深度学习基础概念笔记
学习 tensorflow,caffe 等深度学习框架前,需要先了解一些基础概念。本文以笔记的形式记录了一个零基础的小白需要先了解的一些基础概念。
本文引用地址:http://www.eepw.com.cn/article/201807/383751.htm人工智能,机器学习和深度学习的关系
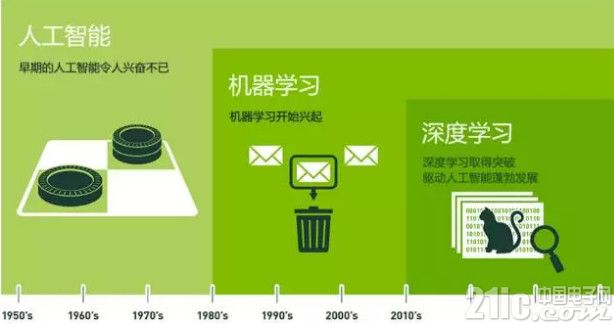
人工智能(Artificial Intelligence)——为机器赋予人的智能
强人工智能(General AI):无所不能的机器,它有着我们所有的感知(甚至比人更多),我们所有的理性,可以像我们一样思考
弱人工智能(Narrow AI):弱人工智能是能够与人一样,甚至比人更好地执行特定任务的技术。例如,Pinterest 上的图像分类;或者 Facebook 的人脸识别。
强人工智能是愿景,弱人工智能是目前能实现的。
机器学习—— 一种实现人工智能的方法
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。
深度学习——一种实现机器学习的技术
机器学习可以通过神经网络来实现。可以将深度学习简单理解为,就是使用深度架构(比如深度神经网络)的机器学习方法。目前深度架构大部分时候就是指深度神经网络。
神经网络组成
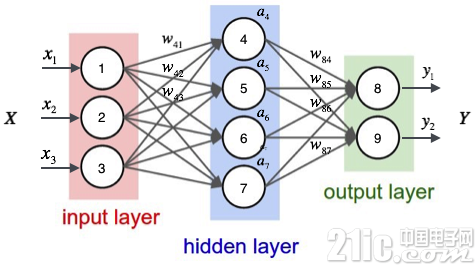
一个神经网络由许多神经元组成,每个圆圈是一个神经元,每条线表示神经元之间的连接。x 表示的输入数据,y 表示的是输出数据,w 表示每层连接的权重。w 也就是我们构造完神经网络之后需要确定的。
最左边的叫做输入层,这层负责接受输入数据。
最右边的叫做输出层,我们可以从这层获取神经网络输出数据
输入层和输出层之间叫做隐藏层。隐藏层层数不定,简单的神经网络可能是 2-3 层,复杂的也可能成百上千层,隐藏层较多的就叫做深度神经网络。
深层网络比浅层网络的表达能力更强,能够处理更多的数据。但是深度网络的训练更加复杂。需要大量的数据,很多的技巧才能训练好一个深层网络。
问题:假设计算速度足够快,是不是深度网络越深越好?
不是。深度网络越深,对架构和算法的要求就越高。在超过架构和算法的瓶颈后,再增加深度也是徒劳。
神经元(感知器)
神经网络由一个个的神经元构成,而一个神经元也由三部分组成。
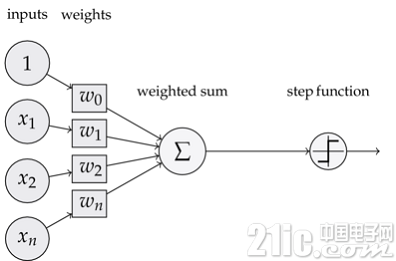
输入权值 每个输入会对应一个权值 w,同时还会有一个偏置值 b。也就是图中的 w0。训练神经网络的过程,其实就是确定权值 w 的过程。
激活函数 经过权值运算之后还会经历激活函数再输出。比如我们可以用阶跃函数 f 来表示激活函数。
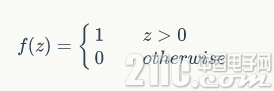
输出 最终的输出,感知器的输出可以用这个公式来表示
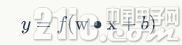
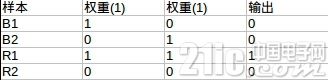
神经元可以拟合任意的线性函数,如最简单拟合 and 函数。
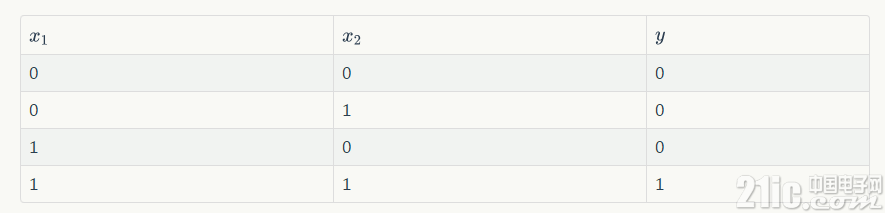
and 函数真值表如上图所示。取 w1 = 0.5;w2 = 0.5 b = -0.8。激活函数取上面示例的阶跃函数 f 表示。可以验证此时神经元能表示 and 函数。
如输入第一行,x1 = 0,x2 = 0 时,可以得到

y 为 0,这就是真值表的第一行。
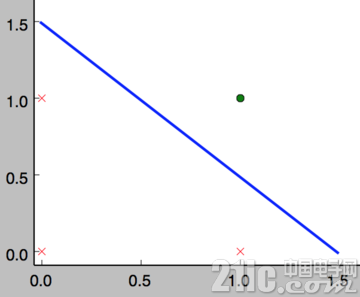
在数学意义上,可以这样理解 and 函数的神经元。它表示了一个线性分类问题,它就像是一条直线把分类 0(false,红叉)和分类 1(true,绿点)分开
而实际上,神经元在数学上可以理解为一个数据分割问题。神经元是将神经网络转换成数学问题的关键。比如需要训练神经网络做一个分类器,那么在数学上可以将输入的参数(x1,x2...,xn)理解为 m 维坐标系(设 x 是 m 元向量)上的 n 个点,而每个神经元则可以理解为一个个拟合函数。取 m 为 2,放在最简单的二维坐标系里面进行理解。
此时输入参数对应的是下图中的黑点,每个神经元就是黑线(由于激励函数的存在,不一定像下图一样是线性的,它可以是任意的形状)。神经网络由一个个神经元组成,这些神经元表示的拟合函数相互交错就形成了各种各样的区域。在下图中可以直观的看到,此时分类问题就是一个数学的问题,输入参数落在 A 区域,那么就认为他是分类 1,落在 B 区域,则认为他是分类 2。依次类推,我们便建立了神经网络分类器在数学上的表现含义。

激活函数
事实上,一个神经元不能拟合异或运算。在下图中可以直观的看到,你无法直接用一条直线将分类 0 和分类 1 分隔开。
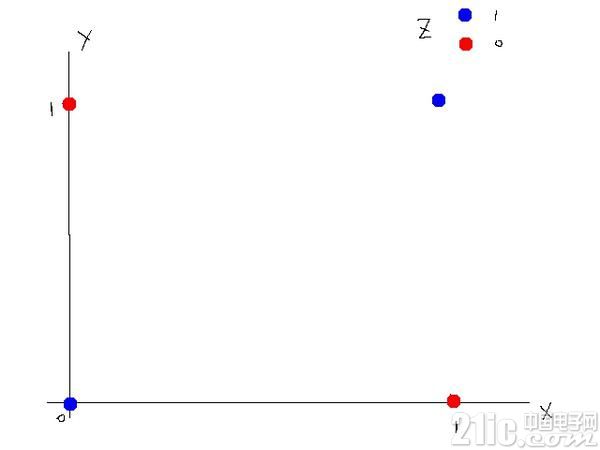
此时可以借助激活函数来做分割。激活函数选择阀值函数,也就是当输入大于某个值时输出 1(激活),小于等于那个值则输出 0(没有激活)。
拟合异或函数的神经网络如图所示:
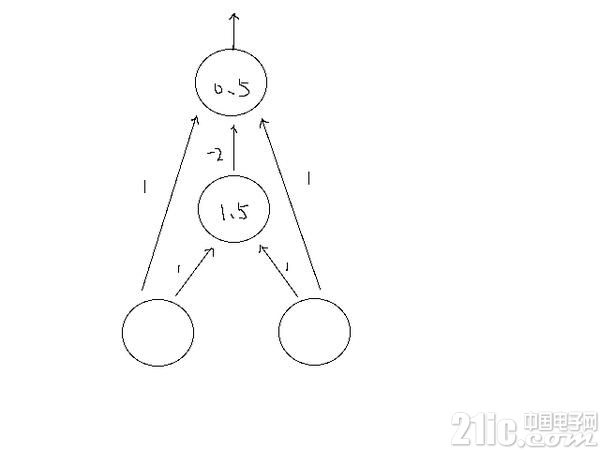
图中神经网络分成三层。在第二层中,如果输入大于 1.5 则输出 1,否则 0;第三层,如果输入大于 0.5,则输出 1,否则 0.
第一层到第二层(阀值 1.5):
第二层到第三层(阀值 0.5):

可以看到最终结果与异或结果吻合。
其实,这里放在数学上理解体现的是一个升维思想。放在二维坐标中无法分割的点,可以放在三维坐标中分割。上面的神经网络可以理解为只有最后一层,三个参数的神经元。激活函数是用来构造第三个参数的方式。这样等同于将三个点放在三维坐标系中做数据分割。相当于在二维中无法解决中的问题升维到三维中解决。

深度学习过程
构造神经网络
确定学习目标
学习
如何进行深度学习,过程基本都可以分为这三步来做。用一个简单的例子来说明。如图,假设我们需要通过深度学习来识别手写图片对应的数字。
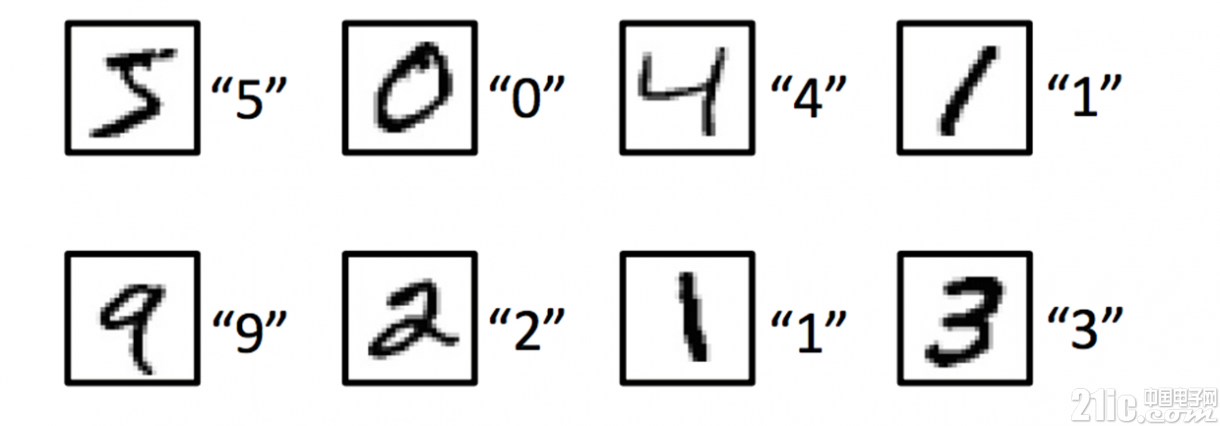
1.构造神经网络。这里可以采用最简单的全连接神经网络,也可以采用卷积神经网络。同时确定神经元的激励函数,神经网络的层数等。基础概念篇不做过多介绍
2.确定学习目标。这里简单假设我们所有输入的都是手写的数字图片。那么这里就有 10 个输出,分别对应 0~9 的数字的比例。我们用 [y0,y1,...y9]表示,每个 y 值代表这张图可能对应该数字的概率(y0 表示这张图是数字 0 的概率)。对于上图中第一个输入图片,在训练过程中,我们知道第一张图片输出应该是数字 5。于是我们期望输出是 [0,0,0,0,0,1,0,0,0,0]。但是实际上,我们的模型不是完美的,肯定会有误差,我们得到的结果可能是 [0,0,0.1,0,0,0.88,0,0,0,0.02]。那么就会有个训练得到的结果和期望结果的误差。
这时候我们的学习目标也就是希望这个误差能够最小。误差用 L 来表示,学习目标就是找到权值 w,使得 L 最小。当然,这里涉及到我们需要用一个公式来表达这个误差 L,这个公式选取也很有学问,不同的公式最终在学习过程时收敛速度是不一样的,通过训练模型得到的权值 w 也是不一样的。这里先不多介绍。
3.学习。假设我们神经模型确定下来的权值 w 与 L 的关系如图所示(这里我们考虑最简单的二维坐标下的情况,原理是相通的,推广到多元坐标也是适用的)。由于数学模型的复杂,这里找最小值 L 的过程其实是找局部最小值的过程。


评论