CAN协议的错帧漏检率改进
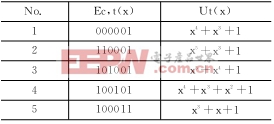
表1 错误序列尾部形式和漏错多项式Ut(x)
2.4 Ut的扩充形成Ec头部
在Ut中增加高于x5的项成为U,它不会影响Ec尾部的形式,但是它会增加错误序列的长度。由此U生成的Ec与Tx序列也将被漏检。Tx在数据域内不同位置的集合就构成了所有漏检实例。发生第一次bit错后并不立即开始TxRx位序的错位,要等到有填充位发生时才会有位序错。
2.5 构造出错实例Tx
以Ut= x4+x3+1为例,对应尾部第1位处出了传送错,Ut加上x6后有U=x6+x4+x3+1,计算得Ec=U×G=(1110,1111,0101,1010,0000,01),整个错误序列的长度为22位。该Ec确定头部出第1个传送错的位置是6,假定为漏删填充位错,则在尾部应取误删信息位错。假定在头部出现的是Tx送100000,在第6位处Rx收到的是1,出了第1个bit错,第7位Rx得到填充位1而未删去,Tx第7位可由Ec及Rx求得为0,然后逐位反推,得到Tx发生漏检错的实例,如图3所示。

图3 构造的会出漏检错的Tx实例
这个例子中Tx序列的长度为27 bit。此种长度的Tx可以有227种,每一种都可能出错,但重构出的这一种在特定位发生2个bit错时会漏检。这个Tx在别的位置发生bit错时,将可以检出错,因此它是一个可能被漏检的可疑实例。Tx头部共有4种可能:Tx=10000(0),10000(1),01111(1),01111(0)。(括号中的位在传送中出了错)。因此这几种可疑实例占可能Tx的2-25。可疑Tx在64 bit的数据域中会有64-27+1=38种位置。对头部Tx=100000和100001,其高4位可以与CAN的DLC重合,对Tx=011111和011110,其最高位可和DLC0重合,因此此种Tx实例在8字节数据域的帧中出现的可能数目是39种。于是这一种漏检实例有概率39×2-25=1.16×10-6。当误码率为0.02时,64 bit内出2个bit错的概率是(1-0.02)62×0.022=1.14×10-4,由这一个实例引起的CAN错帧漏检率就是1.32×10-10,已经大于Bosch的指标。考虑U中可增加的xk中k可由6一直到43,各种xk项有237=1.37×1011种组合,需要对每一种U进行计算,虽然它们的漏检实例概率不同,其增量还是很大的。还要考虑不同Ut的贡献,可见CAN错帧漏检率是非常大的。
2.6 计算结果
根据上述分析编制了在MATLAB中运行的程序pcan.m,在MATLAB中设置format long e格式,运行pcan(ber)即可得到不同误码率ber时的结果,如表2所列。
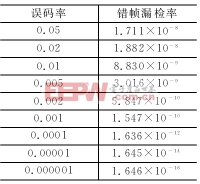
表2 典型的CAN漏检错帧概率
表中ber=0.02的错帧漏检率为1.882×10-8,而参考文献[2]在同样误码率下给出的漏检率是:低速系统4.7×10-14和高速系统8.5×10-14。可见差别极大。对500 kbps的系统,假定总线利用率为40%,帧长为135 bit,那么按这个结果,CAN系统将在9.96小时出1个漏检错帧。
3 改善错帧漏检率的方法
在本文的分析中可以见到,由于填充位规则需要收发同步执行,不同步时会极大干扰CRC校验,例如CRC校验本来可以将所有奇数个错检测出的,小于5位的多bit错是可以检测出的,但只要有了成对的填充位错位,增加的奇数个错也可以是漏检的,增加的多bit错也可以是漏检的,如图4所示。
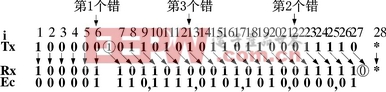
图4 有多位错的例子
漏检错的根源是CAN的CRC在执行填充位规则前生成,最根本的解决办法是像参考文献[3]指出的那样,要把CRC校验放在执行填充位规则之后。但是这样作就会根本修改CAN协议,在已经大量应用的情况下如何作到的改进前后的兼容性是个艰难的课题。作为局部的改正,参考文献[3]建议加附加的检验。在数据域添加一个新的不同的CRC检验时,根据本文的分析方法,当误差多项式Ec是这个新CRC和CAN的CRC的公倍数时,仍然可以构造出漏检的实例,并计算出新条件下的漏检错帧概率。例如采用8位的DARC8生成多项式x8+x5+x4+x3+1,它不含x+1因子,所以与CAN生成多项式的最小公倍数构成的漏错多项式Ec将有24阶,此时如2.5节所分析的那样,总帧数将增大28倍,而漏检帧数不变,漏检率就减少28。但是这种方法的缺点是不能实现自动报错,无法使节点间取得数据的一致性:有局部错的节点在添加上述措施后在收完帧后才能发现错,已无法要其他节点也丢弃该帧并要求自动重发。
本文建议采用7b/8b的编码办法,牺牲一些带宽,换取错帧漏检的避免。具体做法是在8b代码中选取不会发生填充位条件的部分,供原来7b编码使用。
其他的编码办法也是可行的,类似7b/8b的还有6b/7b、5b/6b、4b/5b,它们的区别是软件实现时的复杂程度以及开销占用数据域的多少,当用7b/8b时CAN可以每帧送7字节数据,而用4b/5b时每帧只能送6字节数据。
在附加数据域的软件补丁后,若发生在ID域和CRC域的填充位规则只有单边执行情况时,夹在它们中间的控制域就会左移或右移,帧长就会变大或变小。帧长的单位是1字节,它会使CRC域移入EOF域,CRC最多连续5位相同,就破坏了EOF的格式,或者EOF域移入CRC域,EOF的连续8位破坏了CRC的填充格式,所以此时单边执行填充位规则的错的后果是能被发现的。也就是说加软件补丁后不再有错帧漏检可能。
如果可疑Tx只发生在ID域,由于Tx有一个最短长度,相应于Ec,t= x3+x+1,这个长度是3+15+6=24位,所以对CAN2.0B的29位ID可能会出错,那么产生的后果就是接收节点收到的ID有错,这是一种假冒错(Masquerade)。在参考文献[6]中提到了CAN防止假冒错的方法,实际上将ID分为二部分,一部分是一个附加的CRC,只要这个CRC生成多项式与CAN的不同,就不会产生假冒ID通过接收滤的可能。







评论