用基于CAM的DDR控制器架构实现DDR DRAM效率最大化
多年来,对芯片外部DDR SDRAM的访问已经成为SoC设计的一个不可分割的部分。当考虑DDR IP时,SoC设计师面临的一个选择是自己做IP还是从第三方IP供应商那里获得授权。
本文引用地址:http://www.eepw.com.cn/article/201610/307440.htm正如大多数IP一样,选择DDR接口IP的标准包括面积、功耗、功能和性能。随着更多的功能和应用被集成到SoC之中,CPU所需的处理能力和其它处理功能也必须相应地提高。与处理能力提高携手并进的通常是DDR带宽需求的提高,因此性能便成为了选择DDR IP的最重要标准。
起初,DDR SDRAM被设计成目前架构的一个主要原因是为了满足我们熟知的DDR SDRAM体系结构要求。它的主要目的就是创造一种小尺寸和引脚数量少的低成本片外存储器。SDRAM的存储单元非常小,它们由单通道栅极晶体管和储存电荷的电容构成。该接口通过共享相同的、用于读写的总线和分清行列的地址引脚来降低使用的引脚数量。虽然实现低成本这一主要目标得以实现,但它导致了一种不能以高效的方式进行随机寻址的芯片外存储器架构。为适应数据写入或从SDRAM读出的低效率,SoC需要使用一个控制器来管理对DDR SDRAM的访问。当今绝大多数存储器控制器都会考虑DDR SDRAM的低效性,并且试图重组到DDR SDRAM的命令,以将无效指令数量减至最少,并提高SoC访问SDRAM的效率(带宽)。
DDR SDRAM控制器传统上通过使用一个先入先出(FIFO)架构来评估流量请求队列(通常被称为一种前瞻性)来对流量重新排序。后来,随着技术进步引入了一种新的DDR控制器,它充分利用了一种内容可寻址存储器(CAM)前瞻性架构来对流量重新排序。
【分页导航】
第1页:背景介绍
第2页:DDR SDRAM访问特性和效率测试
第3页:DDR控制器效率对比
DDR SDRAM访问特性
DDR SDRAM芯片内包含多个独立的存储体(Banks)—典型的是8个存储体,如图1所示。每个存储体可以处于闲置、活跃或者依次充电的状态。通过一个“激活”指令可以“打开”一个闲置bank,并将规定行的数据读进一个感知放大器阵列中,它存储了所有读写操作期间的数据。
EDA_AN_01.jpg onload=thumbImg(this) alt= />
这个过程需要一些时间,并导致在从任何给定行中读取数据前就增加了开销。访问存储于读出放大器中的数据的速度会更快。此外,每条读/写命令在行内使用一个列地址来访问数据。
若存储控制器想要访问一个不同的行,它必须首先让该存储体的读出放大器返回到一个闲置状态,准备去读出下一行。这被称作“预充电”命令,或者“关闭”这一行。在该存储体完全变成闲置状态以便于在可以接受另一个激活指令之前,有一段必须清空的最短时间。
访问时间从最长到最短,分为如下的层级:
1,在另一不同的行被打开时,访问一行(要求处于打开的行先被关闭,另一个新的行才被打开)
2,访问一个处于关闭的行(要求该行被打开)
3,访问当前被打开的行除了访问时间之外,存储控制器的实现还有许多其它时序考虑因素(如:刷新、断电和初始化)。例如:将存储子系统从读状态转变为写状态,或者从写状态转变为读状态,会造成与接口总线转换方向相关的延迟。如果发生次数太多,就会降低数据从SDRAM移进和移出的整体效率。
测量效率
数据传输效率是通过一个存储器接口的可用数据传输带宽数值的一种度量。效率通常由一种特定的存储器接口实现方式的理论最大存储器传输带宽的一个百分比来表示。
例如,如果一个DDR3SDRAM是八位宽度,工作在800MHz时钟,那么理论上的最大传输速率为1600Mbps。如果该SDRAM实现的平均传输速率为800Mbps,那么该存储控制器的效率为50%。各种不同的存储控制器实现的效率通常为25%~90%。显而易见,一个低效的设计实现会严重影响关键系统特性,增加整体解决方案的成本。
在某些情况下,高数据传输效率难以实现,这是因为SoC中的访问请求者的访问模式是随机的。因为打开的行具有更快的访问时间,如果存储器请求多数时间在一个打开的行上工作,那么在这些访问期间就可以实现理论上的最大带宽。如果存储器访问是凌乱分散的,那么可能很难再次访问到相同的行,导致了去访问不同的行更长的访问时间,因此缩短了平均访问时间,降低了整体的数据传输速率。很显然,如果一个存储控制器可以评估流量模式和发现一种以更高效的方式给操作排序的可能性—如集合在一起成组地访问相同的存储行,而不是仅仅依照存储访问的请求顺序来执行它们,或者为高优先级数据提供快速访问—那么就可以减小低效率流量模式所带来的影响。一个能够并特别擅长管理随机流量的DDR存储控制器可以显著地提高效率。
【分页导航】
第1页:背景介绍
第2页:DDR SDRAM访问特性和效率测试
第3页:DDR控制器效率对比
DDR控制器效率对比
图2展示了由一个基于FIFO的DDR控制器的效率分析,数据结果来自于市场基准研究。这些实例模式代表了三种不同的流量类型,分别被标记为模式_80_20、模式_50_50和模式_20_80。标记的命名代表了模式的类型:标签中第一个数字代表连续或递增访问的百分比,第二个数字代表随机访问的百分比。随着随机部分的百分比从20%增长到80%,效率则如预期一样降低。模式中的连续部分为针对一个打开页的流量请求,这是设计的最佳情况,提供了最高的效率。流量的随机部分抑或是对一个关闭页的访问,或者是对一个带有不同打开页的存储体的访问请求。通过深入分析,模式_20_80的效率大概为55%,模式_50_50的效率大概为60%,而模式_80_20的效率可以达到75%。

图3说明了一个基于CAM的DDR控制器在执行这三种相同模式时产生的效率结果。带有32个条目的CAM的效率大于或者等于基于FIFO的DDR控制器的效率结果,而拥有64个条目的CAM的效率结果则明显更高。带有64个条目的基于CAM的DDR控制器在模式_80_20下效率结果为接近98%,模式_50_50为80%,模式_20_80为65%。这表明了相对于基于FIFO的控制器,基于CAM的架构在效率上实现了显著的提高—这意味着提高了带宽。
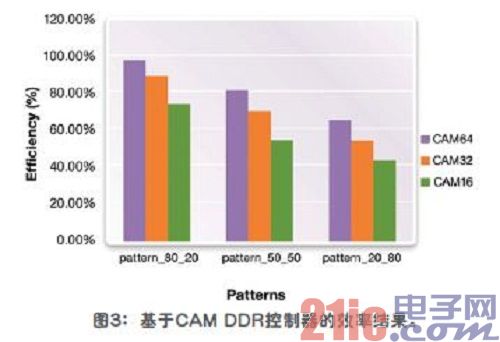
由于DRAM的存储体(Bank)架构,设计师过去不得不很困难地分配到DDR SDRAM的存储空间访问,以使SoC循环读写8个可用的存储体。在多种模式下循环访问存储体可使控制器工作在存储体架构范围内,以提供合理的效率。然而,一些SoC系统并没有在不同存储体和DDR控制器之间定期发送循环数据流,而这正是基于CAM架构的控制器足以胜任的。基于CAM的架构可以调整整个指令序列,甚至为了更高的效率可以将最随机的流量模式重新排序。
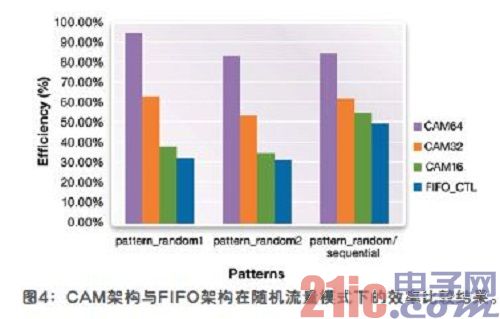
随机模式1和随机模式2是两种不同种类的非常随机的数据流,但它们不在各存储体间循环。随机/连续模式将随机模式与相似的连续模式结合在一起,并应用到那些在以上例子讨论过的情况中。在图4中,FIFO_CTL的效率在随机/连续模式下有所提高,但是在图中可以看到基于CAM的控制器的所有模式得到的效率数值均比FIFO_CTL的效率高出很多。




评论