强化DPD演算效能SoC FPGA提升蜂巢网络设备整合度
ARM Cortex-A9处理器藉由丰富的运算资源可执行更多功能,而这些资源有助提升效能。举例而言,在硬件处理子系统中,每个ARM Cortex-A9处理器都内含一个浮点运算单元和一个NEON多媒体加速器。NEON单元是一个128位元的单一指令多重资料(SIMD)向量协同处理器,可同时执行两个32×32b乘法指令;由于NEON单元皆用于乘法累积(MAC)运算,因此非常符合自动相关矩阵运算功能所需。透过NEON模组可运用软件Intrinsics,这可以在系统组装时免除编写低阶程式的需求。因此,运用硬件处理子系统中更多的功能,可以比Microblaze等软件处理器或外接式DSP处理器大幅提升效能。
本文引用地址:http://www.eepw.com.cn/article/221570.htm为提升数字预失真效能,设计人员须进一步利用可编程逻辑将这些功能移到硬件上。然而,由于软件是以C/C++编写,工程师需要一些时间将C/C++语言转换成可在可编程逻辑中运用VHDL或Verilog执行的硬件。
这个问题现在已可藉由各种高阶合成(HLS)工具(例如C语言至暂存器转移层级工具,C-to-RTL工具)得以解决。这些工具让具备C/C++程式经验的程式设计人员透过现场可编程门阵列(FPGA)拥有硬件能力。业界高阶合成工具可让软件和系统设计人员更容易将C/C++程式码对应到可编程逻辑,让程式码得以重用,并提供最佳可携性和自由设计空间,最终达成最高生产力。
图4展示运用高阶合成工具的典型C/C++设计流程。这工具的输出是暂存器转移层级(RTL),可轻松与资料路径预失真器或上游制程等既有的硬件设计进行整合,当然也可连至资料转换器。运用这项工具,演算法可快速转移至硬件,其中这项工具会使用AXI界面连至硬件处理子系统,如图5所示。
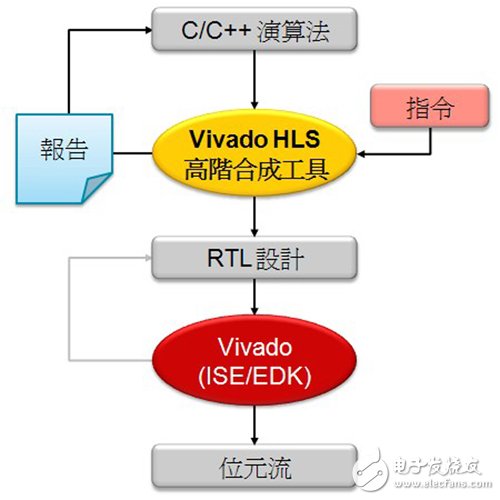
图4 高阶合成设计流程
在可编程逻辑中以高时脉执行自动相关矩阵运算演算法,可对效能产生重大的效益,仅针对这项功能而言,其效能增益就可比软件建置的功能多七十倍,而且仅用完全可编程SoC元件中3%的逻辑。
从原来参考的C/C++程式码进行基本最佳化,并运用ARM Cortex-A9处理器更有效地执行运算,结果显示仅用软件进行最佳化所得的效能则比没有变动的程式码高出二至三倍。再使用NEON多媒体协同处理器就能产生更多的效能增益。图5为自动相关矩阵运算架构。其中针对相关矩阵运算功能,其整体效能增益比软件建置的功能多七十倍。
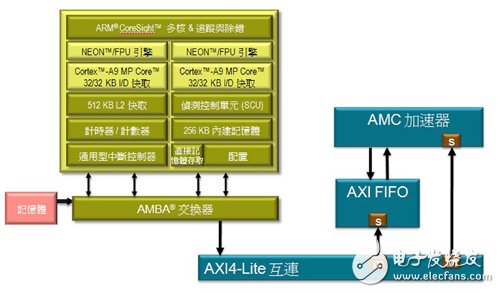
图5 整合可编程逻辑的自动相关矩阵运算硬件加速器演算法与处理系统
最终,无线传输效能决定硬件和软件间所需的数字预失真功能分区。藉由调高频谱校准程度以达到更佳效率的做法可能影响效能,原因在于要达到这种校准程度需要更高的处理效能。其他影响效能的因素也可能是更多的传输频宽或是多个天线共用预测引擎。这只能针对单一的处理器节省空间和成本,加上采用另外的硬件加速器为许多资料路径预失真器计算系数。
在一些情况中,用ARM Cortex-A9处理器配合NEON单元执行的软件效能可能已足够,例如频宽较窄的传输配置或只有一或两个天线路径处理资料的设计,可以为那些无线传输配置降低元件占用面积和物料成本。
为将效能提升至更高的水准,设计人员可在建置自动相关矩阵运算功能时加入更多平行运算机制,只要增加支援逻辑的建置则可达到更快的更新时间。进一步的软件设定也可显示从硬件加速受惠的演算法的其他面向。无论有任何需求,现在的工具和芯片都可让设计人员去探索在效能、面积和功耗间的各种取舍方法,在不受限于特定独立型元件或程式设计方式的情况下,可用最少的力气达成更高的运作效率。
无线传输基础设备需要低成本、低功耗和高可靠性。整合是达到这些目标的关键,但时至今日业界仍须在灵活度或产品上市时程方面做某种程度的让步。此外,在处理效能方面仍持续对宽频无线传输和更高作业效率有更多的要求。完全可编程SoC元件具备双核心处理器子系统、高效能和低功耗的可编程逻辑,可为目前和未来的无线传输需求提供可行解决方案。
无论是远端无线设备或者是主动式天线阵列,设计人员可以打造具备更高生产力的产品,同时提供比现有的特定应用标准产品(ASSP)或特定应用集成电路(ASIC)方案更高的灵活度和效能。

fpga相关文章:fpga是什么
pa相关文章:pa是什么











评论