只是需要在Windows CE平台上开发整个系统的一部分,那么EVB可以让您用很短的时间开发出您想要的程序。
EVB的开发环境的搭建也是十分简单,您可以从微软的网站上下载EVT 2002,其中包含了EVC 3.0、EVB 3.0和Pocket PC 2002 SDK和SmartPhone 2002 SDK。按照提示将EVB和Pocket PC 2002 SDK安装好后就可以进行开发了。SDK中包含模拟器,在没有实际设备的情况下,可以利用模拟器来调试程序。
这里需要注意的是,开发环境和模拟器之间是通过网络连接协议进行通讯的,所以开发所用的计算机上必须有一个活动的网络连接。如果没有,可以安装微软的虚拟网卡。

EVB的开发环境与VB类似,因为Windows CE应用程序需要在模拟器或者实际设备上调试,所以我们必须选择程序的输出目标。如果您选择了Emulation,在您按下运行(或F5)后,EVB将自动启动模拟器,并把程序下载到模拟器中。
由于新的Windows CE.NET将不再支持EVB,微软建议EVB程序员使用VB.NET开发新的程序,而对于原有的EVB程序也给出了迁移路径,关于这方面的论述,您可以参考MSDN文章《Moving from eMbedded Visual Basic to Visual Basic .NET》。
EVC开发入门
无论是Win32平台还是WinCE平台,Visual C 都是一个强大的开发工具。而EVC也是WinCE上的主流开发工具。EVC支持MFC类库的子集,可以给开发者提供最强大的支持,也使Win32平台上的VC程序员可以很容易地迁移到WinCE平台上。但由于MFC类库需要一个DLL,所以对某些存储空间有限的嵌入式设备来说,这是个很大的负担,所以SmartPhone就不支持MFC。

说这么多,让我们来创建一个EVC的工程。是不是和VC很像,需要提醒大家注意的是,由于嵌入式设备支持的CPU种类很多,我们在选择创建工程类型的同时,也要把该工程所支持的CPU类型选择好。创建工程的过程和VC是一样的。当然不同的平台支持的工程类型是不同的,比如Pocket PC 2003有支持MFC和API的两种工程,而SmartPhone 2003则只有支持API的一种工程。

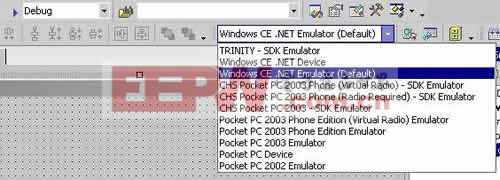
EVC中比VC环境中多了一行下拉菜单的选项,分别用来选择:工程、SDK、CPU类型和输出设备。以Pocket PC为例,在实际设备上调试应该选择Win32(WCE ARMV4)Debug ,而在模拟器上则需要选择Win32(WCE emulator)Debug。
VS.net开发入门
又来到我们的.NET时间了,我怎么说又?最近大家都被JAVA和.NET搞得头昏脑胀了吧?不管大家怎么吵,.NET Compact Framework对于手中缺少开发利器的嵌入式程序员无疑是一大福音。Visual Studio .NET 2003完全支持对移动设备的开发,好了,让我们开始一段奇幻的.NET之旅吧。
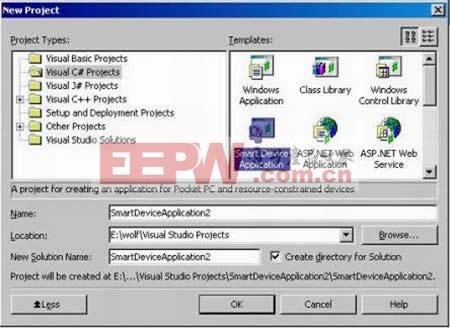
打开VS.net 2003,选File - New – Project,就打开了上面的界面。让我们来建立一个Visual C#的工程,然后选择Smart Device Application,然后OK。
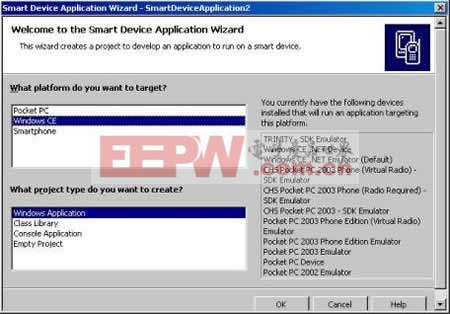
你在这里要选择目标设备:Pocket PC、SmartPhone、Windows CE(指的是其他平台),下面则是选择创建的工程类型,我们选择“Windows Application”,左边是选择的平台所支持的模拟器。最后点击OK,我们就可以进入VS.NET的主界面了。
选择输出设备的情况和EVB十分类似,只需要选择输出设备,而不用选择CPU类型。当然了,因为.NET是运行在虚拟机上的了。在CPU类型众多的嵌入式领域,.NET和JAVA才能真正发挥自己的强项。
当然,我们也可以选择VB.NET作为开发智能设备的语言,情况和C#完全一样。目前智能设备开发只支持C# 和VB.NET。爱好C 的程序员可能还要等上一段时间。
Windows CE 开发的忠告
可以说当我们花了大部分时间将已有的应用程序移植到Microsoft Windows CE中。一般说来,这个计划不是太难。我们起步于Microsoft Win32代码,当然Windows CE是基于Win32应用程序接口(API)的。有利的是,我们的应用程序(即Raima 数据管理器)有方便的使用接口,并包含一个大约由150个子函数组成的库,这些函数都是由C语言写成,可以用来创建、管理和访问数据库。
按建立应用程序的方式来说,我们原以为将它移植到Windows CE中是一项相对简单的C语言编程练习。然而,我们不久便遇到好些困难。从粗心大意的错误开始,比如在基于Windows NT 的Windows CE仿真器上使用Microsoft Windows NT库,接着又违背Windows CE的编程戒律,如"千万不要给Unicode(国际标准组织10646标准)字符分配奇数内存地址"。
大约有百分之九十的问题或多或少地与Unicode有关。尽管Unicode编程不难,但是,当给单字节字符编写代码时,很容易出错(我有过许多次错误)。
下面这些忠告是根据我们在Windows CE上编写Raima 数据管理器的经验总结出来的,但我相信,在做任何其它Windows CE程序之前,它们都值得借鉴。毕竟大多数Windows开发者,当他们创建第一个Windows CE应用程序时,真正运用的是已掌握的Win32知识。
不要在仿真器上使用Windows NT库
这里所讨论的第一个错误实在太愚蠢了,但我还是陷了进去,也许你也会。当用Microsoft VC (5.0版)创建一个Windows CE程序时,你会发现,包含路径(include)、 库路径(library)、及可执行程序路径被自动调整以匹配反应目标环境的选择。因此,比如说为Windows CE模拟器建立应用程序时,你会发现,include路径没有指向Win32的包含文件(在VC目录下),而是指向Windows CE包含文件(在WCE目录下)。千万别去修改。
由于Windows CE在Windows NT下运行,所以仿真器上运行的程序能够调用任一Windows NT动态链接库(DLL)中的函数,即使这个DLL不是模拟器的成员也一样。显然,这不是很好的事,因为相同的函数也许在手持PC(H/PC)或Windows CE设备上不可用,而你的软件最终要能在这些设备上运行。
第一次将非Unicode应用程序装入Windows CE仿真器时,你会发现,许多正在使用的函数它都不支持,例如美国国家标准协会(ANSI)定义的字符函数strcpy()。这也许引诱你去链接Windows NT 运行时间库,以便能解决所有问题。
如果你是刚开始用Windows CE编程,可能你能用的包含文件和库文件是明显的。答案就是,你不要采用那些在写普通Win32或非Windows CE程序时使用的包含文件和库文件。
不要混淆TCHARs和bytes
如果你正在Windows CE上写非Unicode应用程序,你或许要将所有的字符串从单个字符(chars)转换为宽字符(widechars)(例如,C变量类型whcar_t)。几乎所有Windows CE支持的Win32和运行时间库函数都要求宽字符变量。Windows 95不支持Unicode,然而,为了使程序代码具有可移植性,你要尽可能采用tchar.h中定义的TCHAR类型,不要直接使用wchar_t。
TCHAR是定义为wchar_t还是char,取决于预处理器的符号UNICODE是否定义。同样,所有有关字符串处理函数的宏,如_tcsncpy宏,它是定义为Unicode函数wcsncpy还是定义为ANSI函数strncpy,取决于UNICODE是否定义。
在现存的Windows应用程序中,有些代码也许暗示字符长为单字节。这在给字符串分配内存时经常用到,例如:
| int myfunc(char *p) { char *pszFileName; pszFileName = malloc(MAXFILELEN); if(pszFileName) strncpy(pszFileName, p, MAXFILELEN); /*etc*/ |
在这段代码中,分配的内存块应该写作(MAXFILELEN * sizeof(char)),但是大多数程序员喜欢将它简化为MAXFILELEN,因为对于所有的平台来说sizeof(char)的值等于1。然而,当你用TCHARS代替多个字符时,很容易忘记这种固有的概念,于是将代码编写成下面的形式:
| int myfunc(TCHAR *p) { TCHAR *pszFileName; PszFileName = (TCHAR*)malloc(MAXFILELEN); If (pszFileName) tcsncpy(pszFileName, p, MAXFILELEN); /*etc*/ |
这是不行的。它马上会导致出错。这里的错误在于malloc函数中指定变量大小为bytes,然而_tcsncpy函数中使用的第三个变量却指定为TCHARs而不是bytes。当UNICODE被定义时,一个TCHAR等于两个字节数(bytes)。
上述代码段应该改写为:
| int myfunc(TCHAR *p) { TCHAR *pszFileName; PszFileName = (TCHAR*)malloc(MAXFILELEN * sizeof(TCHAR)); if(pszFileName) tcsncpy(pszFileName, p, MAXFILELEN); /*etc*/ |
不要将Unicode 字符串放入奇数内存地址
在Intel系列处理器上,你可以在一奇数内存地址储存任何变量或数组,不会导致任何致命的错误影响。但在H/PC上,这一点不一定能行 ? 你必须对大于一个字节的数据类型小心谨慎,包括定义为无符号短型(unsigned short) 的wchar_t。当你设法访问它们的时候,将它们置于奇地址会导致溢出。
编辑器经常在这些问题上提醒你。你无法管理堆栈变量地址,并且编辑器会检查确定这些地址与变量类型是否相匹配。同样,运行时间库必须保证从堆中分配的内存总是满足一个word边界 ,所以你一般不必担心那两点。但是,如果应用程序含有用memcpy()函数拷贝内存区域的代码,或者使用了某种类型的指针算术以确定内存地址,问题也许就出现了。考虑下面的例子:
| int send_name (TCHAR * pszName) { char *p, *q; int nLen=(_tcslen(pszName) 1) * sizeof(TCHAR); p=maloc(HEADER_SIZE nLen); if(p) { q = p HEADER_SIZE; _tcscpy((TCHAR*)q, pszName); } /* etc */ |
这段代码是从堆中分配内存并复制一个字符串,在字符串的开头留一个HEADER_SIZE的大小。假设UNICODE定义了,那么该字符串就是一个widechar字符串。如果HEADER_SIZE是一个偶数,这段代码就会正常工作,但如果HEADER_SIZE为奇数,这段代码就会出错,因为q指向的地址也将为奇数。
注意,当你在Intel系列处理器中的Windows CE仿真器上测试这段代码时,这个问题是不会发生的。
在这个例子中,只要确保HEADER_SIZE为偶数,你就可以避免问题的发生。然而,在某些情况下你也许不能这么做。例如,如果程序是从一台式PC输入数据,你也许不得不采用事先定义过的二进制格式,尽管它对H/PC不适合。在这种情况下,你必须采用函数,这些函数用字符指针控制字符串而不是TCHAR指针。如果你知道字符串的长度,就可以用memcpy()复制字符串。因此,采用逐个字节分析Unicode字符串的函数也许足以确定字符串在widechars中的长度。
在ANSI和Unicode字符串之间进行翻译
如果你的Windows CE应用程序接口于台式PC,也许你必须操作PC机中的ANSI字符串数据(例如,char字符串)。即使你在程序中只用到Unicode字符串,这都是事实。
你不能在Windows CE上处理一个ANSI字符串,因为没有操纵它们的库函数。最好的解决办法是将ANSI字符串转换成Unicode字符串用到H/PC上,然后再将Unicode字符串转换回ANSI字符串用到PC上。为了完成这些转换,可采用MultiByteToWideChar()和WideCharToMultiByte () Win32 API 函数。
对于Windows CE 1.0的字符串转换,劈开(hack)
在Windows CE 1.0 版本中,这些Win32API函数还没有完成。所以如果你想既要支持CE 1.0又能支持CE 2.0,就必须采用其它函数。将ANSI字符串转换成Unicode字符串可以用wsprintf(),其中第一个参数采用一widechar字符串,并且认识"%S"(大写),意思是一个字符串。由于没有wsscanf() 和 wsprintfA(),你必须想别的办法将Unicode字符串转换回ANSI字符串。由于Windows CE 1.0不在国家语言支持(NLS)中,你也许得求助于hack,如下所示:
| /* Definition / prototypes of conversion functions Multi-Byte (ANSI) to WideChar (Unicode) atow() converts from ANSI to widechar wtoa() converts from widechar to ANSI */ #if ( _WIN32_WCE >= 101) #define atow(strA, strW, lenW) MultiByteToWidechar (CP_ACP, 0, strA, -1, strW, lenW) #define wtoa(strW, strA, lenA) WideCharToMutiByte (CP_ACP, 0, strW, -1, strA, lenA, NULL, NULL) #else /* _WIN32_WCE >= 101)*/ /* MultiByteToWideChar () and WideCharToMultiByte() not supported o-n Windows CE 1.0 */ int atow(char *strA, wchar_t *strW, int lenW); int wtoa(wchar_t *strW, char *strA, int lenA); endif /* _WIN32_WCE >= 101*/ #if (_WIN32_WCE 101) int atow(char *strA, wchar_t *strW, int lenW) { int len; char *pA; wchar_t *pW; /* Start with len=1, not len=0, as string length returned must include null terminator, as in MultiByteToWideChar() */ for(pA=strA, pW=strW, len=1; lenW; pA , pW , lenW--, len ) { *pW = (lenW = =1) ? 0 : (wchar_t)( *pA); if( ! (*pW)) break; } return len; } int wtoa(wxhar_t *strW, char *strA, int lenA) { int len; char *pA; wchar_t *pW; /* Start with len=1,not len=0, as string length returned Must include null terminator, as in WideCharToMultiByte() */ for(pA=strA, pW=strW, len=1; lenA; pa , pW , lenA--, len ) { pA = (len==1)? 0 : (char)(pW); if(!(*pA)) break; } return len; } #endif /*_WIN32_WCE101*/ |
这种适合于Windows CE 1.0的实现办法比使用wsprintf()函数要容易,因为使用wsprintf()函数更难以限制目标指针所指向的字符串的长度。
选择正确的字符串比较函数
如果你要分类Unicode标准字符串,你会有以下几个函数可供选择:
wcscmp(), wcsncmp(), wcsicmp(), 和wcsnicmp()
wcscoll(), wcsncoll(), wcsicoll(),和wcsnicoll()
CompareString()
第一类函数可用来对字符串进行比较,不参考当地(Locale)或外文字符。如果你永远不想支持外文,或者你仅仅想测试一下两个字符串的内容是否相同,这类函数非常好用。
第二类函数使用现有的当地设置(current locale settings)(系统设置,除非你在字符串比较函数之前调用了wsetlocale()函数)来比较两个字符串。这些函数也能正确分类外文字符。如果当地的字符"C"("C" locale)被选定,这些函数与第一类函数就具有了相同的功能。
第三类函数是Win32函数CompareString()。这个函数类似于第二类函数,但是它允许你指定当地设置(the locale)作为一个参数,而不是使用现有的当地设置(current locale settings)。CompareString()函数允许你选择性地指定两个字符串的长度。你可以将第二个参数设置为NORM_IGNORECASE,从而使函数比较字符串时不比较大小写。
通常,即使不将第二个参数设置为NORM_IGNORECASE,CompareString()函数也不用来区分大小写。我们经常用wcsncoll()函数来区分大小写,除非使用当地的字符"C"("C" locale)。所以,在我们的代码中,不使用CompareString()函数来区分大小写,而用wcsncoll()函数来区分大小写
不要使用相对路径
与Windows NT不一样,Windows CE没有当前目录这个概念,因此,任何路径只是相对于根目录而言的。如果你的软件给文件或目录使用相对路径,那么你很可能把它们移到别的地方了。例如,路径".abc"在Windows CE中被当作"abc"看待。
移走了对calloc()和 time()函数的调用
C运行库中的calloc()函数不能使用,但是malloc()函数可以代替calloc()函数。并且不要忘记,calloc()函数初始化时分配的内存为零,而malloc()函数不一样。同样,time()函数也不能使用,但你可以使用Win32函数GetSystemTime()函数代替time()函数。
经过以上的警告后,你会高兴地学习最后令你惊讶的两点忠告。
不需要改变Win32 输入/输出(I/O)文件的调用
Win32的输入输出函数,Windows CE也支持。允许你象访问Win32文件系统那样访问对象。CreateFile()函数在Windows CE中不能辩认标志FILE_FLAG_RANDOM_ACCESS,但是这个标志仅用作可选的磁盘访问,并且不影响函数调用的功能。
不要担心字节的状态
当我们把应用程序写入Windows CE时,有了一个美好的发现,那就是Windows CE的数字数据类型的字节状态与Intel结构的字节状态一样,在所有的处理器上,Windows CE均支持。
几乎象所有的数据库引擎一样,Raima数据库管理器在数据库文件中以二进制形式保存数字数据。这就意味一个记录无论何时写入数据库或从数据库读出,均被当作一系列的字节来处理,不管它域的内容。只要数据库文件不要传给别的任何系统,数字数据的字节状态问题就解决了。如果数据库文件被一个来自原始系统且带有不同字节状态的处理器访问,数字数据将被误解。
无论何时,当你在拥有不同处理器的机器上传输文件时,就会出现这个问题。在这个问题上,值得高兴的是所有类型的处理器都使用相同的字节状态。
在使用Windows CE时,这些忠告应该引起你足够的重视,避免学习时走弯路。
linux操作系统文章专题:linux操作系统详解(linux不再难懂)



评论