基于特征选择改进LR-Bagging算法的电力欠费风险居民客户预测
作者 吴漾 朱州 贵州电网有限责任公司信息中心(贵州 贵阳 550003)
本文引用地址:http://www.eepw.com.cn/article/201703/345948.htm吴漾(1984-),男,硕士,工程师,研究方向:电网信息化数据管理与数据分析管理;朱州,男,高级工程师,博士,研究方向:电网信息化建设与数据分析管理。
摘要:本文从电力欠费风险预测的角度出发,提出了一种基于特征选择改进的LR-Bagging(即以逻辑回归为基分类器的Bagging集成学习)算法,其精髓在于每一个训练的LR基分类器的记录和字段均通过随机抽样得到。且算法的终止迭代准则由AUC统计量的变化率决定。该改进算法充分考虑了LR的强泛化能力、Bagging的高精确度,以及特征选择带来的LR基分类器的多样性、弱化的多重共线性与“过拟合”度,效果优于单一LR模型。且最终的实验表明,该改进算法得到的电力欠费居民客户风险预测模型的准确性与有效性得到提升。
引言
我国电力体制的深化改革为电力行业引入了市场机制[1],在有效实现电力资源优化配置,提高电力资源生产和传输效率的同时,也带给电力企业更大的市场风险,风险的切实防范和规避对电力企业的重要性不言而喻。由于客户欠费而产生的电费回收风险一直是电力营销中存在的重大风险之一。
首先,国内学术界专业人士对于该问题的研究起步较晚[3],主要集中于对电费回收风险的现状、影响因素、评价、有效性措施等内容的理论研究,缺乏以现实数据为基础量化模型支撑[3-4];虽然也有许多文献通过对电力客户信用等级建模对其欠费风险进行预测[5],但模型不够直接;随着大数据挖掘行业的蓬勃发展,近几年出现了基于逻辑回归、决策树的数据挖掘算法的电力客户欠费违约概率预测模型[6-7],但前者选取特征均为二分类变量,适用性较低;后者选择的模型变量虽较为多样性,但模型的预测结果差强人意。而本文将借助电力客户属性数据和行为特征数据,尽可能挖掘每一个变量与欠费风险的相关信息,建立一个更为准确、使用范围更广的客户欠费风险预测模型。
其次,如今关于LR的文章或者关于Bagging集成学习的文章有很多,但是基于LR分类器的Bagging算法的应用相对较少,通过特征选择对基于LR分类器Bagging算法做出改进的相关文献基本没有。简单来说,本文算法为多个不同的LR分类器的集合,其核心在于每一个训练的LR基分类器的样本和特征均通过bootstrap技术得到。充分考虑了LR的强泛化能力、Bagging的高精确度,以及特征选择带来的LR基分类器的多样性,使得该算法在精度、实用性上优于单一算法,后文的应用恰好证明了这一点。鉴于该算法的这一优越性,可尝试将其应用于其他领域的分类挖掘问题。
本研究的意义体现在两个方面:一是对于电力欠费客户风险预测这一模块的进一步研究;二是基于特征选择的以LR为基分类器的Bagging算法的改进的借鉴和推广价值。
1 基于LR分类器的Bagging算法的改进

1.1 LR模型及其基本理论
逻辑回归(LogisticRegression,LR)模型是一种分类评定模型,是离散选择法模型之一。它主要是用于对受多因素影响的定性变量的概率预测,并根据预测的概率对目标变量进行分类。逻辑回归可分为二项逻辑回归和多项逻辑回归,类别的差异取决于目标变量类别个数的多少。目前,LR模型已经广泛应用于社会学、生物统计学、临床、数量心理学、市场营销等统计实证分析中,且以目标变量为二分类变量为主。
1.1.1 Logistic函数
假设因变量只有1-0(例如“是”和“否”,“发生”和“不发生”)两种取值,记为1和0。假设在p个独立自变量 作用下,y取1的概率是
作用下,y取1的概率是 ,取0的概率是1-P,则取1和取0的概率之比为
,取0的概率是1-P,则取1和取0的概率之比为 ,称为事件的优势比(odds),表示事件发生的概率相对于不发生的概率的强度。对odds取自然对数可得Logistic函数为:
,称为事件的优势比(odds),表示事件发生的概率相对于不发生的概率的强度。对odds取自然对数可得Logistic函数为:
 (1)
(1)
Logistic函数曲线如图1所示。
1.1.2 LR模型
LR模型可以探究由于自变量的变化所能导致的因变量决策(选择)的变化,因变量决策(选择)的变化意味着Logistic函数的变化。LR的基本形式为:

因此有:


1.1.4 LR模型的优势与不足
LR模型具有很强的实用性,对比其他的分类判别模型,LR具有以下两点优势:
(1)泛化能力较好,精度较高
所谓泛化能力,是指机器学习算法对新鲜样本的适应能力。由于LR模型的自变量多为取值范围不设限的连续变量,该模型不仅可以在样本内进行预测,还可以对样本外的数据进行预测,泛化能力较好,而且精度较高。
(2)能精确控制阈值,调整分类类别
LR模型的求解结果是一个介于0和1间的概率值。这使分类结果的多样性成为了可能。正常情况下,每一次阈值的调整都会产生不同的分类结果,便于对预测结果进行比较和检验,克服了其他分类算法分类数量无法改变的局限。
当然,LR作为回归模型的特殊形式,也需要满足经典回归模型的基本假设,违背这些假设显然会影响模型的分类效果,多重共线问题就是目前面临较多的问题。同时,逻辑回归的性能受特征空间的影响很大,也不能很好地处理大量多类特征或变量,这便是LR分类器的缺点所在。

2.1 集成学习
集成学习[8]是一种机器学习范式,它的基本思想是把多个学习器(通常是同质的)集成起来,使用多个模型(解决方案)来解决同一个问题。因其个体学习器的高精度和个误差均分布于不同的输入空间,从而能达到显著地提高学习系统的泛化能力的效果。


Breiman同时指出,要使得Bagging有效,基本学习器的学习算法必须是不稳定的,也就是说对训练数据敏感,且基本分类器的学习算法对训练数据越敏感,Bagging的效果越好。另外由于Bagging算法本身的特点,使得Bagging算法非常适合用来并行训练多个基本分类器,这也是Bagging算法的一大优势[8]。
2.3 本文算法描述
前文指出,一方面,学习器的稳定性,即对训练数据的敏感性,很大程度上影响Bagging算法的效果,其中原因在于差异性小的数据对稳定性较强的学习器无法很好产生作用,这将影响到基学习模型的多样性,Bagging算法提高精确度的能力也将大大减弱,而LR模型的不稳定性能不突出;另一方面,LR对大特征空间的解释效果并不理想,且越多的变量特征也将加大变量间多重共线的可能性,LR模型的显著性无法得到保障。
由于上述两点原因,本文提出了一种基于特征选择的LR-Bagging(基分类器为LR的Bagging算法)的改进算法。该算法的精髓在于对每一个LR进行训练的特征变量需要经过有放回的随机抽样产生。如此改进的目的在于通过减少或改变变量提高基LR分类器的多样性,减少变量间的多重共线性与过拟合问题,同时还能较好保留LR与Bagging集成学习的优点。

AUC(Area Under Curve)被定义为ROC曲线下的面积,它的取值范围介于0.5到1之间,是比较分类器间分类效果优劣的评价标准。AUC越大,我们认为模型的分类效果越好。一般情况下,,随着循环次数的增加,模型提取的数据信息量也会不断增加,最后达到峰值,所以我们通常可以认为组合模型的效果趋于先不断加强后保持稳定的过程。因此,我们把迭代的停止条件的设置为是合理的。






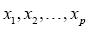


评论