Linux超线程感知的调度算法研究
1 超线程技术背景
传统的处理器内部存在着多种并行操作方式。①指令级并行ILP(Instruction Level Paramllelism):同时执行几条指令,单CPU就能完成。但是,传统的单CPU处理器只能同时执行一个线程,很难保证CPU资源得到100%的利用,性能提高只能通过提升时钟频率和改进架构来实现。②线程级并行TLP(Thread Level Paramllesim):可以同时执行多个线程,但是需要多处理器系统的支持,通过增加CPU的数量来提高性能。
超线程微处理器将同时多线程技术SMT(Simultaneous Multi-Threading)引入Intel体系结构,支持超线程技术的操作系统将一个物理处理器视为两个逻辑处理器,并且为每个逻辑处理器分配一个线程运行。物理处理器在两个逻辑处理器之间分配高速缓存、执行单元、总线等执行资源,让暂时闲置的运算单元去执行其他线程代码,从而最大限度地提升CPU资源的利用率。
Intel 超线程技术通过复制、划分、共享Intel的Netburst微架构的资源让一个物理CPU中具有两个逻辑CPU。(1)复制的资源:每个逻辑CPU都维持一套完整的体系结构状态,包括通用寄存器、控制寄存器、高级可编程寄存器(APIC)以及一些机器状态寄存器,体系结构状态对程序或线程流进行跟踪。从软件的角度,一旦体系结构状态被复制,就可以将一个物理CPU视为两个逻辑CPU。(2)划分的资源:包括重定序(re-order)缓冲、Load/Store缓冲、队列等。划分的资源在多任务模式时分给两个逻辑CPU使用,在单任务模式时合并起来给一个逻辑CPU使用。(3)共享的资源:包括cache及执行单元等,逻辑CPU共享物理CPU的执行单元进行加、减、取数等操作。
在线程调度时,体系结构状态对程序或线程流进行跟踪,各项工作(包括加、乘、加载等)由执行资源(处理器上的单元)负责完成。每个逻辑处理器可以单独对中断作出响应。第一个逻辑处理器跟踪一个线程时,第二个逻辑处理器可以同时跟踪另一个线程。例如,当一个逻辑处理器在执行浮点运算时,另一个逻辑处理器可以执行加法运算和加载操作。拥有超线程技术的CPU可以同时执行处理两个线程,它可以将来自两个线程的指令同时发送到处理器内核执行。处理器内核采用乱序指令调度并发执行两个线程,以确保其执行单元在各时钟周期均处于运行状态。
图1和图2分别为传统的双处理器系统和支持超线程的双处理器系统。传统的双处理器系统中,每个处理器有一套独立的体系结构状态和处理器执行资源,每个处理器上只能同时执行一个线程。支持超线程的双处理器系统中,每个处理器有两套独立体系结构状态,可以独立地响应中断。

2 Linux超线程感知调度优化
Linux从2.4.17版开始支持超线程技术,传统的Linux O(1)调度器不能区分物理CPU和逻辑CPU,因此不能充分利用超线程处理器的特性。Ingo Monlar编写了“HT-aware scheduler patch”,针对超线程技术对O(1)调度器进行了调度算法优化:优先安排线程在空闲的物理CPU的逻辑CPU上运行,避免资源竞争带来的性能下降;在线程调度时考虑了在两个逻辑CPU之间进行线程迁移的开销远远小于物理CPU之间的迁移开销以及逻辑CPU共享cache等资源的特性。这些优化的相关算法被Linux的后期版本所吸收,具体如下:
(1)共享运行队列
在对称多处理SMP(Symmetrical Multi-Processing)环境中,O(1)调度器为每个CPU分配了一个运行队列,避免了多CPU共用一个运行队列带来的资源竞争。Linux会将超线程CPU中的两个逻辑CPU视为SMP的两个独立CPU,各维持一个运行队列。但是这两个逻辑CPU共享cache等资源,没有体现超线程CPU的特性。因此引入了共享运行队列的概念。HT-aware scheduler patch在运行队列struct runqueue结构中增加了nr_cpu和cpu两个属性,nr_cpu记录物理CPU中的逻辑CPU数目,CPU则指向同属CPU(同一个物理CPU上的另一个逻辑CPU)的运行队列,如图3所示。
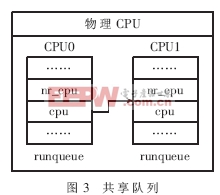
在Linux中通过调用sched_map_runqueue( )函数实现两个逻辑CPU的运行队列的合并。sched_map_runqueue( )首先会查询系统的CPU队列,通过phys_proc_id(记录逻辑CPU所属的物理CPU的ID)判断当前CPU的同属逻辑CPU。如果找到同属逻辑CPU,则将当前CPU运行队列的cpu属性指向同属逻辑CPU的运行队列。
(2)支持“被动的”负载均衡
用中断驱动的均衡操作必须针对各个物理 CPU,而不是各个逻辑 CPU。否则可能会出现两种情况:一个物理 CPU 运行两个任务,而另一个物理 CPU 不运行任务;现有的调度程序不会将这种情形认为是“失衡的”。在调度程序看来,似乎是第一个物理处理器上的两个 CPU运行1-1任务,而第二个物理处理器上的两个 CPU运行0-0任务。
在2.6.0版之前,Linux只有通过load_balance( )函数才能进行CPU之间负载均衡。当某个CPU负载过轻而另一个CPU负载较重时,系统会调用load_balance( )函数从重载CPU上迁移线程到负载较轻的CPU上。只有系统最繁忙的CPU的负载超过当前CPU负载的 25% 时才进行负载平衡。找到最繁忙的CPU(源CPU)之后,确定需要迁移的线程数为源CPU负载与本CPU负载之差的一半,然后按照从 expired 队列到 active 队列、从低优先级线程到高优先级线程的顺序进行迁移。
在超线程系统中进行负载均衡时,如果也是将逻辑CPU等同于SMP环境中的单个CPU进行调度,则可能会将线程迁移到同一个物理CPU的两个逻辑CPU上,从而导致物理CPU的负载过重。
在2.6.0版之后,Linux开始支持NUMA(Non-Uniform Memory Access Architecture)体系结构。进行负载均衡时除了要考虑单个CPU的负载,还要考虑NUMA下各个节点的负载情况。
Linux的超线程调度借鉴NUMA的算法,将物理CPU当作NUMA中的一个节点,并且将物理CPU中的逻辑CPU映射到该节点,通过运行队列中的node_nr_running属性记录当前物理CPU的负载情况。
Linux通过balance_node( )函数进行物理CPU之间的负载均衡。物理CPU间的负载平衡作为rebalance_tick( )函数中的一部分在 load_balance( )之前启动,避免了出现一个物理CPU运行1-1任务,而第二个物理CPU运行0-0任务的情况。balance_node( )函数首先调用 find_
busiest_node( )找到系统中最繁忙的节点,然后在该节点和当前CPU组成的CPU集合中进行 load_balance( ),把最繁忙的物理CPU中的线程迁移到当前CPU上。之后rebalance_tick( )函数再调用load_balance(工作集为当前的物理CPU中的所有逻辑CPU)进行逻辑CPU之间的负载均衡。
(3)支持“主动的”负载均衡
当一个逻辑 CPU 变成空闲时,可能造成一个物理CPU的负载失衡。例如:系统中有两个物理CPU,一个物理CPU上运行一个任务并且刚刚结束,另一个物理CPU上正在运行两个任务,此时出现了一个物理CPU空闲而另一个物理CPU忙的现象。










评论