FPGA重点知识13条,助你构建完整“逻辑观”之一
一.基于乘积项(Product-Term)的PLD结构
采用这种结构的PLD芯片有:Altera的MAX7000,MAX3000系列(EEPROM工艺),Xilinx的XC9500系列(Flash工艺)和Lattice,Cypress的大部分产品(EEPROM工艺)
我们先看一下这种PLD的总体结构(以MAX7000为例,其他型号的结构与此都非常相似):
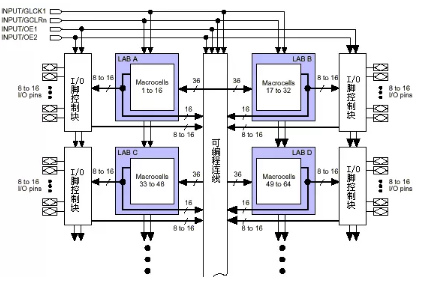
图1 基于乘积项的PLD内部结构
这种PLD可分为三块结构:宏单元(Marocell),可编程连线 (PIA)和I/O控制块。 宏单元是PLD的基本结构,由它来实现基本的逻辑功能。图1中兰色部分是多个宏单元的集合(因为宏单元较多,没有一一画出)。可编程连线负责信号传递,连 接所有的宏单元。I/O控制块负责输入输出的电气特性控制,比如可以设定集电极开路输出,摆率控制,三态输出等。 图1 左上的INPUT/GCLK1,
INPUT/GCLRn,INPUT/OE1,INPUT/OE2 是全局时钟,清零和输出使能信号,这几个信号有专用连线与PLD中每个宏单元相连,信号到每个宏单元的延时相同并且延时最短。
宏单元的具体结构见下图:
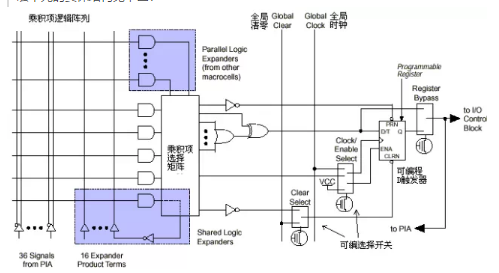
图2 宏单元结构
左侧是乘积项阵列,实际就是一个与或阵列,每一个交叉点都是一个可编程 熔丝,如果导通就是实现“与”逻辑。后面的乘积项选择矩阵是一个“或”阵列。两者一起完成组合逻辑。图右侧是一个可编程D触发器,它的时钟,清零输入都可 以编程选择,可以使用专用的全局清零和全局时钟,也可以使用内部逻辑(乘积项阵列)产生的时钟和清零。如果不需要触发器,也可以将此触发器旁路,信号直接 输给PIA或输出到I/O脚。
二.乘积项结构PLD的逻辑实现原理
下面我们以一个简单的电路为例,具体说明PLD是如何利用以上结构实现逻辑的,电路如下图:
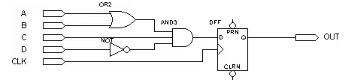
图3
假设组合逻辑的输出(AND3的输出)为f,则f=(A+B)*C*(!D)=A*C*!D + B*C*!D ( 我们以!D表示D的“非”)
PLD将以下面的方式来实现组合逻辑f:
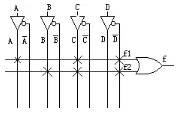
图4
A,B,C,D由PLD芯片的管脚输入后进入可编程连线阵列 (PIA),在内部会产生A,A反,B,B反,C,C反,D,D反8个输出。图中每一个叉表示相连(可编程熔丝导通),所以得到:f= f1 + f2 = (A*C*!D) +
(B*C*!D) 。这样组合逻辑就实现了。 图3电路中D触发器的实现比较简单,直接利用宏单元中的可编程D触发器来实现。时钟信号CLK由I/O脚输入后进入芯片内部的全局时钟专用通道,直接连接 到可编程触发器的时钟端。可编程触发器的输出与I/O脚相连,把结果输出到芯片管脚。这样PLD就完成了图3所示电路的功能。(以上这些步骤都是由软件自 动完成的,不需要人为干预)
图3的电路是一个很简单的例子,只需要一个宏单元就可以完成。但对于一个复杂的电路,一个宏单元是不能实现的,这时就需要通过并联扩展项和共享扩展项将多个宏单元相连,宏单元的输出也可以连接到可编程连线阵列,再做为另一个宏单元的输入。这样PLD就可以实现更复杂逻辑。
这种基于乘积项的PLD基本都是由EEPROM和Flash工艺制造的,一上电就可以工作,无需其他芯片配合。
PGA的基本工作原理
FPGA是在PAL、GAL、EPLD、CPLD等可编程器件的基础上进一步发展的产物。它是作为ASIC领域中的一种半定制电路而出现的,即解决了定制电路的不足,又克服了原有可编程器件门电路有限的缺点。
由于FPGA需要被反复烧写,它实现组合逻辑的基本结构不可能像ASIC那样通过固定的与非门来完成,而只能采用一种易于反复配置的结构。查找表可以很好地满足这一要求,目前主流FPGA都采用了基于SRAM工艺的查找表结构,也有一些军品和宇航级FPGA采用Flash或者熔丝与反熔丝工艺的查找表结构。通过烧写文件改变查找表内容的方法来实现对FPGA的重复配置。
根据数字电路的基本知识可以知道,对于一个n输入的逻辑运算,不管是与或非运算还是异或运算等等,最多只可能存在2n种结果。所以如果事先将相应的结果存放于一个存贮单元,就相当于实现了与非门电路的功能。FPGA的原理也是如此,它通过烧写文件去配置查找表的内容,从而在相同的电路情况下实现了不同的逻辑功能。
查找表的原理与结构
查找表(Look-Up-Table)简称为LUT,LUT本质上就是一个RAM。目前FPGA中多使用4输入的LUT,所以每一个LUT可以看成一个有4位地址线的的RAM。当用户通过原理图或HDL语言描述了一个逻辑电路以后,
PLD/FPGA开发软件会自动计算逻辑电路的所有可能结果,并把真值表(即结果)事先写入RAM,这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。
下面给出一个四输入与非门电路的例子来说明LUT实现逻辑功能的原理。
表给出一个使用LUT实现四输入与门电路的真值表。
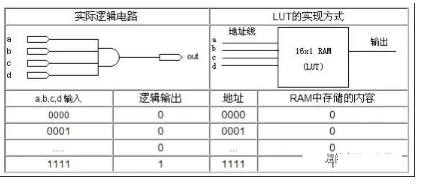
表 输入与门的真值表
从中可以看到,LUT具有和逻辑电路相同的功能。实际上,LUT具有更快的执行速度和更大的规模。
3.1.2查找表结构的FPGA逻辑实现原理
我们还是以这个电路的为例:
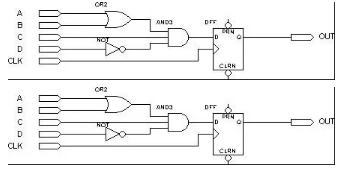
图 四输入与门电路图
A,B,C,D由FPGA芯片的管脚输入后进入可编程连线,然后作为地址线连到到LUT,LUT中已经事先写入了所有可能的逻辑结果,通过地址查找到相应的数据然后输出,这样组合逻辑就实现了。该电路中D触发器是直接利用LUT后面D触发器来实现。时钟信号CLK由I/O脚输入后进入芯片内部的时钟专用通道,直接连接到触发器的时钟端。触发器的输出与I/O脚相连,把结果输出到芯片管脚。这样PLD就完成了图所示电路的功能。(以上这些步骤都是由软件自动完成的,不需要人为干预)
这个电路是一个很简单的例子,只需要一个LUT加上一个触发器就可以完成。对于一个LUT无法完成的的电路,就需要通过进位逻辑将多个单元相连,这样FPGA就可以实现复杂的逻辑。
因为基于LUT的FPGA具有很高的集成度,其器件密度从数万门到数千万门不等,可以完成极其复杂的时序与逻辑组合逻辑电路功能,所以适用于高速、高密度的高端数字逻辑电路设计领域。其组成部分主要有可编程输入/输出单元、基本可编程逻辑单元、内嵌SRAM、丰富的布线资源、底层嵌入功能单元、内嵌专用单元等,主要设计和生产厂家有Xilinx、Altera、Lattice、Actel、Atmel和QuickLogic等公司,其中最大的是Xilinx、Altera、Lattice三家。
4、比较Xilinx和Altera
要比较Xilinx和Altera的FPGA,就要清楚两个大厂FPGA的结构,由于各自设计的不同,两家的FPGA结构各不相同,参数也各不相同,但可以统一到LUT(Look-Up-Table)查找表上。
下图就是A家的Cyclone IV系列片子的参数:
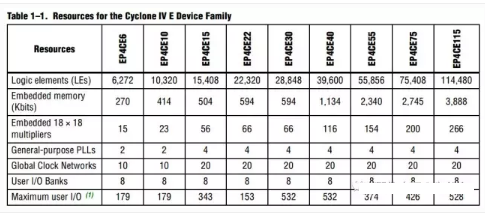
Altera Cyclone IV 系列资源比较
可以看到,A家的片子,用的是LE这个术语。
而下图是X家的Spartan-6 片子资料:
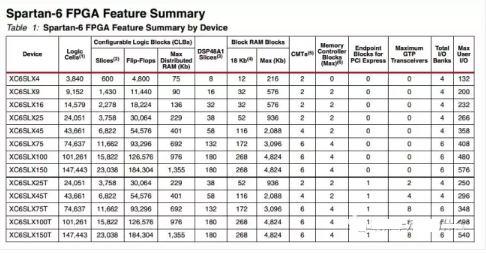
Xilinx Spartan-6 系列资源比较
X家用的是CLB这个术语作为基本单元。
再看看两家的基本单元有何不同:
A家的LE如下图:
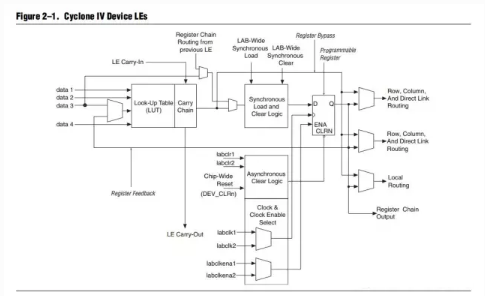
Cyclone LE 结构
就是一个4输入LUT+FF构成
而X家的CLB如下:
xilinx CLB 结构
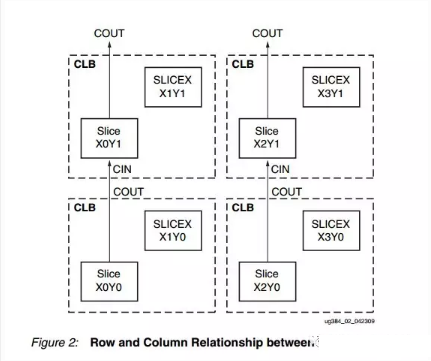
一个CLB由2个SLICE构成,一个SLICE含有4个6输入LUT,所以LUT=8*CLB。
Xilinx CLB 包含的 Slices LUT FF

这样的话,可以较比一下。EP4CE6基本就和XC6SLX9一个级别。。。。当然A家的片子是4输入LUT远比不上X家的6输入LUT。而X家的S-6片子,一个Slice内部有4个lut,8个FF。简而言之,一个Slice=四个LE。要注意的是A家C5以下的片子是4输入LUT而X家的是6输入LUT,差别也较大。如果不考虑FF,那么一个X家的slice=4个A家的LE。例如XC6SLX16含有2278个slices=EP4CE10(9000LE)的样子。当然,S-6的FF多一倍,达到了18224个。
在Virtex-5中(我们的设计大部分是Virtex,V5V6V7),一个Slice包含了4个LUT和4个FF。所以单纯从逻辑资源来看,S-6一个Slice比V-5的Slice强。当然V5的GTPGTX等等还有IO数量是S-6赶不上的。当然,A家的Cyclone V系列的片子,内部和前几代完全不同,采用了从高端的Stratix系列下放的技术.
5、分布式RAM和Block ram
以下分析基于xilinx 7系列
CLB是xilinx基本逻辑单元,每个CLB包含两个slices,每个slices由4个(A,B,C,D)6输入LUT和8个寄存器组成。
同一CLB中的两片slices没有直接的线路连接,分属于两个不同的列。每列拥有独立的快速进位链资源。
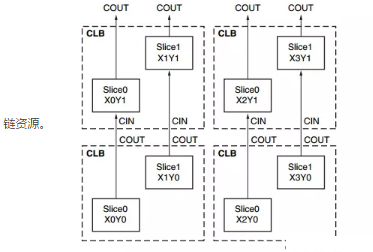
slice分为两种类型 SLICEL, SLICEM . SLICEL可用于产生逻辑,算术,ROM。 SLICEM除以上作用外还可配置成分布式RAM或32位的移位寄存器。每个CLB可包含两个SLICEL或者一个SLICEL与一个SLICEM.
7系列的LUT包含6个输入 A1 -A6 , 两个输出 O5 , O6 .
可配置成6输入查找表,O6此时作为输出。或者两个5输入的查找表,A1-A5作为输入 A6拉高,O5,O6作为输出。
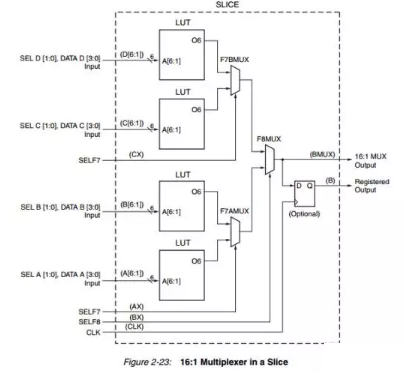
一个LUT包含6个输入,逻辑容量为2^6bit,为实现7输入逻辑需要2^7容量,对于更多输入也一样。每个SLICES有4个LUT,256bit容量能够实现最多8bit输入的逻辑。为了实现此功能,每个SLICES还包括3个MUX(多路选择器)
F7AMUX 用于产生7输入的逻辑功能,用于连接A,B两个LUT
F7BMUX 用于产生7输入的逻辑功能, 用于连接C,D两个LUT
F8MUX 用于产生8输入的逻辑功能, 用于连接4个LUT
对于大于8输入的逻辑需要使用多个SLICES, 会增加逻辑实现的延时。
一个SLICES中的4个寄存器可以连接LUT或者MUX的输出,或者被直接旁路不连接任何逻辑资源。寄存器的置位/复位端为高电平有效。只有CLK端能被设置为两个极性,其他输入若要改变电平需要插入逻辑资源。例如低电平复位需要额外的逻辑资源将rst端输入取反。但设为上升/下降沿触发寄存器不会带来额外消耗。
分布式RAM
SLICEM可以配置成分布式RAM,一个SLICEM可以配置成以下容量的RAM
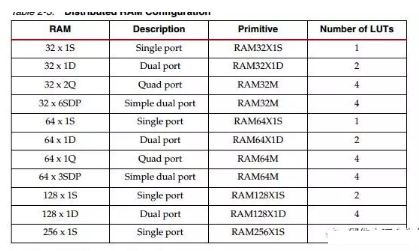
多bit的情况需要增加相应倍数的LUT进行并联。
分布式RAM和 BLOCK RAM的选择遵循以下方法:
1. 小于或等于64bit容量的的都用分布式实现
2. 深度在64~128之间的,若无额外的block可用分布式RAM。要求异步读取就使用分布式RAM。数据宽度大于16时用block ram。
3. 分布式RAM有比block ram更好的时序性能。 分布式RAM在逻辑资源CLB中。而BLOCK RAM则在专门的存储器列中,会产生较大的布线延迟,布局也受制约。
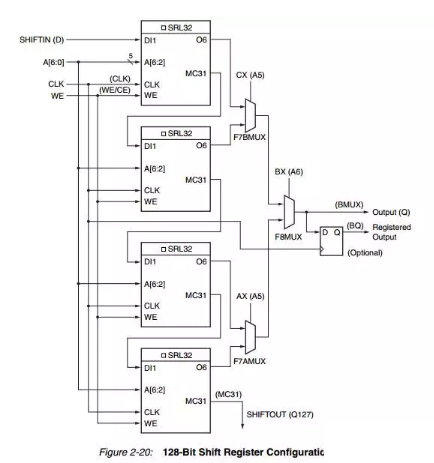
移位寄存器(SLICEM)
SLICEM中的LUT能在不使用触发器的情况下设置成32bit的移位寄存器,4个LUT可级联成128bit的移位寄存器。并且能够进行SLICEM间的级联形成更大规模的移位寄存器。
MUX
一个LUT可配置成4:1MUX.
两个LUT可配置成最多8:1 MUX
四个LUT可配置成16个MUX
同样可以通过连接多个SLICES达成更大规模设计,但是由于SLICE没有直接连线,需要使用布线资源,会增加较大延迟。
进位链
每个SLICE有4bit的进位链。每bit都由一个进位MUX(MUXCY)和一个异或门组成,可在实现加法/减法器时生成进位逻辑。该MUXCY与XOR也可用于产生一般逻辑。












评论