嵌入式开发技巧:利用编程技术发挥多内核架构优势
在整个嵌入式领域,“更多内核”已经成为设计趋势,一些硬件架构可以提供数十个内核,有些架构中的内核甚至多达上千个。然而,多内核设计在软件方面仍存在诸多挑战,在不同架构间进行应用程序的移植并不容易。
本文引用地址:http://www.eepw.com.cn/article/201609/303646.htm在低端嵌入式领域,单内核解决方案仍然存在。通过采用速度更快或带宽更宽的处理器仍有可能提升系统的功能和性能曲线。在高端领域,多内核是必然的发展方向。这正是双精度浮点算法经常出现并在超级计算机中长盛不衰的原因。事实上,台式机和机架安装系统(比如Nvidia的产品)正在将这种处理能力普及化。
在讨论软件和多内核架构时经常提及的另一个问题是虚拟化。并不是所有多内核平台都支持虚拟化,但虚拟化确实能带来更好的机会。虽然虚拟化使得硬件设计面临更多的挑战,但它通常能简化软件和应用管理。
SMP服务器
Xeon Nehalem-EX是Intel公司提供的顶级8内核对称多处理(SMP)平台。像8芯片、64内核系统这样的多芯片解决方案,通常采用高速 QuickPath点到点互连技术将处理器和外设控制器链接在一起(图1)。使用过带HyperTransport链路的AMD Opteron处理器的工程师,对这种架构非常熟悉。在这两种情况下,最简单的配置是单个处理器通过单条高速链路链接到单个外设控制器。
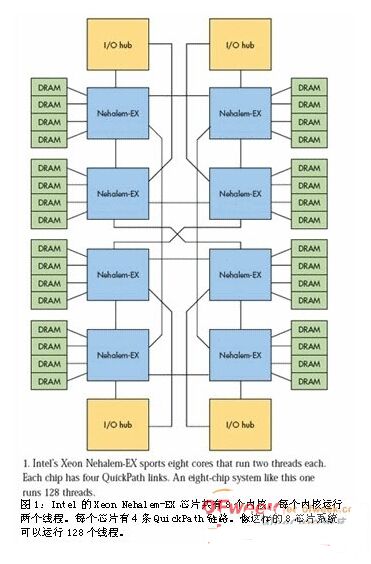
除了提供分布式内存子系统外,Intel和AMD还实现了连贯缓冲非统一内存寻址(ccNUMA)技术。每个处理器芯片都有自己的内存控制器以及一级、二级和三级缓存。任何芯片都可以使用高速链路访问其它任何芯片中的内存。当然,离请求者越远的数据访问时间越长。这些高速链路也被用于消费设备,但只有到 I/O中心的单条链路是必需的。换句话说,在共享内存访问时服务器将在处理器芯片间产生显着的流量。芯片至芯片流量和缓存管理是高效操作的关键。
HT Assist是AMD最新推出的Istanbul Opteron处理器的一个重要功能,它通过优化内存请求和响应过程来尽量减少相关事务处理的数量,进而释放出大量带宽用于处理其它业务(图2)。HT Assist实际上会跟踪数据在内核和缓存间的移动,允许请求得到具有所需数据的最近内核的服务。
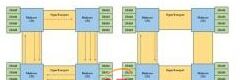
最坏的情况是拥有片外存储器空间的芯片必须从片外存储器访问数据;最好的情况是发现数据正好位于运行着需要这个数据的线程的芯片缓存中;中间情况是内核从相邻芯片的缓存中获取数据。使用虚拟化和缓存技术后系统将变得更加复杂,并导致数据延时更加难以确定。这在确定性嵌入式应用中可能是个问题,但在大多数服务器应用中问题并不十分明显,因为这种情况下的速度比精细的确定性更加重要。
编程人员现在都在使用这些平台,因为它们能大大简化编程任务。同样,应用程序可以使用越来越多的内核,前提是应用程序可高效地利用充足的线程。高效使用多内核系统并不像表面看起来那么容易。缓存大小和应用程序工作数据集中的参考位置会影响特定算法的运行效果。
AMP应用处理器
对称处理(SMP)架构对许多嵌入式应用来说非常有用,但非对称多处理(AMP)也有它的用武之地。AMP配置在很多地方都可以看到,从TI的OMAP(开放多媒体应用平台)到飞思卡尔的P4080 QorIQ都有AMP的身影(图3)。
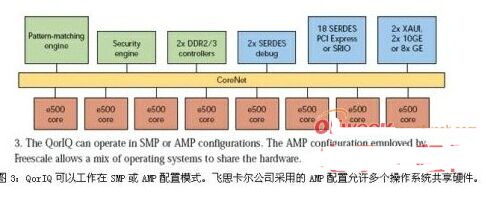
TI的OMAP 44xx平台整合了ARM Cortex-A9、PowerVR SGX 540 GPU、C64x DSP和图像信号处理器。每个内核有专门的功能,处理器之间的通信不是对称的。OMAP只工作在AMP模式,而P4080的内核是SMP系统,但也能够将内核划分为AMP模式。8内核芯片可以像8个独立内核那样运行,在许多配置中也可以联合起来使用(如一对双内核SMP子系统,或四个单内核子系统)。
OMAP和P4080在高层架构的主要区别是OMAP功能是固定的,内核针对各自的事务做了优化。这将使编程容易得多,因为可以根据匹配功能将应用程序划分到特定内核。
每个子系统的性能水平受架构的限制,但P4080可以调整划分方案,虽然划分通常是在系统启动时完成的。系统设计师可以调整P4080中内核的分配,前提是有足够多的内核。市场上也有内核数量较少的QorIQ平台,因此可以选用更经济的芯片。
IBM的Cell处理器填补了中间的空白。它采用了1个64位的Power内核和8个增效处理单元(SPE)。所有SPE都是相同的(每个有256KB的内存),它们工作在隔离状态,这与上述讨论的共享内存SMP系统有所不同。SPE内没有缓存,也不支持虚拟内存。
对软硬件设计来说,这种方式既有优点又有缺点。优点为是简化了硬件实现,但从多个角度看都使软件复杂化了。例如,内存管理受应用程序控制,就像内核间的通信一样。数据在能够操作之前必须要移进SPE的本地内存。完全开发Cell这样的架构很花时间,因为它们有别于更传统的SMP或AMP平台。多年来在像索尼的PlayStation 3这样的基于Cell的平台上所作的软件改进突显了编程技术和经验的变化。
GPU等专用处理器
改变编程技术是使用图形处理单元(GPU)是否成功的关健。来自ATI和Nvidia等公司的GPU在单个芯片内有上百个内核,这些GPU可以被整合进多芯片解决方案,向开发人员提供上千个内核。例如,集成进1U机箱的4个Nvidia Tesla T10就可以提供960个内核(图4)。
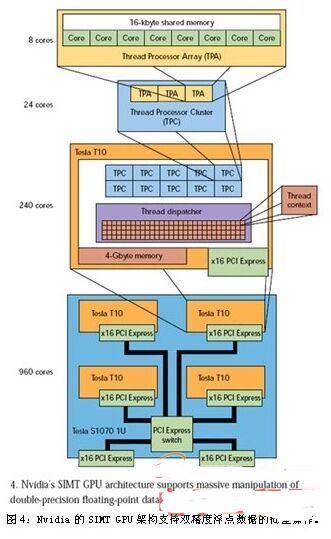
对Tesla或其它任何兼容的Nvidia GPU芯片进行编程都极具挑战性,但类似Nvidia的CUDA这样的架构或基于CUDA的运行时利用可以使工作变得更加轻松。部分挑战来自于 Nvidia GPU的单指令、多线程(SIMT)架构。与许多高性能系统一样,这种GPU喜欢处理数组数据。对许多应用来说这是不错的选择,但并非都是这样,这正是 GPU经常要与多内核CPU匹配的原因之一。




评论