基于优化GDTW-SVM算法的联机手写识别
摘要:基于高斯动态时间规整核函数(Gaussian Dynamic Time Warping kernel)的支持向量机(GDTW-SVM)在联机手写识别中有较高的识别率,但是存在计算复杂度高的问题。结合联机手写识别中特征向量的特点,提出了通过引入控制参数来约束GDTW最优对齐路径计算空间的方法,优化了GDTW核函数。然后,使用联机手写识别数据库UJIpenchar2进行实验。实验结果表明,该优化方法不仅可以减少支持向量的数目,而且提高了GDTW-SVM算法运行的效率。
关键词:手写识别;动态时间规整;支持向量机;核方法
0 前言
随着智能手机和平板电脑等无输入键盘电子设备的流行,联机手写识别的研究吸引了越来越多的关注。而手写签名验证和基于3D加速度传感器的姿态识别、手写识别等新应用形式的出现,也为联机手写识别的研究注入了新的活力。
支持向量机(Support Vector Machine,SVM)是在统计学习理论的基础上发展起来的新一代分类识别算法,使用核函数方法将非线性可分的特征向量映射到高维空间,计算最大化分类间隔的最优分类超平面。在文本分类、语音识别、手写识别、曲线拟合等领域,SVM已经有比较成熟的应用。但是,一般的核函数要求不同样本的特征向量的维数相同,限制了SVM在语音识别和联机手写识别领域的进一步发展。为此,Bahlmann等人使用弹性距离计算算法--DTW算法--构造了GDTW核函数,进而提出GDTW-SVM算法。GDTW-SVM的联机手写识别实验结果表明,GDT W-SVM取得了可媲美隐马尔科夫模型、神经网络等分类算法的识别率,并且与使用后来提出的基于其它弹性距离计算构造的核函数的SVM相比,性能不相伯仲。
本文结合GDTW核函数和联机手写识别样本的特征向量的特点,引入新的控制参数优化GDTW核函数的计算。实验结果表明,本文提出的优化方法不仅减少了支持向量的数目,而且提高了GDTW-SVM运行效率。
1 联机手写识别过程
1.1 联机手写识别流程介绍
联机手写识别的过程与通用模式识别的过程基本相同,由数据采集和预处理、特征提取、分类识别、后处理四个步骤组成。
在数据采集和预处理阶段,首先使用传感器采集原始物理信息,比较常见的是加速度、速度、位移、起笔和落笔;然后,对原始信息进行传感器矫正、去噪等预处理。
特征提取是手写识别的重要步骤之一,对分类器的设计和分类结果有着重要的影响,选择合适的特征不仅可以提高识别率,也可以节省计算存储空间、运算时间、特征提取费用。联机手写识别中比较常见特征提取方法有加速度、位移、DCT变换等。
分类识别是手写识别的核心阶段,大多数分类器在实际分类应用之前,需要使用训练样本对分类器进行训练,不断地修正特征提取方法和方案、分类器的判决规则和参数。目前,分类识别的训练阶段需要人工干预以达到最佳的识别率。
一些识别系统在分类识别之后使用后处理进一步提高识别率。例如,数字“1”和小写字母“1”在很多情况下难以分辨,但是在后处理阶段结合上下文信息,决定当前字符是数字“1”还是小写字母“1”。
1.2 联机手写识别实验
本文联机手写识别实验采用了Bahlmann等人和Bothe等人使用的方法。所使用的样本数据库是免费的联机手写数据库UJIpenchars2。它采用Toshiba M400 Tablet PC收集,包含60个书写者的共11640个手写样本。这些样本包含ASCII字符、拉丁字符和西班牙字符,而每个字符包含80个训练样本和140个测试样本。每个样本由一划或多划组成,数据库提供每个笔划的坐标序列。
坐标序列由等时间间隔采集的笔尖的水平坐标xi和垂直坐标yi组成。而在本文实验中,样本的坐标序列不经过任何去噪等预处理,直接对每个坐标点,使用字符的重心(μx,μy)和垂直坐标的方差σy计算列向量

式(1)中,ang是求虚数相角的函数。每个字符样本的特征向量是T=(t1,…,tNT),其中,NT是采集的坐标点数目,即特征向量的维数,每个字符样本的NT可以不相同。
本文的联机手写识别实验假设每个字符不需要分析其上下文即可完成识别,所以,特征提取之后使用本文所述的分类算法进行分类识别,并且将其输出结果作为最终识别结果,不经过任何后处理。

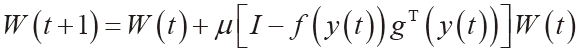

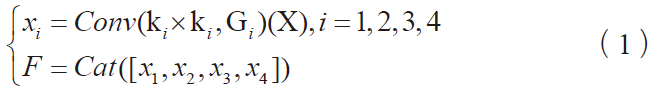

评论