怎样加速“深度学习”?GPU、FPGA还是专用芯片?
计算机发展到今天,已经大大改变了我们的生活,我们已经进入了智能化的时代。但要是想实现影视作品中那样充分互动的人工智能与人机互动系统,就不得不提到深度学习。
本文引用地址:http://www.eepw.com.cn/article/201803/377456.htm深度学习
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习的概念由Hinton等人于2006年提出。基于深信度网(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等人提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分.不同的学习框架下建立的学习模型很是不同.
例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。
Artificial Intelligence,也就是人工智能,就像长生不老和星际漫游一样,是人类最美好的梦想之一。虽然计算机技术已经取得了长足的进步,但是到目前为止,还没有一台电脑能产生“自我”的意识。是的,在人类和大量现成数据的帮助下,电脑可以表现的十分强大,但是离开了这两者,它甚至都不能分辨一个喵星人和一个汪星人。
图灵(图灵,大家都知道吧。计算机和人工智能的鼻祖,分别对应于其著名的“图灵机”和“图灵测试”)在 1950 年的论文里,提出图灵试验的设想,即,隔墙对话,你将不知道与你谈话的,是人还是电脑。这无疑给计算机,尤其是人工智能,预设了一个很高的期望值。但是半个世纪过去了,人工智能的进展,远远没有达到图灵试验的标准。这不仅让多年翘首以待的人们,心灰意冷,认为人工智能是忽悠,相关领域是“伪科学”。
但是自 2006 年以来,机器学习领域,取得了突破性的进展。图灵试验,至少不是那么可望而不可及了。至于技术手段,不仅仅依赖于云计算对大数据的并行处理能力,而且依赖于算法。这个算法就是,Deep Learning。借助于 Deep Learning 算法,人类终于找到了如何处理“抽象概念”这个亘古难题的方法。
2012年6月,《纽约时报》披露了Google Brain项目,吸引了公众的广泛关注。这个项目是由著名的斯坦福大学的机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家JeffDean共同主导,用16000个CPU Core的并行计算平台训练一种称为“深度神经网络”(DNN,Deep Neural Networks)的机器学习模型(内部共有10亿个节点。这一网络自然是不能跟人类的神经网络相提并论的。要知道,人脑中可是有150多亿个神经元,互相连接的节点也就是突触数更是如银河沙数。曾经有人估算过,如果将一个人的大脑中所有神经细胞的轴突和树突依次连接起来,并拉成一根直线,可从地球连到月亮,再从月亮返回地球),在语音识别和图像识别等领域获得了巨大的成功。
项目负责人之一Andrew称:“我们没有像通常做的那样自己框定边界,而是直接把海量数据投放到算法中,让数据自己说话,系统会自动从数据中学习。”另外一名负责人Jeff则说:“我们在训练的时候从来不会告诉机器说:‘这是一只猫。’系统其实是自己发明或者领悟了“猫”的概念。”

2012年11月,微软在中国天津的一次活动上公开演示了一个全自动的同声传译系统,讲演者用英文演讲,后台的计算机一气呵成自动完成语音识别、英中机器翻译和中文语音合成,效果非常流畅。据报道,后面支撑的关键技术也是DNN,或者深度学习(DL,DeepLearning)。
用什么加快计算速度?异构处理器
在摩尔定律的作用下,单核标量处理器的性能持续提升,软件开发人员只需要写好软件,而性能就等待下次硬件的更新,在2003年之前的几十年里,这种“免费午餐”的模式一直在持续。2003年后,主要由于功耗的原因,这种“免费的午餐”已经不复存在。为了生存,各硬件生产商不得不采用各种方式以提高硬件的计算能力,以下是目前最流行的几种方式是。
1) 让处理器一个周期处理多条指令 ,这多条指令可相同可不同。如Intel Haswell处理器一个周期可执行4条整数加法指令、2条浮点乘加指令,同时访存和运算指令也可同时执行。
2) 使用向量指令 ,主要是SIMD和VLIW技术。SIMD技术将处理器一次能够处理的数据位数从字长扩大到128或256位,也就提升了计算能力。
3) 在同一个芯片中集成多个处理单元 ,根据集成方式的不同,分为多核处理器或多路处理器。多核处理器是如此的重要,以至于现在即使是手机上的嵌入式ARM处理器都已经是四核或八核。
4) 使用异构处理器,不同的架构设计的处理器具有不同的特点,如X86 处理器为延迟优化,以减少指令的执行延迟为主要设计考量(当然今天的X86 处理器设计中也有许多为吞吐量设计的影子);如NVIDIA GPU和AMD GPU则为吞吐量设计,以提高整个硬件的吞吐量为主要设计目标。
GPU加速
相比之前在游戏、视觉效果中的应用,GPU正在成为数据中心、超算中心的标配,并广泛应用于深度学习、大数据、石油化工、传媒娱乐、科学研究等行业。GPU计算正在加速着深度学习革命,作为深度学习研究技术平台领导厂商,NVIDIA将为中国的深度学习提供更多的技术平台和解决方案,并继续与中国的合作伙伴一起积极参加和推动深度学习生态链的构建。
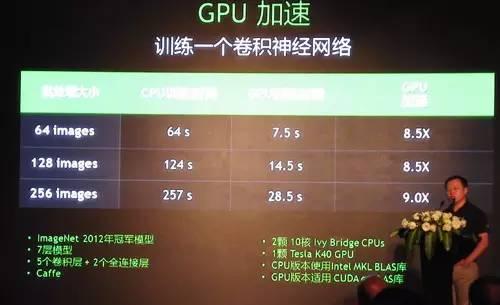
基于GPU加速的深度学习算法,百度、微软和Google的计算机视觉系统在ImageNet图像分类和识别测试中分别达到了5.98% (2015年1月数据)4.94%(2015年2月数据)、4.8%(2015年2月数据)、的错误率,接近或超过了人类识别水平——跑分竞赛虽然有针对已知数据集进行特定优化之嫌,但优化结果对工业界的实践仍然具有参考价值。
人工智能从过去基于模型的方法,变成现在基于数据、基于统计的方法,主要得益于GPU高度并行的结构、高效快速的连接能力。事实证明GPU很适合深度学习。
几乎所有深度学习的研究者都在使用GPU
熟悉深度学习的人都知道,深度学习是需要训练的,所谓的训练就是在成千上万个变量中寻找最佳值的计算。这需要通过不断的尝试实现收敛,而最终获得的数值并非是人工确定的数字,而是一种常态的公式。通过这种像素级的学习,不断总结规律,计算机就可以实现像像人一样思考。如今,几乎所有的深度学习(机器学习)研究者都在使用GPU进行相关的研究。当然,我说的是“几乎”。除了GPU之外,包括MIC和FPGA也提供了不同的解决方案。NVIDIA如何看待不同的硬件架构对深度学习的影响,又是如何评价这些技术的呢?
NVIDIA中国区解决方案架构工程总监罗华平认为:“技术发展和科技的发展,是需要不同的技术一起来参与。无论是GPU也好、FPGA也好或者是专用的神经网芯片也好,它的主要目的都是推动深度学习(机器学习)这个方向的技术发展。那么我们在初期,确实可以尝试不同的技术,来探讨哪种技术可以更好的适合这项应用。从目前来看,深度学习大量的使用,主要集中在训练方面。那么在这个领域,GPU确实是非常适合的,这也体现在所有的这些工业界的大佬如BAT、谷歌,Facebook等等,都在使用GPU在做训练。”而除了训练之外,在实际的应用方面,NVIDIA也正在结合中国地区IDC机房普遍具备的功耗、网络等特点,“考虑是否设计低功耗的GPU,来满足用户的需求”。
除了硬件方面的因素之外,英伟达中国区技术经理赖俊杰也从软件方面解答了GPU对于深度学习应用的价值。首先从深度学习应用的开发工具角度,具备CUDA支持的GPU为用户学习Caffe、Theano等研究工具提供了很好的入门平台。其实GPU不仅仅是指专注于HPC领域的Tesla,包括Geforce在内的GPU都可以支持CUDA计算,这也为初学者提供了相对更低的应用门槛。除此之外,CUDA在算法和程序设计上相比其他应用更加容易,通过NVIDIA多年的推广也积累了广泛的用户群,开发难度更小。最后则是部署环节,GPU通过PCI-e接口可以直接部署在服务器中,方便而快速。得益于硬件支持与软件编程、设计方面的优势,GPU才成为了目前应用最广泛的平台。
深度学习发展遇到瓶颈了吗?
我们之所以使用GPU加速深度学习,是因为深度学习所要计算的数据量异常庞大,用传统的计算方式需要漫长的时间。但是,如果未来深度学习的数据量有所下降,或者说我们不能提供给深度学习研究所需要的足够数据量,是否就意味着深度学习也将进入“寒冬”呢?对此,赖俊杰也提出了另外一种看法。“做深度神经网络训练需要大量模型,然后才能实现数学上的收敛。深度学习要真正接近成人的智力,它所需要的神经网络规模非常庞大,它所需要的数据量,会比我们做语言识别、图像处理要多得多。假设说,我们发现我们没有办法提供这样的数据,很有可能出现寒冬”。
不过他也补充认为——从今天看到的结果来说,其实深度学习目前还在蓬勃发展往上的阶段。比如说我们现阶段主要做得比较成熟的语音、图像方面,整个的数据量还是在不断的增多的,网络规模也在不断的变复杂。现在我没有办法预测,将来是不是会有一天数据真不够用了。
对于NVIDIA来说,深度学习是GPU计算发展的大好时机,也是继HPC之后一个全新的业务增长点。正如Pandey所提到的那样,NVIDIA将世界各地的成功经验带到中国,包括国外的成功案例、与合作伙伴的良好关系等等,帮助中国客户的快速成长。“因为现在是互联网的时代,是没有跨界的时代,大家都是同等一起的。”
GPU、FPGA 还是专用芯片?
尽管深度学习和人工智能在宣传上炙手可热,但无论从仿生的视角抑或统计学的角度,深度学习的工业应用都还是初阶,深度学习的理论基础也尚未建立和完善,在一些从业人员看来,依靠堆积计算力和数据集获得结果的方式显得过于暴力——要让机器更好地理解人的意图,就需要更多的数据和更强的计算平台,而且往往还是有监督学习——当然,现阶段我们还没有数据不足的忧虑。未来是否在理论完善之后不再依赖数据、不再依赖于给数据打标签(无监督学习)、不再需要向计算力要性能和精度?
退一步说,即便计算力仍是必需的引擎,那么是否一定就是基于GPU?我们知道,CPU和FPGA已经显示出深度学习负载上的能力,而IBM主导的SyNAPSE巨型神经网络芯片(类人脑芯片),在70毫瓦的功率上提供100万个“神经元”内核、2.56亿个“突触”内核以及4096个“神经突触”内核,甚至允许神经网络和机器学习负载超越了冯·诺依曼架构,二者的能耗和性能,都足以成为GPU潜在的挑战者。例如,科大讯飞为打造“讯飞超脑”,除了GPU,还考虑借助深度定制的人工神经网络专属芯片来打造更大规模的超算平台集群。
不过,在二者尚未产品化的今天,NVIDIA并不担忧GPU会在深度学习领域失宠。首先,NVIDIA认为,GPU作为底层平台,起到的是加速的作用,帮助深度学习的研发人员更快地训练出更大的模型,不会受到深度学习模型实现方式的影响。其次,NVIDIA表示,用户可以根据需求选择不同的平台,但深度学习研发人员需要在算法、统计方面精益求精,都需要一个生态环境的支持,GPU已经构建了CUDA、cuDNN及DIGITS等工具,支持各种主流开源框架,提供友好的界面和可视化的方式,并得到了合作伙伴的支持,例如浪潮开发了一个支持多GPU的Caffe,曙光也研发了基于PCI总线的多GPU的技术,对熟悉串行程序设计的开发者更加友好。相比之下,FPGA可编程芯片或者是人工神经网络专属芯片对于植入服务器以及编程环境、编程能力要求更高,还缺乏通用的潜力,不适合普及。













评论