FPGA重点知识13条,助你构建完整“逻辑观”之一
6、FPGA设计方法概论
本文引用地址:http://www.eepw.com.cn/article/201802/375718.htmFPGA是可编程芯片,因此FPGA的设计方法包括硬件设计和软件设计两部分。硬件包括FPGA芯片电路、存储器、输入输出接口电路以及其他设备,软件即是相应的HDL程序以及最新才流行的嵌入式C程序。硬件设计是基础,但其方法比较固定,本书将在第4节对其进行详细介绍,本节主要介绍软件的设计方法。
目前微电子技术已经发展到SOC阶段,即集成系统(Integrated System)阶段,相对于集成电路(IC)的设计思想有着革命性的变化。SOC是一个复杂的系统,它将一个完整产品的功能集成在一个芯片上,包括核心处理器、存储单元、硬件加速单元以及众多的外部设备接口等,具有设计周期长、实现成本高等特点,因此其设计方法必然是自顶向下的从系统级到功能模块的软、硬件协同设计,达到软、硬件的无缝结合。
这么庞大的工作量显然超出了单个工程师的能力,因此需要按照层次化、结构化的设计方法来实施。首先由总设计师将整个软件开发任务划分为若干个可操作的模块,并对其接口和资源进行评估,编制出相应的行为或结构模型,再将其分配给下一层的设计师。这就允许多个设计者同时设计一个硬件系统中的不同模块,并为自己所设计的模块负责;然后由上层设计师对下层模块进行功能验证。
自顶向下的设计流程从系统级设计开始,划分为若干个二级单元,然后再把各个二级单元划分为下一层次的基本单元,一直下去,直到能够使用基本模块或者IP核直接实现为止,如图1-6所示。流行的FPGA开发工具都提供了层次化管理,可以有效地梳理错综复杂的层次,能够方便地查看某一层次模块的源代码以修改错误。

图1-6 自顶向下的FPGA设计开发流程
在工程实践中,还存在软件编译时长的问题。由于大型设计包含多个复杂的功能模块,其时序收敛与仿真验证复杂度很高,为了满足时序指标的要求,往往需要反复修改源文件,再对所修改的新版本进行重新编译,直到满足要求为止。这里面存在两个问题:首先,软件编译一次需要长达数小时甚至数周的时间,这是开发所不能容忍的;其次,重新编译和布局布线后结果差异很大,会将已满足时序的电路破坏。因此必须提出一种有效提高设计性能,继承已有结果,便于团队化设计的软件工具。FPGA厂商意识到这类需求,由此开发出了相应的逻辑锁定和增量设计的软件工具。例如,Xilinx公司的解决方案就是PlanAhead。
Planahead 允许高层设计者为不同的模块划分相应FPGA芯片区域,并允许底层设计者在在所给定的区域内独立地进行设计、实现和优化,等各个模块都正确后,再进行设计整合。如果在设计整合中出现错误,单独修改即可,不会影响到其它模块。Planahead将结构化设计方法、团队化合作设计方法以及重用继承设计方法三者完美地结合在一起,有效地提高了设计效率,缩短了设计周期。
不过从其描述可以看出,新型的设计方法对系统顶层设计师有很高的要求。在设计初期,他们不仅要评估每个子模块所消耗的资源,还需要给出相应的时序关系;在设计后期,需要根据底层模块的实现情况完成相应的修订。
典型FPGA开发流程
FPGA的设计流程就是利用EDA开发软件和编程工具对FPGA芯片进行开发的过程。FPGA的开发流程一般如图1-7所示,包括电路设计、设计输入、功能仿真、综合优化、综合后仿真、实现、布线后仿真、板级仿真以及芯片编程与调试等主要步骤。
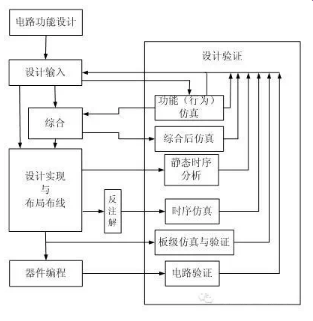
图1-7 FPGA开发的一般流程
1. 电路设计
在系统设计之前,首先要进行的是方案论证、系统设计和FPGA芯片选择等准备工作。系统工程师根据任务要求,如系统的指标和复杂度,对工作速度和芯片本身的各种资源、成本等方面进行权衡,选择合理的设计方案和合适的器件类型。一般都采用自顶向下的设计方法,把系统分成若干个基本单元,然后再把每个基本单元划分为下一层次的基本单元,一直这样做下去,直到可以直接使用EDA元件库为止。
2. 设计输入
设计输入是将所设计的系统或电路以开发软件要求的某种形式表示出来,并输入给EDA工具的过程。常用的方法有硬件描述语言(HDL)和原理图输入方法等。原理图输入方式是一种最直接的描述方式,在可编程芯片发展的早期应用比较广泛,它将所需的器件从元件库中调出来,画出原理图。这种方法虽然直观并易于仿真,但效率很低,且不易维护,不利于模块构造和重用。更主要的缺点是可移植性差,当芯片升级后,所有的原理图都需要作一定的改动。目前,在实际开发中应用最广的就是HDL语言输入法,利用文本描述设计,可以分为普通HDL和行为HDL。普通HDL有ABEL、CUR等,支持逻辑方程、真值表和状态机等表达方式,主要用于简单的小型设计。而在中大型工程中,主要使用行为HDL,其主流语言是Verilog HDL和VHDL。这两种语言都是美国电气与电子工程师协会(IEEE)的标准,其共同的突出特点有:语言与芯片工艺无关,利于自顶向下设计,便于模块的划分与移植,可移植性好,具有很强的逻辑描述和仿真功能,而且输入效率很高。
3. 功能仿真
功能仿真,也称为前仿真,是在编译之前对用户所设计的电路进行逻辑功能验证,此时的仿真没有延迟信息,仅对初步的功能进行检测。仿真前,要先利用波形编辑器和HDL等建立波形文件和测试向量(即将所关心的输入信号组合成序列),仿真结果将会生成报告文件和输出信号波形,从中便可以观察各个节点信号的变化。如果发现错误,则返回设计修改逻辑设计。常用的工具有Model Tech公司的ModelSim、Sysnopsys公司的VCS和Cadence公司的NC-Verilog以及NC-VHDL等软件。
4. 综合优化
所谓综合就是将较高级抽象层次的描述转化成较低层次的描述。综合优化根据目标与要求优化所生成的逻辑连接,使层次设计平面化,供FPGA布局布线软件进行实现。就目前的层次来看,综合优化(Synthesis)是指将设计输入编译成由与门、或门、非门、RAM、触发器等基本逻辑单元组成的逻辑连接网表,而并非真实的门级电路。真实具体的门级电路需要利用FPGA制造商的布局布线功能,根据综合后生成的标准门级结构网表来产生。为了能转换成标准的门级结构网表,HDL程序的编写必须符合特定综合器所要求的风格。由于门级结构、RTL级的HDL程序的综合是很成熟的技术,所有的综合器都可以支持到这一级别的综合。常用的综合工具有Synplicity公司的Synplify/Synplify Pro软件以及各个FPGA厂家自己推出的综合开发工具。
5. 综合后仿真
综合后仿真检查综合结果是否和原设计一致。在仿真时,把综合生成的标准延时文件反标注到综合仿真模型中去,可估计门延时带来的影响。但这一步骤不能估计线延时,因此和布线后的实际情况还有一定的差距,并不十分准确。目前的综合工具较为成熟,对于一般的设计可以省略这一步,但如果在布局布线后发现电路结构和设计意图不符,则需要回溯到综合后仿真来确认问题之所在。在功能仿真中介绍的软件工具一般都支持综合后仿真。
6. 实现与布局布线
实现是将综合生成的逻辑网表配置到具体的FPGA芯片上,布局布线是其中最重要的过程。布局将逻辑网表中的硬件原语和底层单元合理地配置到芯片内部的固有硬件结构上,并且往往需要在速度最优和面积最优之间作出选择。布线根据布局的拓扑结构,利用芯片内部的各种连线资源,合理正确地连接各个元件。目前,FPGA的结构非常复杂,特别是在有时序约束条件时,需要利用时序驱动的引擎进行布局布线。布线结束后,软件工具会自动生成报告,提供有关设计中各部分资源的使用情况。由于只有FPGA芯片生产商对芯片结构最为了解,所以布局布线必须选择芯片开发商提供的工具。
7. 实现与布局布线
时序仿真,也称为后仿真,是指将布局布线的延时信息反标注到设计网表中来检测有无时序违规(即不满足时序约束条件或器件固有的时序规则,如建立时间、保持时间等)现象。时序仿真包含的延迟信息最全,也最精确,能较好地反映芯片的实际工作情况。由于不同芯片的内部延时不一样,不同的布局布线方案也给延时带来不同的影响。因此在布局布线后,通过对系统和各个模块进行时序仿真,分析其时序关系,估计系统性能,以及检查和消除竞争冒险是非常有必要的。在功能仿真中介绍的软件工具一般都支持综合后仿真。
8. 板级仿真与验证
板级仿真主要应用于高速电路设计中,对高速系统的信号完整性、电磁干扰等特征进行分析,一般都以第三方工具进行仿真和验证。
9. 芯片编程与调试
设计的最后一步就是芯片编程与调试。芯片编程是指产生使用的数据文件(位数据流文件,Bitstream Generation),然后将编程数据下载到FPGA芯片中。其中,芯片编程需要满足一定的条件,如编程电压、编程时序和编程算法等方面。逻辑分析仪(Logic Analyzer,LA)是FPGA设计的主要调试工具,但需要引出大量的测试管脚,且LA价格昂贵。目前,主流的FPGA芯片生产商都提供了内嵌的在线逻辑分析仪(如Xilinx ISE中的ChipScope、Altera QuartusII中的SignalTapII以及SignalProb)来解决上述矛盾,它们只需要占用芯片少量的逻辑资源,具有很高的实用价值。
1.3.3 基于FPGA的SOC设计方法
基于FPGA的SOC设计理念将FPGA可编程的优点带到了SOC领域,其系统由嵌入式处理器内核、DSP单元、大容量处理器、吉比特收发器、混合逻辑、IP以及原有的设计部分组成。相应的FPGA规模大都在百万门以上,适合于许多领域,如电信、计算机等行业。
系统设计方法是SOC常用的方法学,其优势在于,可进行反复修改并对系统架构实现进行验证,??? 包括SOC集成硬件和软件组件之间的接口。不过,目前仍存在很多问题,最大的问题就是没有通用的系统描述语言和系统级综合工具。随着FPGA平台的融入,将 SOC逐步地推向了实用。SOC平台的核心部分是内嵌的处理内核,其硬件是固定的,软件则是可编程的;外围电路则由FPGA的逻辑资源组成,大都以IP 的形式提供,例如存储器接口、USB接口以及以太网MAC层接口等,用户根据自己需要在内核总线上添加,并能自己订制相应的接口IP和外围设备。
基于FPGA的典型SOC开发流程为:
1.芯片内的考虑
从设计生成开始,设计人员需要从硬件/软件协同验证的思路入手,以找出只能在系统集成阶段才会被发现的软、硬件缺陷。然后选择合适的芯片以及开发工具,在综合过程得到优化,随后进行精确的实现,以满足实际需求。由于设计规模越来越大,工作频率也到了数百兆赫兹,布局布线的延迟将变得非常重要。为了确保满足时序,需要在布局布线后进行静态时序分析,对设计进行验证。
2.板级验证
在芯片设计完毕后,需要再进行板级验证,以便在印刷电路板(PCB)上保证与最初设计功能一致。因此,PCB布局以及信号完整性测试应被纳入设计流程。由于芯片内设计所做的任何改变都将反映在下游的设计流程中,各个过程之间的数据接口和管理也必须是无误的。预计SOC系统以及所必须的额外过程将使数据的大小成指数增长,因此,管理各种数据集本身是急剧挑战性的任务
7、DCM时钟管理单元
看Xilinx的Datasheet会注意到Xilinx的FPGA没有PLL,其实DCM就是时钟管理单元。
1、DCM概述
DCM内部是DLL(Delay Lock Loop结构,对时钟偏移量的调节是通过长的延时线形成的。DCM的参数里有一个PHASESHIFT(相移),可以从0变到255。所以我们可以假设内部结构里从输入引脚clkin到输出引脚clk_1x之间应该有256根延时线(实际上,由于对不同频率的时钟都可以从0变到255,延时线的真正数目应该比这个大得多)。DCM总会把输入时钟clkin和反馈时钟CLKFB相比较,如果它们的延时差不等于所设置的PHASESHIFT,DCM就会改变在clkin和clk_1x之间的延时线数目,直到相等为止,输出和输入形成闭环,动态调整到设定值再退出。这个从不等到相等所花的时间,就是输出时钟锁定的时间,相等以后,lock_flag标识才会升高。
当DCM发现clkin和clkfb位相差不等于PHASESHIFT的时候,就去调节clk_1x和clkin之间延时,所以如果clk_1x和clkfb不相关的话,那就永远也不能锁定了。
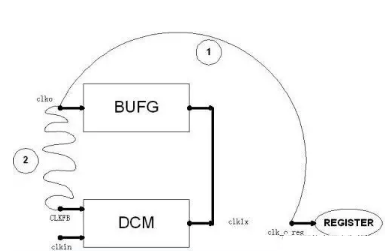
图一、DCM和BUFG配合使用示意图
2、如何使用DCM
DCM一般和BUFG配合使用,要加上BUFG,应该是为了增强时钟的驱动能力。DCM的一般使用方法是,将其输出clk_1x接在BUFG的输入引脚上,BUFG的输出引脚反馈回来接在DCM的反馈时钟脚CLKFB上。另外,在FPGA里,只有BUFG的输出引脚接在时钟网络上,所以一般来说你可以不使用DCM,但你一定会使用BUFG。有些兄弟总喜欢直接将外部输入的时钟驱动内部的寄存器,其实这个时候虽然你没有明显地例化BUFG,但工具会自动给你加上的。
3、使用DCM可以消除时钟skew
使用DCM可以消除时钟skew。这个东西一直是我以前所没有想清楚的,时钟从DCM输出开始走线到寄存器,这段skew的时间总是存在的,为什么用DCM就可以消除呢?直到有一天忽然豁然开朗,才明白其原委。对高手来说,也许是极为easy的事情,但也许有些朋友并不一定了解,所以写出来和大家共享。
为说明方便起见,我们将BUFG的输出引脚叫做clk_o,从clk_o走全局时钟布线到寄存器时叫做clk_o_reg,从clk_o走线到DCM的反馈引脚CLKFB上时叫clkfb,如图所示。实际上clk_o, clk_o_reg, clkfb全部是用导线连在一起的。
所谓时钟skew,指的就是clk_o到clk_o_reg之间的延时。如果打开FPGA_Editor看底层的结构,就可以发现虽然DCM和BUFG离得很近,但是从clk_o到clkfb却绕了很长一段才走回来,从而导致从clk_o到clk_o_reg和clkfb的延时大致相等。
总之就是clk_o_reg和clkfb的相位应该相等。所以当DCM调节clkin和clkfb的相位相等时,实际上就调节了clkin和clk_o_reg相等。而至于clk_1x和clk_o的相位必然是超前于clkin, clkfb, clk_o_reg的,而clk_1x和clk_o之间的延时就很明显,就是经过那个BUFG的延迟时间。
4、对时钟skew的进一步讨论
最后,说一说时钟skew的概念。时钟skew实际上指的是时钟驱动不同的寄存器时,由于寄存器之间可能会隔得比较远,所以时钟到达不同的寄存器的时间可能会不一样,这个时间差称为时钟skew。这种时钟skew可以通过时钟树来解决,也就是使时钟布线形成一种树状结构,使得时钟到每一个寄存器的距离是一样的。很多FPGA芯片里就布了这样的时钟树结构。也就是说,在这种芯片里,时钟skew基本上是不存在的。
说到这里,似乎有了一个矛盾,既然时钟skew的问题用时钟树就解决了,那么为什么还需要DCM+BUFG来解决这个问题?另外,既然时钟skew指的是时钟驱动不同寄存器之间的延时,那么上面所说的clk_o到clk_o_reg岂非不能称为时钟skew?
先说后一个问题。在一块FPGA内部,时钟skew问题确实已经被FPGA的时钟方案树解决,在这个前提下clk_o到clk_o_reg充其量只能叫做时钟延时,而不能称之为时钟skew。可惜的是FPGA的设计不可能永远只在内部做事情,它必然和外部交换数据。例如从外部传过来一个32位的数据以及随路时钟,数据和随路时钟之间满足建立保持时间关系(Setup Hold time),你如何将这32位的数据接收进来?如果你不使用DCM,直接将clkin接在BUFG的输入引脚上,那么从你的clk_o_reg就必然和clkin之间有个延时,那么你的clk_o_reg还能保持和进来的数据之间的建立保持关系吗?显然不能。相反,如果你采用了DCM,接上反馈时钟,那么clk_o_reg和clkin同相,就可以利用它去锁存进来的数据。可见,DCM+BUFG的方案就是为了解决这个问题。而这个时候clk_o到clk_o_reg的延时,我们可以看到做内部寄存器和其他芯片传过来的数据之间的时钟skew。
由此,我们可以得出一个推论,从晶振出来的时钟作为FPGA的系统时钟时,我们可以不经过DCM,而直接接到BUFG上就可以,因为我们并不在意从clkin到clk_o_reg的这段延时。












评论